交叉验证与网格搜索
一、概述
1.1 为什么用网格搜索与交叉验证
在机器学习中,有大量的超参数需要指定;如果超参数指定不合适,则会出现过拟合和欠拟合。
而指定超参数,一种方法是凭经验;一种方法是穷举。
网格搜索可以尝试制定的每一种超参数,表现最好的参数就是最终的结果。但是比较耗时。
二、 网格搜索
2.1 estimator中未嵌套estimator
类似笛卡尔积一样,将所有参数进行组合一遍。
import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import GridSearchCV ''' 制作样本数据,产生的结果为一个简单的样本数据集,用于可视化聚类算法和分类算法 1. n_samples : 整数型, 可选,默认为100 总的产生的样本点的数量 2. shuffle : 布尔型,可选填 (默认为True) 是否对样本进行重新洗牌 3. noise : 浮点型 or None型 (默认为None) 加到数据里面的高斯噪声的标准差 ''' X, y = datasets.make_moons(n_samples=1000, shuffle=True, noise=0.3, random_state=2) plt.scatter(X[y == 0, 0], X[y == 0, 1]) plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.show() # 划分数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=2) dt_clf = DecisionTreeClassifier() para_grid = {'max_depth': [3, 4, 5, 6],'min_samples_leaf': [2, 3, 4, 5, 6],'random_state': [2]} gc = GridSearchCV(estimator=dt_clf, param_grid=para_grid, cv=3) gc.fit(X_train, y_train) print(gc.best_params_) print(gc.best_score_)
以上面的决策树为例,超参数有:
para_grid = {'max_depth': [3, 4, 5, 6],'min_samples_leaf': [2, 3, 4, 5, 6],'random_state': [2]}
max_depth有4个参数
min_samples_leaf有5个参数
random_state有1个参数。
那么就有4*5*1=20中组合方式。
会对着20中组合分别进行训练求解,然后算出最优的解。
2.1 estimator中嵌套estimator
import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import GridSearchCV X, y = datasets.make_moons(n_samples=1000, shuffle=True, noise=0.3, random_state=2) plt.scatter(X[y == 0, 0], X[y == 0, 1]) plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.show() # 划分数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=2) # 注意参数书写模式,带base_estimator__是DecisionTreeClassifier(),不带base_estimator__是GridSearchCV()参数 param_grid = {'base_estimator__max_depth': [3, 4], 'base_estimator__min_samples_leaf': [2, 3], 'base_estimator__random_state': [2], 'n_estimators':[50,100,150,200]} dt_clf = DecisionTreeClassifier() gc_clf = GridSearchCV(BaggingClassifier(DecisionTreeClassifier()),param_grid=param_grid) gc_clf.fit(X_train, y_train) print(f'最佳模型与最优参数:{gc_clf.best_estimator_}') print(f'最佳分数:{gc_clf.best_score_}')
BaggingClassifier(DecisionTreeClassifier()) BaggingClassifier中嵌套了DecisionTreeClassifier,那么param_grid中就需要指出两种参数的不同,
带base_estimator__是DecisionTreeClassifier(),不带base_estimator__是GridSearchCV()参数
三、 交叉验证
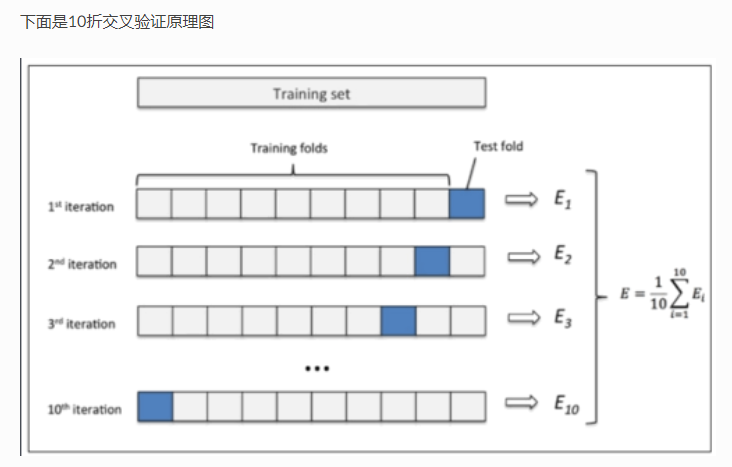
gc = GridSearchCV(estimator=dt_clf, param_grid=para_grid, cv=3)
参数cv即为折数。
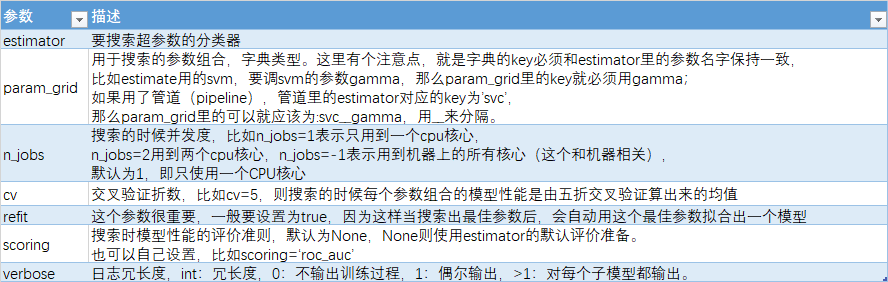
四、参数
五、常用属性


 浙公网安备 33010602011771号
浙公网安备 33010602011771号