SVM向量机
一、基本概念
1.1 支持向量机
支持向量机(Support Vector Machine,SVM) 是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。
体来说就是在线性可分时,在原空间寻找两类样本的最优分类超平面。
在线性不可分时,加入松弛变量并通过使用非线性映射将低维度输入空间的样本映射到高维度空间使其变为线性可分,这样就可以在该特征空间中寻找最优分类超平面。
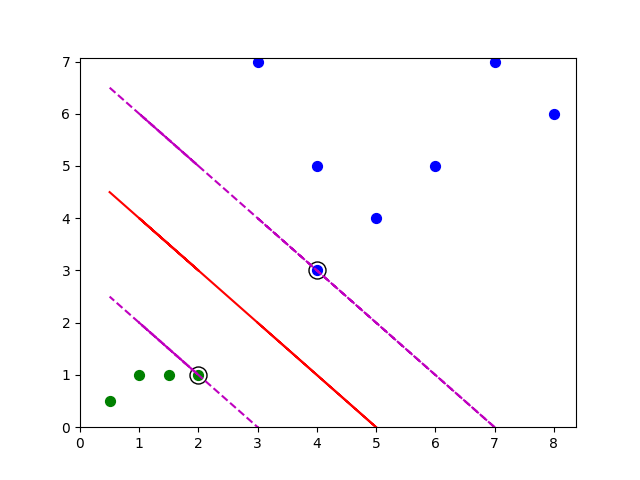
1.2 线性可分
对于二维空间(平面)的二分类问题,有那么一条直线可以把正负实例点完全分开,这些数据就是线性可分的;
而线性不可分就是找不到一条直线可以把正负实例点完全分开。
如上图蓝色点与绿色点线性可分
1.3 超平面
实例点从二维空间转移到三维甚至多维空间中,这个时候不能再用直线划分,而需要用平面去划分数据集,这个平面就称为超平面。
红色实线就是平面,在二维平面中就是一条直线。
1.4 支持向量
在线性可分的情况下,训练数据集的样本点与分离超平面距离最近的样本点称为支持向量,而支持向量机的目的就是求取距离这个点(下图中带有v字母的点,与其他实例点无关)最远的分离超平面,
这个点在确定分离超平面时起着决定性作用,所以把这种分类模型称为支持向量机。
二、数学依据
2.1 点到面的距离
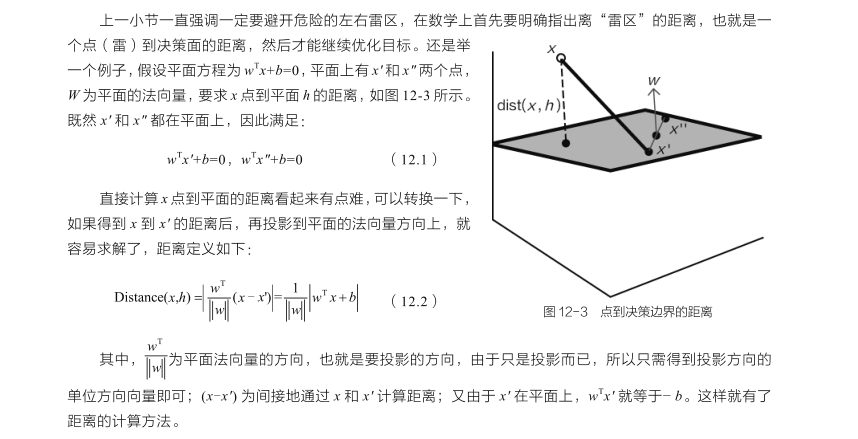
2.2 目标函数






小结:通过拉格朗日乘子法,求出来格朗日乘子(α),进而求出w与b。通过α可以求出支持向量,w与b可以确定超平面
2.3 极简案例
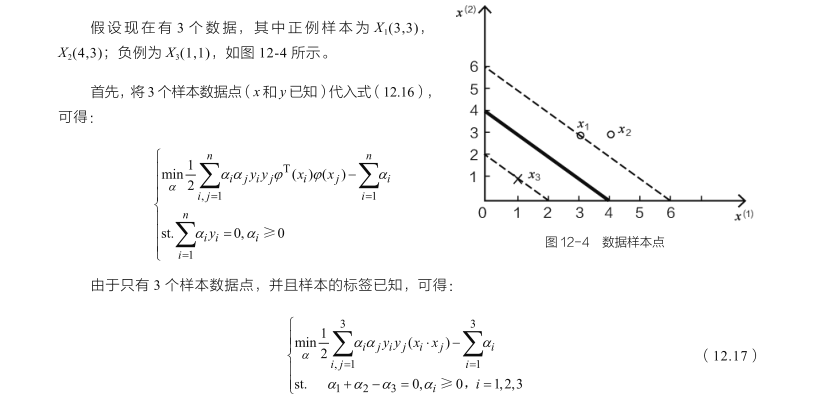

求得:
α1 = 0.25;α2=0;α3 = 0.25;
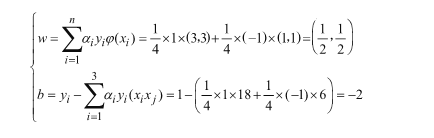
即超平面为:0.5x1 + 0.5x2 - 2 = 0
当0.5x1 + 0.5x2 - 2 > 0 时,结果为1
当0.5x1 + 0.5x2 - 2 < 0 时,结果为-1
Python代码为
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.svm import SVC import matplotlib.pyplot as plt X = np.array([[3,3], [4,3], [1,1]]) y = np.array([1, 1, -1]) svc = SVC(kernel='linear') svc.fit(X, y) w = svc.coef_[0] # 权重 b = svc.intercept_[0] # 截距 # 超平面为 print(f"超平面为:{w[0]}*x1+{w[1]}*X2+{b}")

三、案例
3.1 数据准备
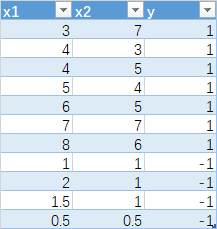
3.2 代码
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.svm import SVC import matplotlib.pyplot as plt df = pd.read_excel('../data/svm.xlsx', sheet_name='Sheet1') X = df.iloc[:, :2] x1 = np.array(df['x1']) y = df['y'] svc = SVC(kernel='linear') svc.fit(X, y) print(svc.support_vectors_) def plot_svc(X,label,support_vectors_,w,b): data = np.array(X) for j in support_vectors_: # 画出支持向量的点 plt.scatter(j[0], j[1], s=150, c='white', linewidths=1.5,edgecolors='k', marker='o' ) for i in range(np.shape(data)[0]): if label[i] == 1: plt.scatter(data[i][0], data[i][1], c='b', s=50) # 画出标签为1的点 else: plt.scatter(data[i][0], data[i][1], c='g',s=50) # 画出标签为-1的点 x = np.array(X).transpose()[0] down = svc.support_vectors_[0] up = svc.support_vectors_[-1] y_c = w*x+b y_d = w*x + (down[1]-w*down[0]) y_u = w*x + (up[1] - w * up[0]) plt.plot(x1, y_c, 'r') plt.plot(x1, y_d, 'm--') plt.plot(x1, y_u, 'm--') plt.ylim(ymin=0) # 设置y轴最小值 plt.xlim(xmin=0) # 设置x轴最小值 plt.show() w = -svc.coef_[0][0] / svc.coef_[0][1] #默认svc.coef_[0][1] != 0 b = -svc.intercept_[0] / svc.coef_[0][1] plot_svc(X=X,label=y,support_vectors_=svc.support_vectors_, w=w, b=b)
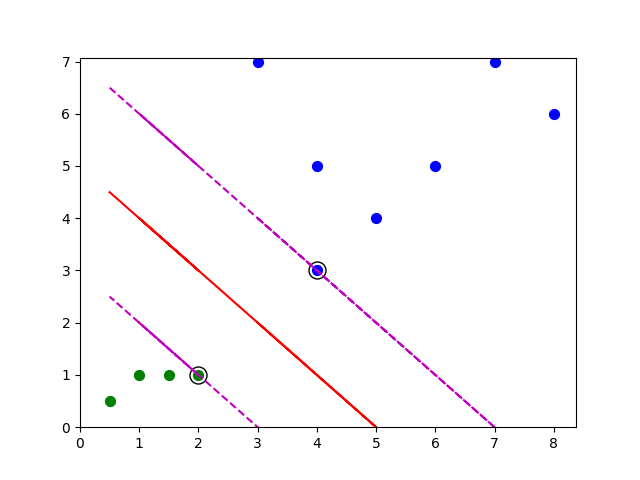
进行预测与评分和其他算法一样,就不单独显示了。关键知道各个值得意义与怎么求出来的。
四、松弛因子与核函数
前面介绍的都是平面,线性可分。但是有时存在线性不可分。需要引入松弛因子与核函数。
4.1 松弛因子![]()

如果不引入松弛因子,则超平面为实线,引入之后变成虚线。虚线可能更符合情况,预测更准确。

- C值大则松弛因子小,意味容忍性差,认为更少的样本为噪点
- C知晓则松弛因子大,因为容忍性好,认为更多的样本为噪点
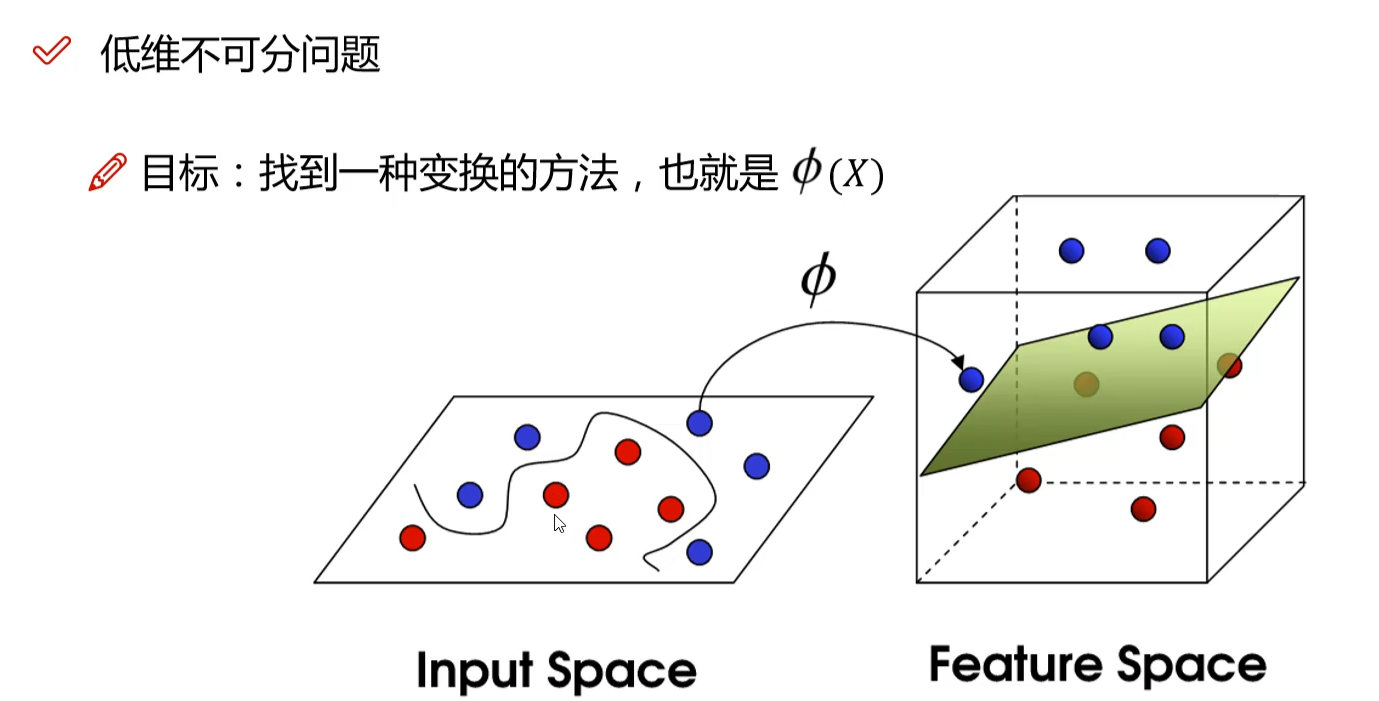
4.2 核函数
低维不可分可以映射到高维
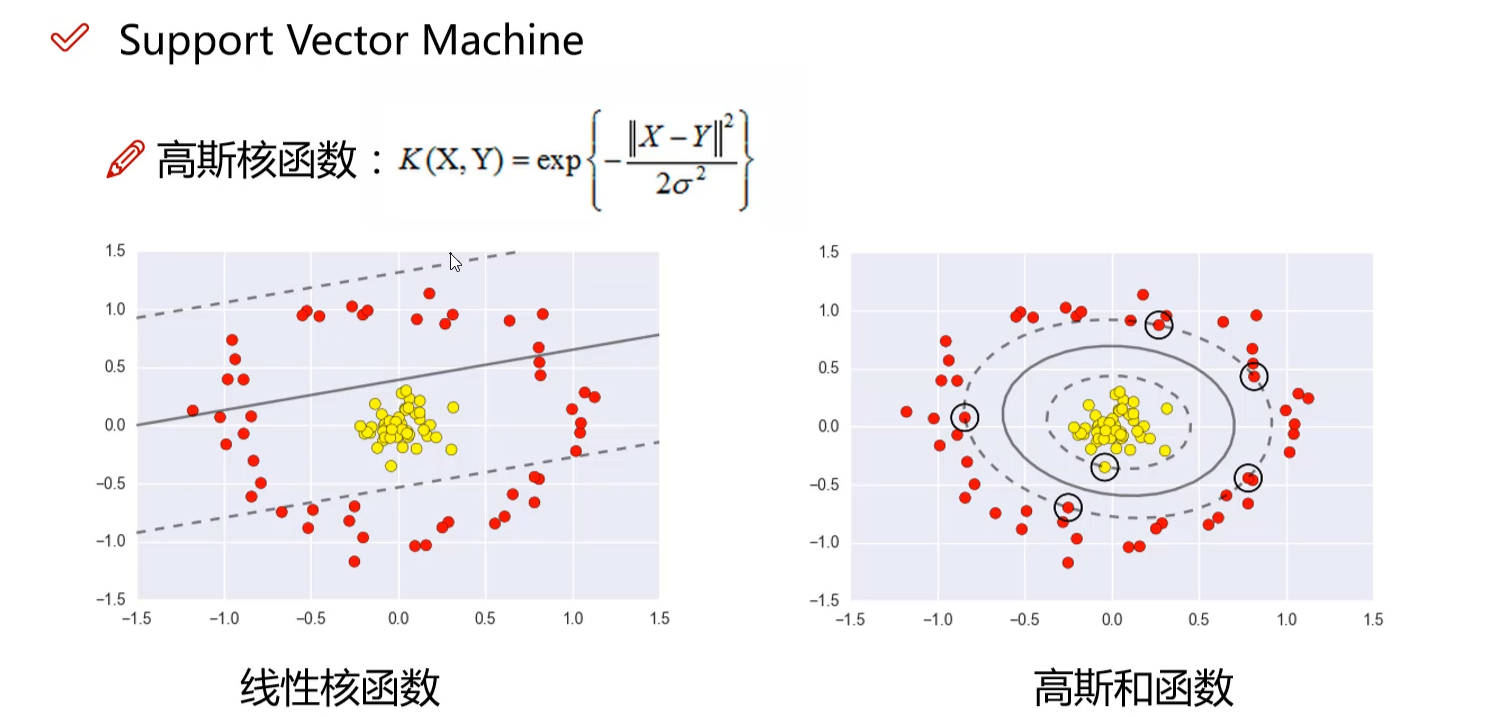
- 线性核函数不可分,用高斯核函数解决
-
![]()

五、参数
5.1 参数
参考:https://blog.csdn.net/weixin_39516865/article/details/111612090
- C: 目标函数的惩罚系数C,用来平衡分类间隔margin和错分样本的,default C=1.0;
- kernel:参数选择有linear, poly, rbf, sigmoid, precomputed或者自定义一个核函数, 默认的是rbf,即径向基核,也就是高斯核函数;而linear指的是线性核函数,poly指的是多项式核,sigmoid指的是双曲正切函数tanh核。
- degree:degree决定了多项式的最高次幂;
- gamma:核函数的系数('poly','rbf','sigmoid'), 默认是gamma=1/n_features,即核函数的带宽,超圆的半径;
- coef0:核函数中的独立项,'rbf'和'poly'有效,即加在这两种核函数后面的bias值,次幂为0的项,默认是0.0,即认为多项式的核的常数项为0;
- probablity: 布尔取值,默认是false,指的是预测判定的时候是否采用概率估计;
- shrinking:是否进行启发式;
- tol(default=1e-3): svm结束标准的精度,即容忍1000分类里出现一个错误;
- cache_size: 制定训练所需要的内存(以MB为单位);
- class_weight: 正类和反类的样本数量是不一样的,这里就会出现类别不平衡问题,该参数就是指每个类所占据的权重,默认为1,即默认正类样本数量和反类一样多,也可以用一个字典dict指定每个类的权值,或者选择默认的参数balanced,指按照每个类中样本数量的比例自动分配权值。
- verbose: 在训练数据完成之后,会把训练的详细信息全部输出打印出来,可以看到训练了多少步,训练的目标值是多少;但是在多线程环境下,由于多个线程会导致线程变量通信有困难,因此verbose选项的值就是出错,所以多线程下不要使用该参数。
- max_iter: 最大迭代次数,这个是硬限制,它的优先级要高于tol参数,不论训练的标准和精度达到要求没有,都要停止训练。默认值是-1,指没有最大次数限制;
- decision_function_shape:原始的SVM只适用于二分类问题,如果要将其扩展到多类分类,就要采取一定的融合策略,这里提供了三种选择。ovo一对一,决策所使用的返回的是(样本数,类别数*(类别数-1)/2),ovr一对多,返回的是(样本数,类别数),或者None,就是不采用任何融合策略, 默认是ovr,因为此种效果要比oro略好一点。
- random_state :在使用SVM训练数据时,要先将训练数据打乱顺序,用来提高分类精度,这里就用到了伪随机序列。如果该参数给定的是一个整数,则该整数就是伪随机序列的种子值;如果给定的就是一个随机实例,则采用给定的随机实例来进行打乱处理;如果啥都没给,则采用默认的 np.random实例来处理。
5.2 核的选择
- 应用最广的应该就是rbf核,无论是小样本还是大样本,高维还是低维等情况,rbf核函数均适用。
- 如果Feature的数量很大,甚至和样本数量差不多时,往往线性可分,这时选用LR或者线性核linear;
- 如果Feature的数量很小,样本数量正常,不算多也不算少,这时选用rbf核;
- 如果Feature的数量很小,而样本的数量很大,这时手动添加一些Feature,使得线性可分,然后选用LR或者线性核linear;
- 多项式核一般很少使用,效率不高,结果也不优于rbf;
- linear核参数少,速度快;rbf核参数多,分类结果非常依赖于参数,需要交叉验证或网格搜索最佳参数,比较耗时;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号