DBSCAN
一、概述
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是Martin Ester, Hans-PeterKriegel等人于1996年提出的一种基于密度的空间的数据聚类方法,算法将具有足够密度区域作为距离中心,不断生长该区域,算法基于一个事实:一个聚类可以由其中的任何核心对象唯一确定。该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。该方法能在具有噪声的空间数据库中发现任意形状的簇,可将密度足够大的相邻区域连接,能有效处理异常数据,主要用于对空间数据的聚类。
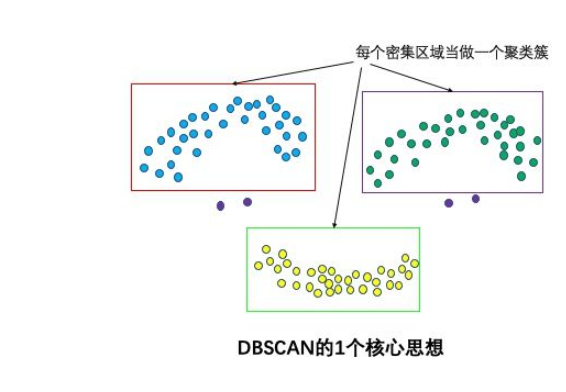
1.1 核心思想
该核心思想是基于密度。
基于密度:通过计算样本的紧密程度来实现对样本类别的划分,在样本空间中聚集密度大的就会划分到一个类别中。
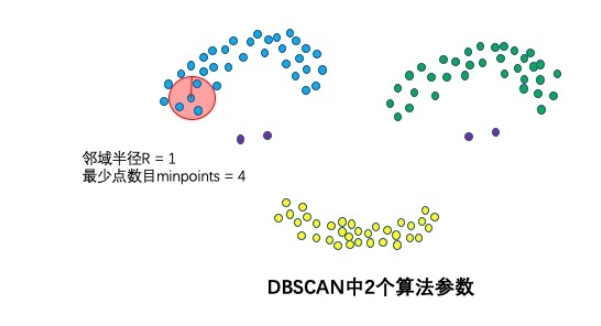
1.2 两个算法参数
- 邻域半径R
- 最少点数目minpoints
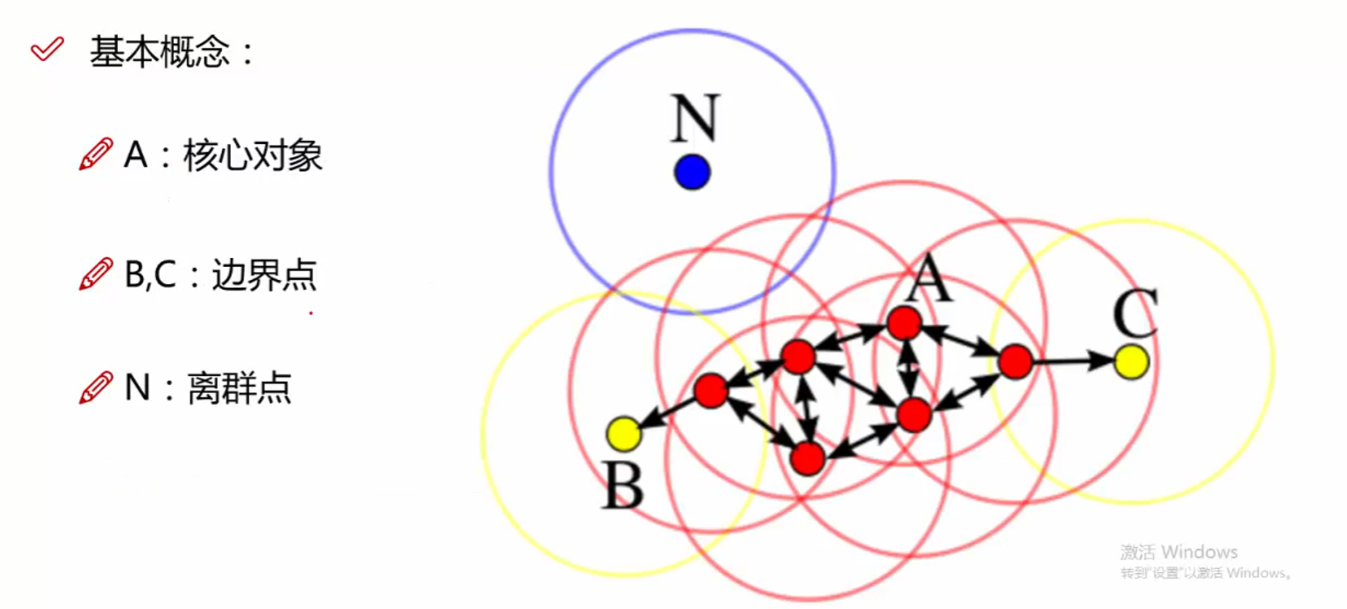
1.3 三个点
- 核心点:也叫核心对象,邻域半径R内样本点的数量大于等于minpoints的点叫做核心点
- 边界点:不属于核心点但在某个核心点的邻域内的点叫做边界点
- 噪声点:也叫离群点,既不是核心点也不是边界点的是噪声点
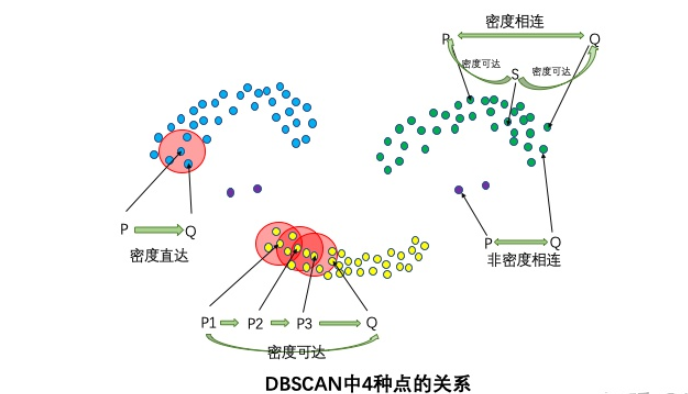
1.4 四种关系
- 密度直达:如果P为核心点,Q在P的R邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度直达,那么Q到P不一定密度直达。
- 密度可达:如果存在核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn到Q密度直达,则P1到Q密度可达。密度可达也不具有对称性。
- 密度相连:如果存在核心点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连。密度相连的两个点属于同一个聚类簇。
- 非密度相连:如果两个点不属于密度相连关系,则两个点非密度相连。非密度相连的两个点属于不同的聚类簇,或者其中存在噪声点。
二、算法流程
可以查看网址:https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
2.1 基本逻辑


2.2 算法实例
下面给出一个样本数据集,如表 1 所示,并对其实施 DBSCAN 算法进行聚类,取 Eps=3,MinPts=3。
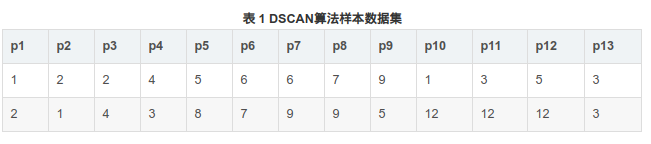
数据集中的样本数据在二维空间内的表示下图 所示。
第一步,随机扫描数据集的样本点,假设取到 p1(1,2)。
1)计算 p1 的邻域,计算出每一点到 p1 的距离,如 d(p1,p2)=sqrt(1+1)=1.414。
2)根据每个样本点到 p1 的距离,计算出 p1 的 Eps 邻域为 {p1,p2,p3,p13}。
3)因为 p1 的 Eps 邻域含有 4 个点,大于 MinPts(3),所以,p1 为核心点。
4)以 p1 为核心点建立簇 C1,即找出所有从 p1 密度可达的点。
5)p1 邻域内的点都是 p1 直接密度可达的点,所以都属于C1。
6)寻找 p1 密度可达的点,p2 的邻域为 {p1,p2,p3,p4,p13},因为 p1 密度可达 p2,p2 密度可达 p4,所以 p1 密度可达 p4,因此 p4 也属于 C1。
7)p3 的邻域为 {p1,p2,p3,p4,p13},p13的邻域为 {p1,p2,p3,p4,p13},p3 和 p13 都是核心点,但是它们邻域的点都已经在 Cl 中。
8)P4 的邻域为 {p3,p4,p13},为核心点,其邻域内的所有点都已经被处理。
9)此时,以 p1 为核心点出发的那些密度可达的对象都全部处理完毕,得到簇C1,包含点 {p1,p2,p3,p13,p4}。
第二步,再次随机扫描数据集的样本点,取到p5(5,8)。
1)计算 p5 的邻域,计算出每一点到 p5 的距离,如 d(p1,p8)-sqrt(4+1)=2.236。
2)根据每个样本点到 p5 的距离,计算出p5的Eps邻域为{p5,p6,p7,p8}。
3)因为 p5 的 Eps 邻域含有 4 个点,大于 MinPts(3),所以,p5 为核心点。
4)以 p5 为核心点建立簇 C2,即找出所有从 p5 密度可达的点,可以获得簇 C2,包含点 {p5,p6,p7,p8}。
第三步,继续随机扫描数据集的样本点,取到 p9(9,5)。
1)计算出 p9 的 Eps 邻域为 {p9},个数小于 MinPts(3),所以 p9 不是核心点。
2)对 p9 处理结束。
第四步,继续随机扫描数据集的样本点,取到 p10(1,12)。
1)计算出 p10 的 Eps 邻域为 {p10,pll},个数小于 MinPts(3),所以 p10 不是核心点。
2)对 p10 处理结束。
第五步,继续随机扫描数据集的样本点,取到 p11(3,12)。
1)计算出 p11 的 Eps 邻域为 {p11,p10,p12},个数等于 MinPts(3),所以 p11 是核心点。
2)从 p12 的邻域为 {p12,p11},不是核心点。
3)以 p11 为核心点建立簇 C3,包含点 {p11,p10,p12}。
第六步,继续扫描数据的样本点,p12、p13 都已经被处理过,算法结束。
三、python代码
import pandas as pd from sklearn.cluster import DBSCAN import matplotlib.pyplot as plt p = ['p1', 'p2', 'p3', 'p4', 'p5', 'p6', 'p7', 'p8', 'p9', 'p10', 'p11', 'p12', 'p13', 'p14'] x1 = [1, 2, 2, 4, 5, 6, 6, 7, 8, 1, 3, 5, 3, 15] x2 = [2, 1, 4, 3, 8, 7, 9, 9, 5, 12, 12, 12, 3, 15] #(15, 15) 为在原有基础上设计的离群点 X = pd.DataFrame(data={'x1': x1, 'x2': x2}) dbscan = DBSCAN(eps=3, min_samples=3) dbscan.fit(X) label= dbscan.labels_ # 分群后的标签 df = pd.DataFrame(data={'p':p, 'x1':x1, 'x2':x2, 'label':label }) print(df) # 因为已经知道加上离群点分了四个类,那么画出来看一下 for index, row in df.iterrows(): label = row['label'] x1 = row['x1'] x2 = row['x2'] if label == 0: plt.scatter(x1,x2, c='r') elif label == 1: plt.scatter(x1, x2, c='b') elif label == 2: plt.scatter(x1, x2, c='g') elif label == -1: plt.scatter(x1, x2, c='k') plt.show()
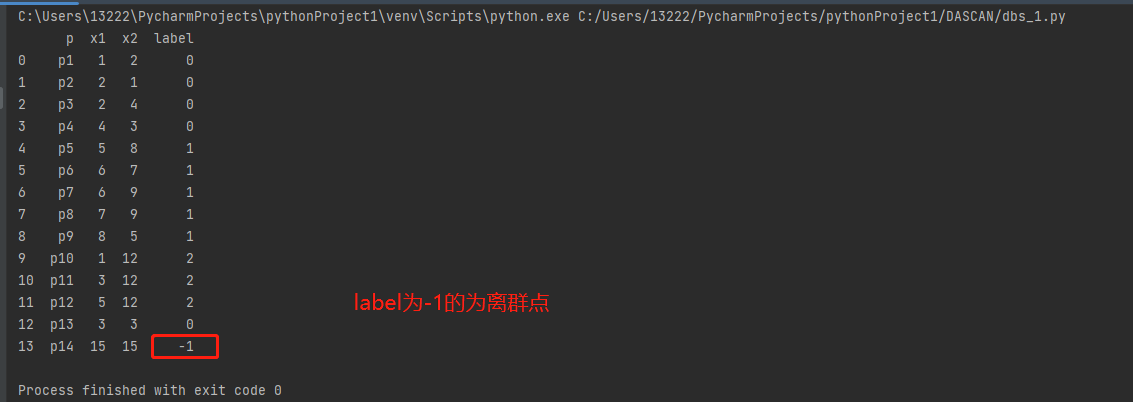
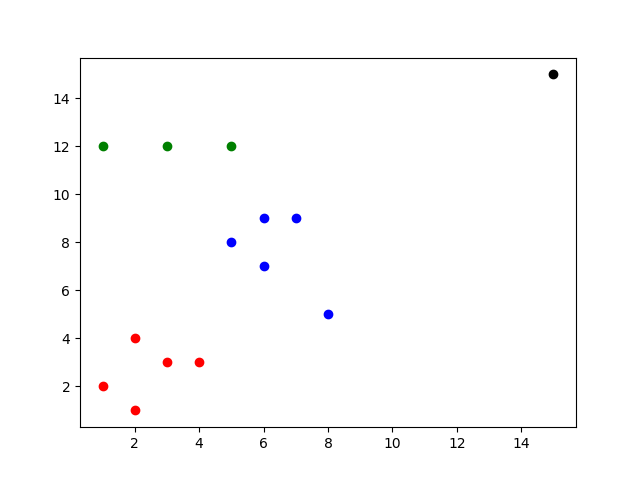
四、优缺点
4.1 优点
-
可以对任意形状的稠密数据集进行聚类,而 k-means 之类的聚类算法一般只适用于凸数据集。
-
可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
-
聚类结果没有偏倚,而 k-means 之类的聚类算法的初始值对聚类结果有很大影响。
4.2 缺点
- 样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用 DBSCAN 算法一般不适合。
- 样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的 KD 树或者球树进行规模限制来进行改进。
- 调试参数比较复杂时,主要需要对距离阈值 Eps,邻域样本数阈值 MinPts 进行联合调参,不同的参数组合对最后的聚类效果有较大影响。
- 对于整个数据集只采用了一组参数。如果数据集中存在不同密度的簇或者嵌套簇,则 DBSCAN 算法不能处理。为了解决这个问题,有人提出了 OPTICS 算法。
- DBSCAN 算法可过滤噪声点,这同时也是其缺点,这造成了其不适用于某些领域,如对网络安全领域中恶意攻击的判断。
参考:https://blog.csdn.net/hansome_hong/article/details/107596543

 浙公网安备 33010602011771号
浙公网安备 33010602011771号