PCA 主成分分析
一、概述
PCA(Principal Component Analysis) 常用于高维数据的降维,可用于提取数据的主要特征分量。
1.1 内积
两个向量的 A 和 B 内积我们知道形式是这样的:
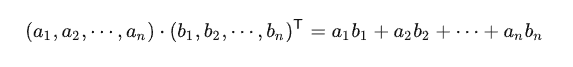
内积运算将两个向量映射为实数,其计算方式非常容易理解,但我们无法看出其物理含义。接下来我们从几何角度来分析,为了简单起见,我们假设 A 和 B 均为二维向量,则:
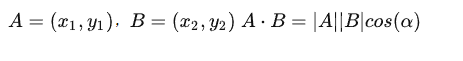
如果假设 B 的模为 1,即让 |B|=1 ,那么就变成了:
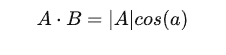
也就是说:A 与 B 的内积值等于 A 向 B 所在直线投影的标量大小。
1.2 基
基是向量数字定义的参照物,我们要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。
为了方便求坐标,我们希望这组基向量模长为 1。因为向量的内积运算,当模长为 1 时,内积可以直接表示投影。
然后还需要这组基是线性无关的,我们一般用正交基,非正交的基也是可以的,不过正交基有较好的性质。
(1,0)和(0,1)叫做二维空间的一组基。
1.3 基变换
数据与一个基做内积运算,结果作为第一个新的坐标分量,然后与第二个基做内积运算,结果做第二个新的坐标分量。
向量(3,2)做基变换:
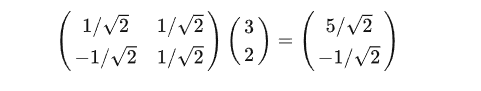
通用形式为:
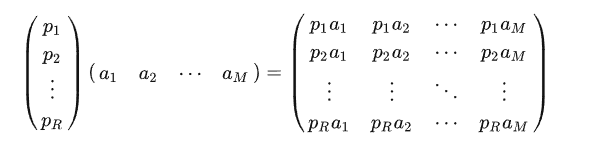
其中 pi 是一个行向量,表示第 i 个基, aj 是一个列向量,表示第 j 个原始数据记录。实际上也就是做了一个向量矩阵化的操作。
上述分析给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列向量 ai 变换到左边矩阵中以每一行行向量为基所表示的空间中去。也就是说一个矩阵可以表示一种线性变换。
1.4 协方差矩阵





1.5 简单案例

二、参数
2.1 PCA参数列表



2.2 PCA属性列表

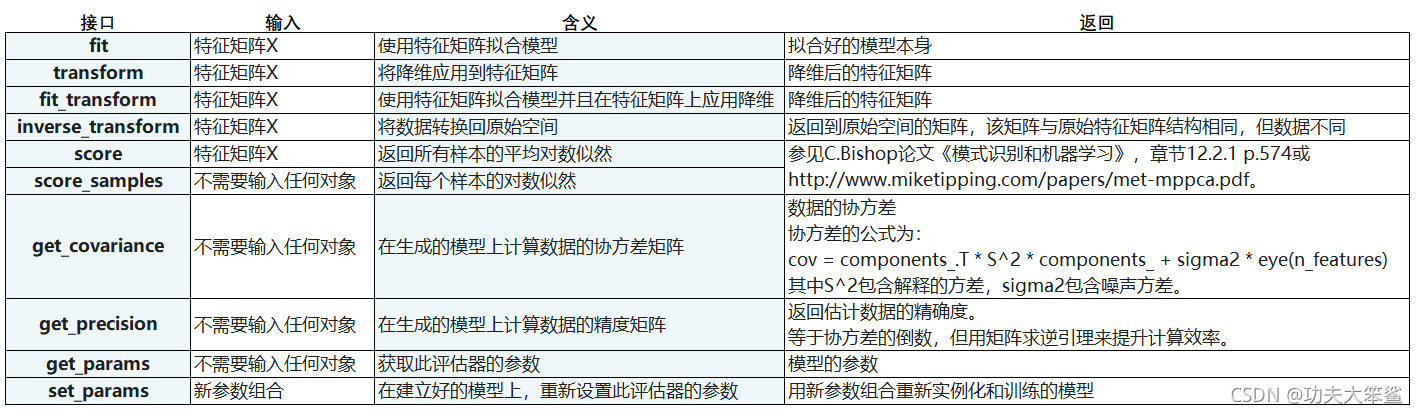
2.3 PCA接口列表
三、 代码
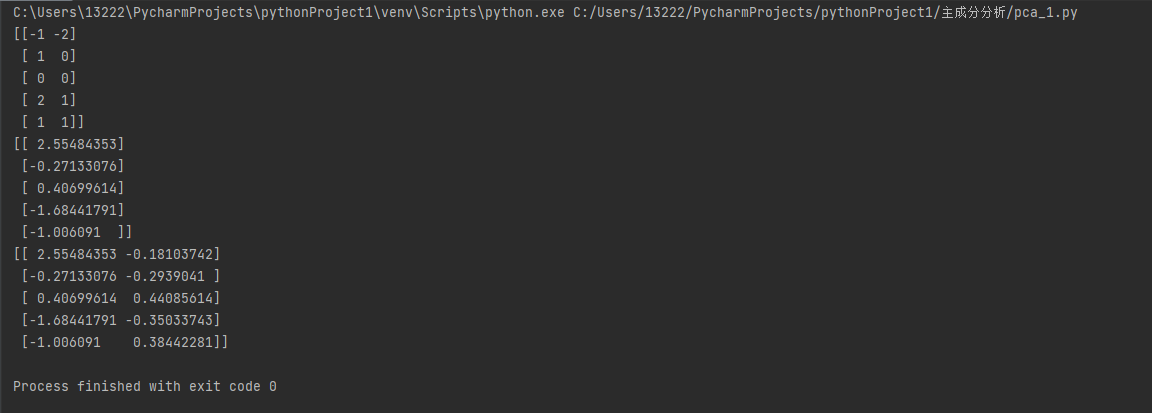
import numpy as np from sklearn.decomposition import PCA x1 = [-1, 1, 0, 2, 1] x2 = [-2, 0, 0, 1, 1] X = np.array([x1, x2]).transpose() print(X) pca = PCA(n_components=1) # 原数据是二维的,所以我想降成一维 pca.fit(X) X_t = pca.transform(X) print(X_t) pca = PCA(n_components=2) # 转换成2维看一下 pca.fit(X) X_t = pca.transform(X) print(X_t)
四、优缺点
4.1 优点
- 缓解维度灾难:PCA 算法通过舍去一部分信息之后能使得样本的采样密度增大(因为维数降低了),这是缓解维度灾难的重要手段;
- 降噪:当数据受到噪声影响时,最小特征值对应的特征向量往往与噪声有关,将它们舍弃能在一定程度上起到降噪的效果;
- 特征独立:PCA 不仅将数据压缩到低维,它也使得降维之后的数据各特征相互独立;
4.2 缺点
- 过拟合:PCA 保留了主要信息,但这个主要信息只是针对训练集的,而且这个主要信息未必是重要信息。有可能舍弃了一些看似无用的信息,但是这些看似无用的信息恰好是重要信息,只是在训练集上没有很大的表现,所以 PCA 也可能加剧了过拟合;
- 主成分特征维度的含义具有模糊性,解释性差。(我们最多可以理解成主成分只是由原来的坐标维度线性相加的结果,但加出来之后它到底是啥就不好说了)
参考:
https://zhuanlan.zhihu.com/p/77151308
https://blog.csdn.net/m0_50572604/article/details/121055880

 浙公网安备 33010602011771号
浙公网安备 33010602011771号