

TensorFlow的TPU/FPGA实现思路
TensorFlow的TPU/FPGA实现思路 第一稿 2020-12-02
一、 TensorFlow简介
TensorFlow是谷歌公司开发的一款基于张量运算的开源机器学习平台。与Caffe一样,它也拥有一个完整的生态系统,包含各种可视化工具,库以及社区支持。
TensorFlow本身对Python 、 C++、Java、JavaScript等 API有稳定支持。同时也支持GPU加速(CUDA指令集),只是这部分功能的稳定性是没有得到官方保证。
TensorFlow系统架构如下图所示
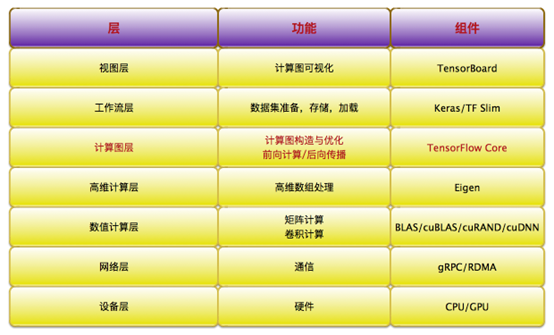
TensorFlow 基本架构
图中右下角是设备层,TensorFlow支持CPU、GPU等常规架构,以及谷歌公司自研的TPU(张量处理单元)架构。这其中CPU架构是最通用的,TPU架构的优势最为明显。
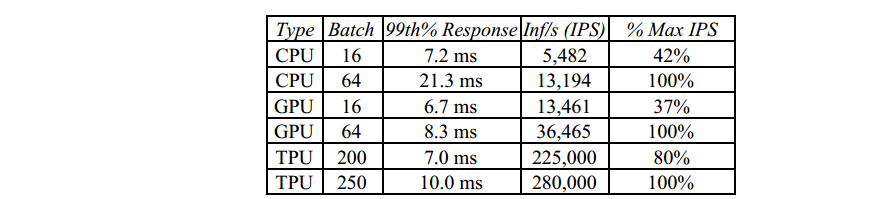
CPU,GPU,TPU推理速度比较
在推理速度和功耗方面,TPU都有很大的优势。
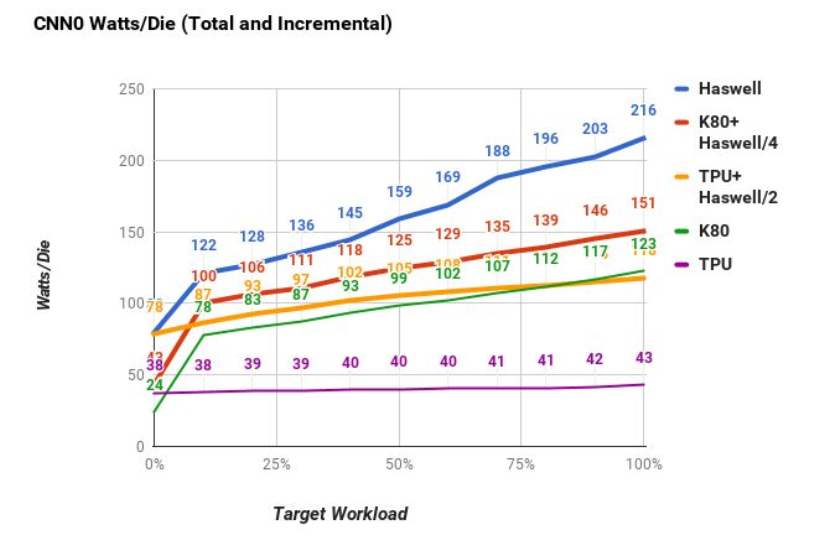
CPU,GPU,TPU芯片功耗比较
二、 TPU基本架构
TPU 基本架构,参考文献2
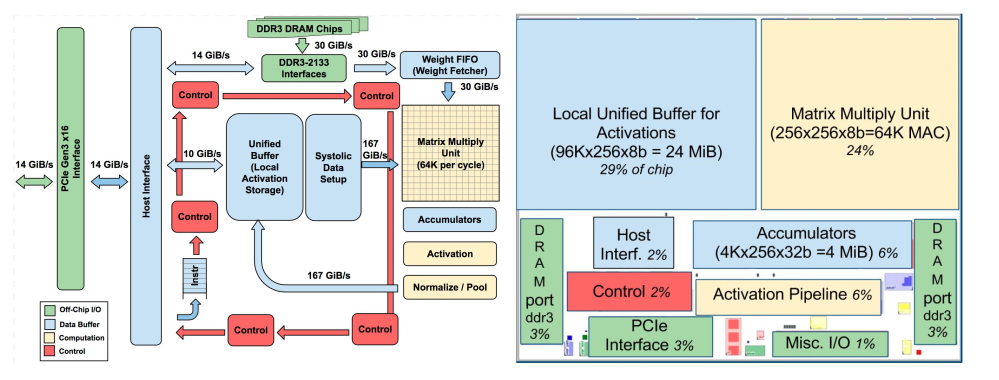
谷歌公开的TPU内部结构
左侧为TPU芯片完整结构图,包括PCIE接口,控制器单元,DDR3接口,权重值缓冲器(Weight FIFO),矩阵乘法器 MXU,联合缓冲区(Unified Buffer),归一化池(Normalize/Pool),激活函数(Activation),脉动数据生成区(Systolic Data Setup)等。
右侧为一个简化版的TPU,去掉了权重单元,一元化处理等操作。只保留了最核心的联合缓冲区和矩阵乘法器。
根据公开的专利文献【参考资料 7】,TPU的主要结构如下图所示。其包括DMA 引擎204,联合缓冲区208,动态存储器210,矩阵乘法器212,向量运算器214,指令序列生成器206,主机接口202。
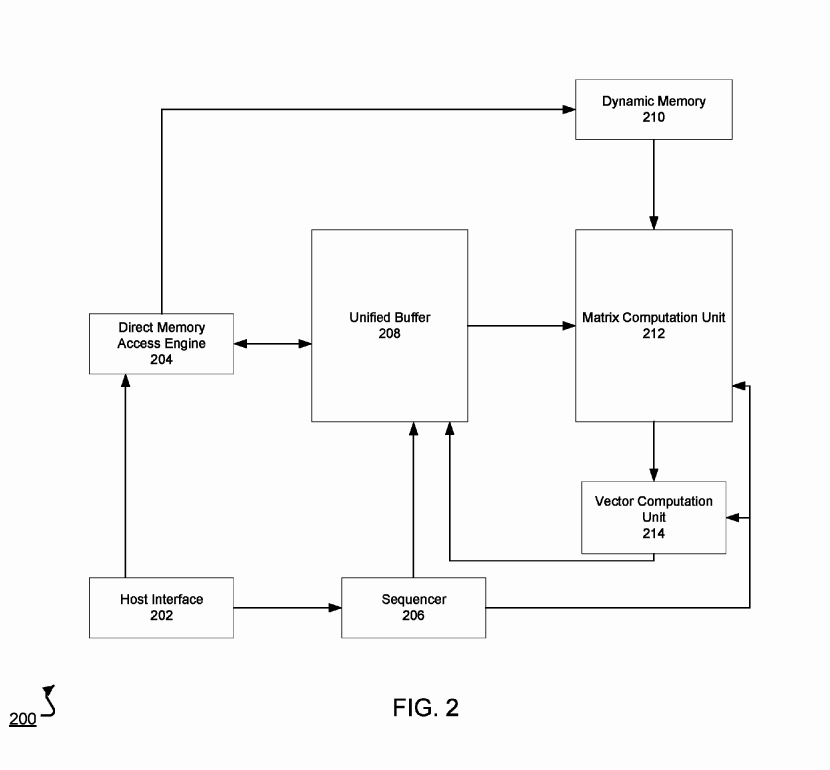
TPU主要结构
其单元功能大致如下
主机接口,实现外部主设备与TPU的高速通信,实现指令、网络数据和权重数据的加载及导出。
DMA引擎,实现主机接口对动态存储器和联合缓冲区内容的访问。
联合存储区内有三类数据,网络数据,指令序列,和权重数据。其功能主要是缓冲DMA引擎数据和矩阵运算器、向量运算器之间的数据。并对解码后的运算指令序列进行缓冲。
矩阵运算器(2-D)的主要功能是对权重数据和网络层数据进行运算。其组织形式及详细实施流程可参考文献5,即采用脉动阵列。
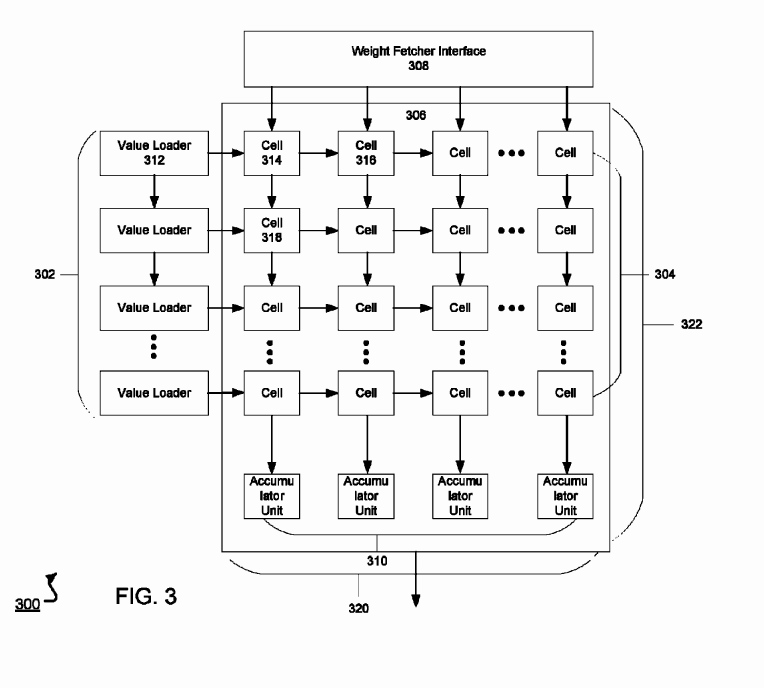
TPU 中 MXU脉动阵列示意图
向量运算器的主要功能是对输出进行归一化,输出到归一化池中。
指令序列生成器的主要功能是将网络层的指令进行解码翻译,生成更基础的操作指令,之后进行取指执行。
三、 FPGA实现TensorFlow API函数的思路
TensorFlow的所有API函数都是公开的,其基本功能及算法之代码都可以从公开渠道获得。在TensorFlow内部实现的任何网络,都是由这一个个函数组合而成。
以Dense函数为例,其操作流程如下图所示,其输入为[m x n]的一个二维矩阵A;函数调用Kernal方法再生成一个[n x k]的二维权重矩阵K;若是函数参数bias不为0,则还会生成一个[m x k]的偏置矩阵B;然后Dense函数会进行一次函数乘法和加法运算,得输出
Y= A * K + B (式1)
根据矩阵乘法和加法的定义,Dense函数总共有(m x n x k)乘法和(m x n x (k-1) + m x k)= (m x n x k + m x (k – n) )次加法。约等于(m x n x k)次乘加复合运算。
对于式1中的脉动乘法部分,若取k=m,如采用脉动阵列结构,则总延时为2*m-1+n个复合运算周期,至少需要max(m,n)个硬件复合单元【参考资料4】。
对于式中的加法部分,若采用p级流水线结构,即一次需要并发计算m*n/p个float加法。即需要m*n/p个浮点加法器,消耗p个加法周期。
若采用Xilinx Vivado的浮点库作为基本算子,设float复合运算y=A*B+C,需要消耗最高n0个DSP48E,延时最长为t_d0个时钟周期;float加法器y=A+B,需要消耗最高n1个DSP48E,延时最长为t_d1个时钟周期。
则Dense函数实际延时为
T_d = T_d0+T_d1 = (2*m-1+n)* t_d0+(p*t_d1)
个时钟周期,消耗
N=max(m,n)*n0+(m*n/p)*n1
个DSP48E单元。
若m=n=k=256,float IP核时钟频率为f MHz,则该Dense模块延时为
t_d = T_d/f (us)
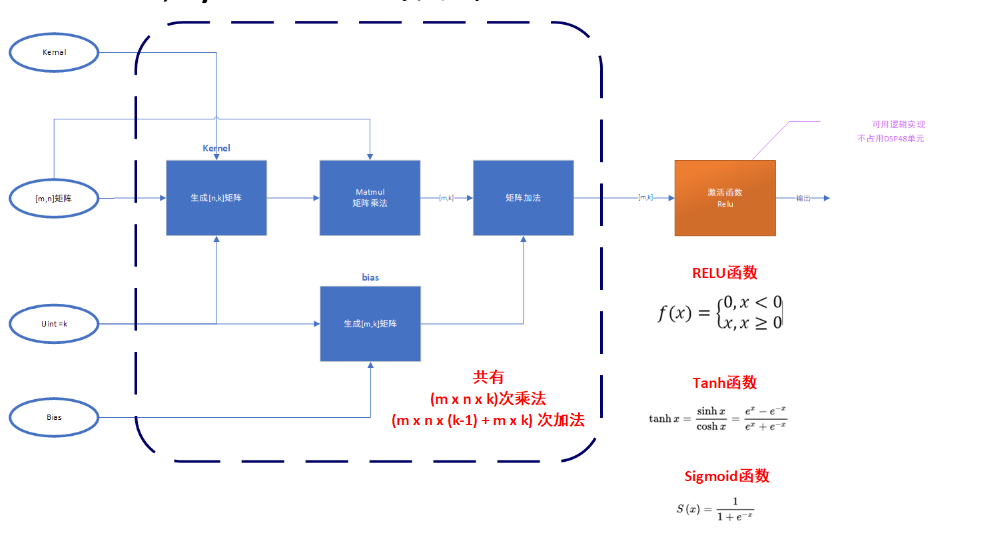
Dense函数执行流程
四、 Xilinx Vivado平台实现固定网络连接的方法
与TPU能动态实现网络连接,并与TensorFlow底层兼容不同。FPGA虽然也能在硬件层面进行加速,但需要对API接口进行改装及定义,以实现主机端和FPGA芯片逻辑的数据通信。
TPU芯片硬件仅支持256x256x8位精度运算,在某些场合下这很难满足要求。对于非重构的固定网络,以及更高精度的运算(如float32,甚至double型),FPGA是更好的选择。
同时,如在FPGA内部采用数据流和统一时钟,并辅以相应的时序约束。FPGA处理网络数据的延时时钟数是固定的,这一点比采用指令译码结构的TPU要强很多。
与此同时,如果FPGA容量足够其内部可以例化任意个MXU矩阵乘法单元,以实现大规模的并发计算,取得更低的处理延迟。
如下图所示,主机首先通过PCIE接口向FPGA下发网络层数据和配置数据。这些数据会被PCIE地址映射(桥接)单元分发到不同的AXI地址空间。不同的AXI地址空间具备不同的读写属性,以及参量含义;然后,AXI交换器会将PCIE桥接过来的数据总线进行扩展,以适应不同端口网络的通信需求;由于底层浮点运算单元 IP核的标准接口均为AXI-Stream格式,故需要通过AXI DMA模块将AXI 转换为AXI-Stream格式,并将读-写-控制数据流分开。
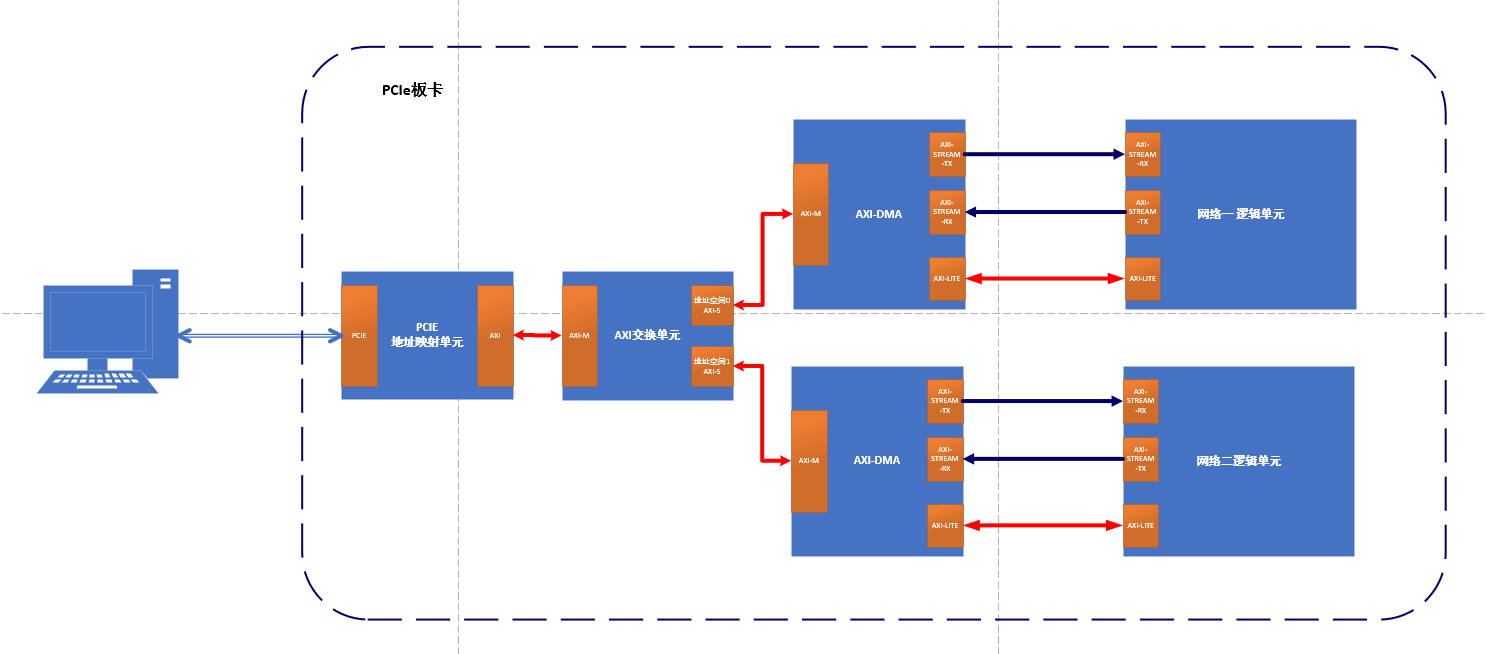
TensorFlow FPGA实现数据流基本框架
五、 TPU/FPGA局限性
TPU/FPGA芯片提供了一整套的网络加速环境,可逐条对主机端API函数进行翻译执行。但其仍具有一定局限性,具体表现在以下几个方面【参考资料3】,
- 需要频繁分支或逐项 (element-wise) 代数主导的线性代数程序。TPU 经过专门优化,可执行快速、庞大的矩阵乘法,因此不是由矩阵乘法主导的工作负载不太可能在 TPU 上有较好的表现(与其他平台相比)。
- 以稀疏方式访问内存的工作负载可能不适用于 TPU。
- 需要高精度算法的工作负载。例如,双精度算法不适用于 TPU。但FPGA无此局限性。
- 包含用 C++ 编写的自定义 TensorFlow 操作的神经网络工作负载。具体而言,主训练循环体中的自定义操作不适用于 TPU。
六、 小结
TensorFlow的硬件加速方式各有千秋,但均为辅助处理器,不具备通用性。以二维脉动矩阵乘法为核心,辅助控制和数据流接口,最终实现片内的高速大规模神经网络模拟。不同点在于,TPU功能更全,接口更完备,速度快但是精度低,且存在性能瓶颈;FPGA更加灵活,但是需要开发者自己定义数据接口,且需要较为丰富的逻辑开发经验。
七、 参考资料
1.https://blog.csdn.net/qq_20657717/article/details/82902868
2.https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf,谷歌关于TPU架构的公开论文
3.https://cloud.google.com/tpu/docs/tpus,谷歌关于TPU的文档
4.https://www.telesens.co/2018/07/30/systolic-architectures/, 脉动阵列架构详解
5.http://www.eecs.harvard.edu/~htk/publication/1982-kung-why-systolic-architecture.pdf,脉动阵列架构
6.http://chips.dataguru.cn/article-11106-1.html, 深入理解TPU脉动阵列架构
美国专利 US 9,710,748 B2,神经网络处理器
8. https://www.tensorflow.orTensorFlow,TensorFlow 官方网站
9.https://www.xilinx.com/xsw/floating_point,Xilinx浮点库7.1
10.https://zhuanlan.zhihu.com/p/51281659 TPU芯片初探
