集成学习之VotingClassifier
一、概述
同一个问题可能通过不同的机器学习模型来解决,那么哪个解决方案会更客观呢?
这种集成算法一般应用与分类问题。思路很简单。假如有5种机器学习模型来进行分类预测,就拥有5个预测的结果集,那么这5种模型,一种模型一票。然后遵循少数服从多数原则。
投票分类器有硬投票和软投票两种,硬投票是对结果进行投票,比较票数的多少,软投票是对多种结果的预测正确率,对正确率比大小。
二、参数
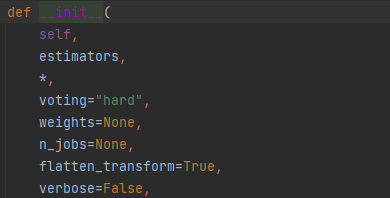
2.1 voting
-
Hard Voting Classifier:根据少数服从多数来定最终结果;
-
Soft Voting Classifier:将所有模型预测样本为某一类别的概率的平均值作为标准,概率最高的对应的类型为最终的预测结果;
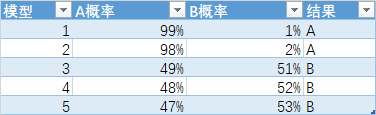

有五个模型,最后得出结果为:分类为A类有2票,分类为B列有3票。如果按照hard模型,则判定为B类。
但是A类的五种模型的平均概率为68%, B类的五种模型的平均概率为32%,如果按照soft模型,则判定为A类。
补充:对于hard形式,如果票数2比2打平了,会将结果都判定给其中的一个,所有尽量不要用偶然的票数。
三、案列
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.ensemble import VotingClassifier ''' 制作样本数据,产生的结果为一个简单的样本数据集,用于可视化聚类算法和分类算法 1. n_samples : 整数型, 可选,默认为100 总的产生的样本点的数量 2. shuffle : 布尔型,可选填 (默认为True) 是否对样本进行重新洗牌 3. noise : 浮点型 or None型 (默认为None) 加到数据里面的高斯噪声的标准差 ''' X, y = datasets.make_moons(n_samples=1000, shuffle=True, noise=0.3, random_state=2) plt.scatter(X[y == 0, 0], X[y == 0, 1]) plt.scatter(X[y == 1, 0], X[y == 1, 1]) plt.show() # 划分数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=2) # 采用逻辑回归 log_clf = LogisticRegression() log_clf.fit(X_train, y_train) y_predict_log = log_clf.predict(X_test) print('逻辑回归的训练集分数:{a:.2%}, 测试集分数:{b:.2%}'. format(a=log_clf.score(X_train, y_train), b=log_clf.score(X_test, y_test))) # 采用KNN knn_clf = KNeighborsClassifier(n_neighbors=5) knn_clf.fit(X_train, y_train) y_predict_knn = knn_clf.predict(X_test) print('KNN的训练集分数:{a:.2%}, 测试集分数:{b:.2%}'. format(a=knn_clf.score(X_train, y_train), b=knn_clf.score(X_test, y_test))) # 采用决策树 dt_clf = DecisionTreeClassifier(random_state=1) dt_clf.fit(X_train, y_train) y_predict_dt = dt_clf.predict(X_test) print('决策树的训练集分数:{a:.2%}, 测试集分数:{b:.2%}'. format(a=dt_clf.score(X_train, y_train), b=dt_clf.score(X_test, y_test))) # 采用支持向量机 svc_clf = SVC(C=1.0, kernel='rbf', degree=3, gamma='scale') svc_clf.fit(X_train, y_train) y_predict_svc = svc_clf.predict(X_test) print('逻辑回归的训练集分数:{a:.2%}, 测试集分数:{b:.2%}'. format(a=svc_clf.score(X_train, y_train), b=svc_clf.score(X_test, y_test))) # 手动实现集成学习 # 2:2打平,则y判定给0 y_predict_s = np.array((y_predict_log+y_predict_knn+y_predict_dt+y_predict_svc) >= 3, dtype=np.int_) # 创建集成学习对象 voting_clf = VotingClassifier(estimators=[('log_clf', LogisticRegression()), ('knn_clf', KNeighborsClassifier(n_neighbors=5)), ('dt_clf', DecisionTreeClassifier(random_state=1)), # 如果SVC的voting = 'soft',则需要加参数probability=True ('svc', SVC(C=1.0, kernel='rbf', degree=3, gamma='scale'))], voting='hard') voting_clf.fit(X_train, y_train) y_predict_vot = voting_clf.predict(X_test) print(f'支持向量机分数:{voting_clf.score(X_test, y_test):.2%}') print(f'手动支持向量机分数:{accuracy_score(y_test, y_predict_s):.2%}') # 查看结果 df = pd.DataFrame(data={'y_predict_log': y_predict_log, 'y_predict_knn': y_predict_knn, 'y_predict_dt': y_predict_dt, 'y_predict_svc': y_predict_svc, 'y_predict_s': y_predict_s, 'y_predict_vot': y_predict_vot}) df.to_excel('../data/vote.xlsx', index=False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号