分词
一、概述
对文本进行分析时,经常需要先进行分析,为后面将文本向量化做准备。
二、jieba分词
参考:https://blog.csdn.net/qq_45288176/article/details/115681292
2.1 什么事jieba(结巴)库
- 字如其名,结巴库主要用于中文分词,很形象的画面想必一下子就出现在了大家的面前,结巴在说话时一个词一个词从嘴里往外蹦的时候,已经成功地模拟了我们jieba函数的处理过程!!!
- Jieba库是优秀的中文分词第三方库,中文文本需要通过分词获得单个的词语
- Jieba库的分词原理:利用一个中文词库,确定汉字之间的关联概率,汉字间概率大的组成词组,形成分词结果。除了分词,用户还可以添加自定义的词组
- jieba库提供三种分词模式,最简单只需要cut
2.2 jieba库的使用规则
2.2.1 jieba分词的三种模式
- 精确模式:就是把一段文本精确地切分成若干个中文单词,若干个中文单词之间经过组合,就精确地还原为之前的文本。其中不存在冗余单词。
- 全模式:将一段文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式,或者有不同的角度来切分变成不同的词语,在全模式下,Jieba库会将各种不同的组合都挖掘出来。分词后的信息再组合起来会有冗余,不再是原来的文本。
- 搜索引擎模式:在精确模式基础上,对发现的那些长的词语,我们会对它再次切分,进而适合搜索引擎对短词语的索引和搜索。也有冗余。
2.2.2 jieba库的一般函数
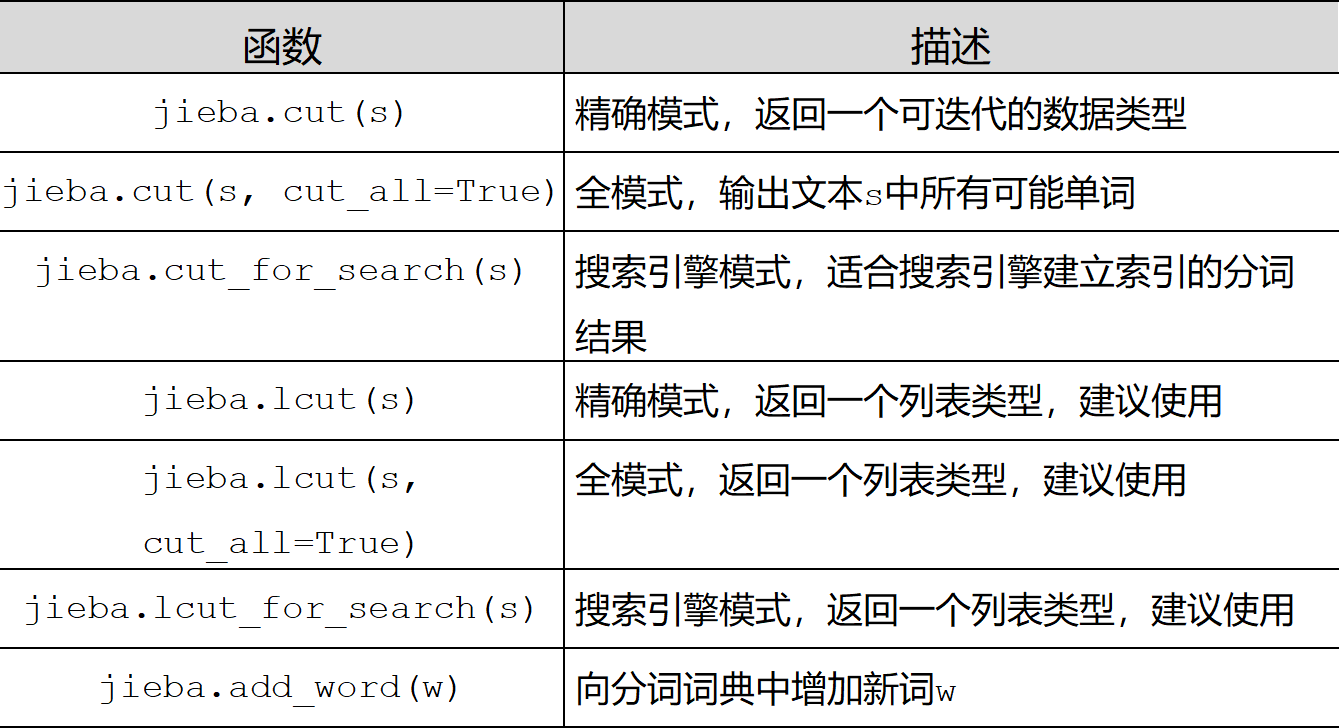
注意:jieba.cuts(s) 返回的是一个可迭代的数据类型,jieba.cuts(s) 后 使用 cut = [w for w in cut if w not in stopWords],处理中文停用词问题时 显示错误,是因为一般stopWord为list 列表[]类型,与cut迭代类型不兼容
,此时出现错误,我们应该了解到jieba.lcuts(s)函数 恰恰返回一个列表类型,此时正常运行。那么就要引入我们一下会讲到的一点jieba库的具体使用
源码
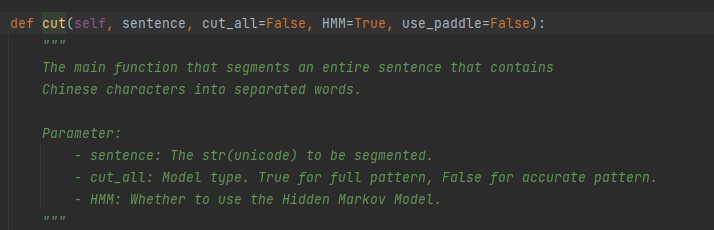
2.3 案例
import jieba jieba.setLogLevel(jieba.logging.INFO) sentence = '我来到林森大楼好好学习' seg_list = jieba.cut(sentence=sentence, cut_all=False) print("精确模式: " + "/ ".join(seg_list)) # 精确模式 seg_list = jieba.cut(sentence=sentence, cut_all=True) print("全模式: " + "/ ".join(seg_list)) # 全模式 seg_list = jieba.cut_for_search(sentence=sentence) # 搜索引擎模式 print("搜索模式: " + "/ ".join(seg_list)) # 搜索模式 sentence = '我来到林深大楼好好学习' seg_list = jieba.cut(sentence=sentence, cut_all=True) print("未添加新词: " + "/ ".join(seg_list)) # 全模式 jieba.add_word('林深') seg_list = jieba.cut(sentence=sentence, cut_all=True) print("添加新词: " + "/ ".join(seg_list)) # 全模式

注意:
- 新词识别 “林森”并没有在词典中,但是也被Viterbi算法识别出来了
- 虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率,jieba.add_word

 浙公网安备 33010602011771号
浙公网安备 33010602011771号