Python爬取ajax加载的内容
在爬取某个实验室安全教育的练习的答案的时候,使用Python的requests库直接爬取该网页,结果与浏览器所看到内容不同。
import requests url='xxxx' #要爬取的网站,这里省略 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'} res = requests.get(url, headers=headers) res.encoding = 'utf-8' html = res.text with open('d:/html.txt','w',encoding='utf-8') as f:#写入文件 f.write(html)
爬取的结果如下图所示:
有些时候我们使用浏览器查看页面正常显示的数据与使用requests抓取页面html得到的结果不一致,这是因为requests获取的是原始的HTML文档,而浏览器中的页面是经过JavaScript处理数据后的结果。这些处理过的数据可能是通过Ajax加载的,可能包含HTML文档中,可能经过特定算法计算后生成的。可以看到试卷和题目是动态加载的,直接进行get获取不到。

对该网页进行抓包,在一个xhr里发现了所需要爬取的数据。
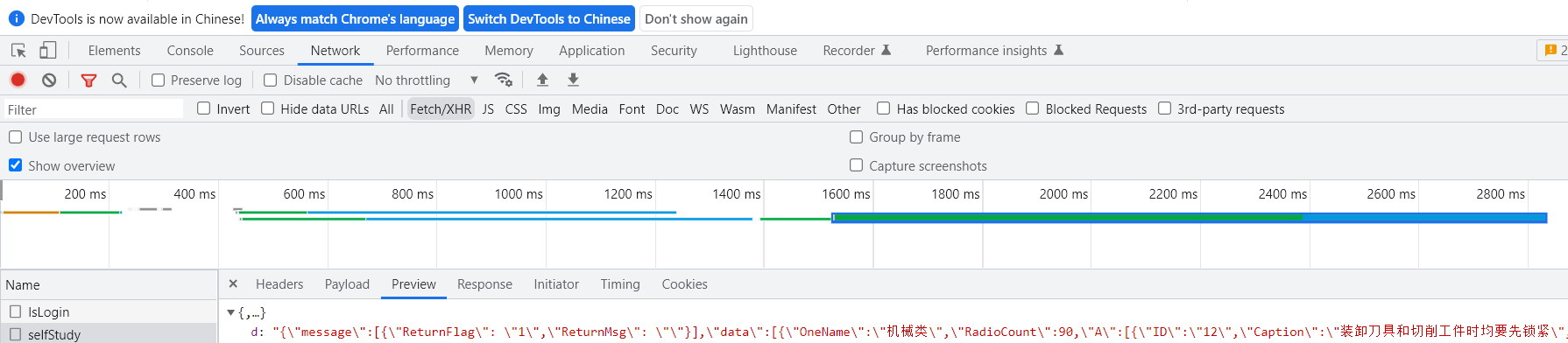
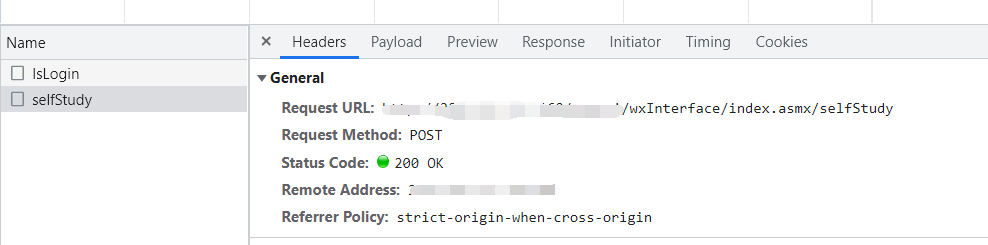
可以看到所需资源的url,请求方式是post。

重新改写代码
mport requests from bs4 import BeautifulSoup import json import jsonpath html_url = "xxxx" #这里改用新网址 payload = {'ID':'9','Type':'xx'} res = requests.post(html_url,data=payload) res.encoding = 'utf-8' html=res.text with open("d:/test.jtxt",'w',encoding='utf-8') as f: f.write(html)
结果如下图:

可以看到是XML格式, 使用bs4库的BeautifulSoup模块进行解析;string标签下又是json格式的数据,使用jsonpath提取json格式中的数据。
from bs4 import BeautifulSoup import json import jsonpath #解析XML soup = BeautifulSoup(html,"xml") s = soup.string #获取string标签下的内容 with open("d:/selfstudy.json",'w',encoding='utf-8') as f: f.write(soup.string)#将数据写入json文件 #加载json文件,返回值为python的字典对象 obj = json.load(open('d:/selfstudy.json','r',encoding='utf-8')) #获取题目和答案 caption = jsonpath.jsonpath(obj,'$..Caption')#jsonpath语法 $..+根节点名称 answer = jsonpath.jsonpath(obj,'$..AnSwer') with open('d:/safe.txt','w',encoding='utf-8') as f:#写入文件 for i in range(len(caption)):#标题和答案都是list类型且长度相等 f.write(caption[i]+'\t答案:'+answer[i]+'\n')
附上结果图:

代码汇总:
import requests from bs4 import BeautifulSoup import json import jsonpath html_url = "xxxx" payload = {'ID':'9','Type':'xx'} res = requests.post(html_url,data=payload) res.encoding = 'utf-8' html=res.text #解析XML soup = BeautifulSoup(html,"xml") with open("d:/selfstudy.json",'w',encoding='utf-8') as f: f.write(soup.string)#获取soup标签下的数据 #加载json文件 obj = json.load(open('d:/selfstudy.json','r',encoding='utf-8'))#转换为dict对象
#使用jsonpath读取根节点的数据 caption = jsonpath.jsonpath(obj,'$..Caption')#jsonpath语法 $..+根节点名称 answer = jsonpath.jsonpath(obj,'$..AnSwer') with open('d:/safe.txt','w',encoding='utf-8') as f:#写入文件 for i in range(len(caption)): f.write(caption[i]+'\t答案:'+answer[i]+'\n')
参考资料:
http://t.zoukankan.com/yunlongaimeng-p-9535386.html
https://blog.csdn.net/qq_34160248/article/details/121605538

 浙公网安备 33010602011771号
浙公网安备 33010602011771号