Bagging集成学习
一、概述
1.1 基本原理
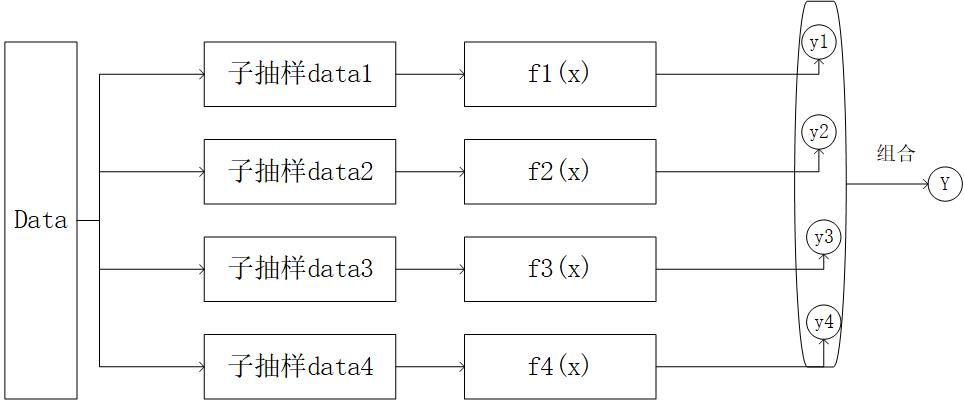
通过上图我们知道,bagging是每个弱学习器之间的并行计算最后综合预测,各个弱学习器之间没有依赖关系,
在训练集到子训练器的过程叫做“子抽样”
子抽样:比如有750个样本,每次抽取500个,抽取四次。第一次随机抽取500个,第二次也抽取500个,第一次与第二次抽取的数据有部分重合。
可以看成第一次抽取完成后,将样本放回,第二次在随机抽取。每次抽取的每个样本概率相同。
注意:有1000个样本,训练集有750个。那么子训练器中的样本不可以死超过750个,否则会报错。也不要等于750个,否则每次抽取的样本都一样。
1.2 参数
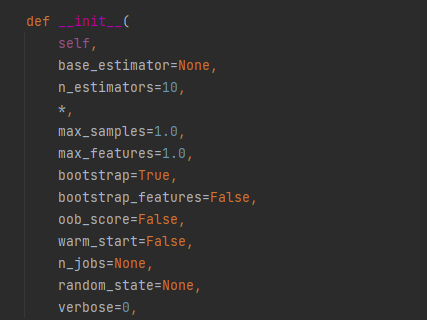
max_samples : int或float,可选(默认值= 1.0)从X抽取以训练每个基本估计量的样本数。
-
如果为int,则抽取样本 max_samples
-
如果float,则抽取本 max_samples * X.shape[0]
max_features : int或float,可选(默认值= 1.0)从X绘制以训练每个基本估计量的要素数量。
-
如果为int,则绘制特征 max_features
-
如果是浮动的,则绘制特征 max_features * X.shape[1]
1.3 步骤
- 从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
- 每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
- 对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
二、代码演示
import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier ''' 制作样本数据,产生的结果为一个简单的样本数据集,用于可视化聚类算法和分类算法 1. n_samples : 整数型, 可选,默认为100 总的产生的样本点的数量 2. shuffle : 布尔型,可选填 (默认为True) 是否对样本进行重新洗牌 3. noise : 浮点型 or None型 (默认为None) 加到数据里面的高斯噪声的标准差 ''' X, y = datasets.make_moons(n_samples=1000, shuffle=True, noise=0.3, random_state=2) plt.scatter(X[y == 0, 0], X[y == 0, 1]) plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.show() # 划分数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=2) dt_clf = DecisionTreeClassifier(max_depth=3, min_samples_leaf=2, random_state=2) bag_clf = BaggingClassifier(base_estimator=dt_clf, n_estimators=400, max_samples=500, random_state=2) bag_clf.fit(X_train, y_train) print('bagging的训练集分数:{a:.2%}, 测试集分数:{b:.2%}'. format(a=bag_clf.score(X_train, y_train), b=bag_clf.score(X_test, y_test)))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号