决策树
一、基础概念
1.1 信息熵
熵越大,数据的不确定性越高。熵越小,数据的不确定性越低;
物理定义熵增:熵增过程是一个自发的由有序向无序发展的过程;

条件熵:在一个条件下,随机变量的不确定性。
信息增益:熵 - 条件熵;表示特征X使得Y的不确定性减少的程度(分类后的专一性,希望分类后的结果是同类在一起)
熵:明天7点前起床的信息熵是2
条件熵:明天是周六,7点前起床的信息熵是0.02
信息增益:2-0.02=1.98; 在获知明天是周六的信息后,7点前起床的的不确定性较少了1.98,不确定性减少很多,所以看信息增益大
import numpy as np # 概率都为1/2 H = -(1 / 2 * np.log2(1 / 2) + 1 / 2 * np.log2(1 / 2)) print(H) # 1.0 # 概率为1/4与3/4 H = -(3 / 4 * np.log2(3 / 4) + 1 / 4 * np.log2(1 / 4)) print(H) # 0.8112781244591328 # 概率为1 H = -(1 * np.log2(1 / 1)) print(H) # -0.0
结论:分类的质量依赖信息熵,信息熵越小则说明分类的效果越好。当然理论上来说我们可以通过决策树进行无线划分,但是这样又会导致过拟合,因此我需要把握划分的度即可。
1.2 决策树结构
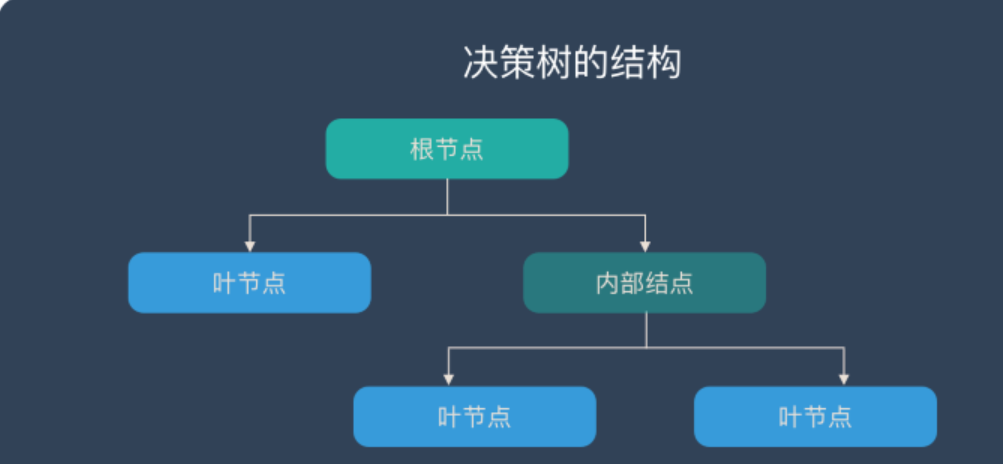
在上图的决策树中,决策过程的每一次判定都是对某一属性的“测试”,决策最终结论则对应最终的判定结果。
一般一棵决策树包含:一个根节点、若干个内部节点和若干个叶子节点, 易知:
- 每个非叶节点表示一个属性测试。
- 每个分支代表这个特征属性在某个值域上的输出。
- 每个叶子节点存放一个类别(即决策结果)。
- 每个节点包含的样本集合通过属性测试被划分到子节点中,根节点包含样本全集。
1.3 DecisionTreeClassifier 参数
转载:https://www.cnblogs.com/celine227/p/14225044.html
DecisionTreeClassifier(
criterion="gini",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
class_weight=None,
ccp_alpha=0.0)3
1.3.1 criterion: 特征选取标准
默认:gini。
可选gini(基尼系数)或者entropy(信息增益)。
两种算法差异不大对准确率无影响,信息墒的运行效率低一点,因为它有对数运算.一般说使用默认的基尼系数”gini”就可以了,即CART算法。
1.3.2 splitter: 特征划分标准
可选best或random,默认为best。
best是在特征的全部划分点中找到最优的划分点,比如基于信息增益分类时,则选择信息增益最大的特征点。
random是在随机选择的部分划分点找到局部最优的划分点。
一般在样本量不大的时候,选择best,样本量过大,用random。
1.3.3 max_depth:决策树最大深度
默认为None。
一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。常用来解决过拟合
1.3.4 min_samples_split:内部节点再划分所需最小样本数
默认为2。
意义:如果节点上的样本已经低于这个值,则不会再寻找最优的划分点进行划分,且以该结点作为叶子节点。样本过多的情况下,可以设定一个阈值,具体可根据业务需求和数据量来定。可以输入一个具体的值(int),或小于1的数(float类型,会根据样本量计算百分比)
1.3.5 min_samples_leaf:叶子节点所需最少样本数
默认为1。
意义:如果达不到这个阈值,则同一父节点的所有叶子节点均被剪枝,这是一个防止过拟合的参数。可以输入一个具体的值(int),或小于1的数(float类型,会根据样本量计算百分比)。
1.3.6 min_weight_fraction_leaf:叶子节点所有样本权重和
默认为0。
意义:如果低于阈值,则会和兄弟节点一起被剪枝,默认是0,就是不考虑权重问题。这个一般在样本的分布类别偏差很大,或有较多缺失值的情况下会考虑,这时我们就要注意这个值了。
1.3.7 max_features:划分考虑最大特征数
默认为None。
意义:不输入则默认全部特征,可以选 log2N,sqrt(N),auto或者是小于1的浮点数(百分比)或整数(具体数量的特征)。如果特征特别多时,比如大于50,可以考虑选择auto来控制决策树的生成时间。
1.3.8 random_state:随机数生成种子
默认为:None。
意义:设置随机数生成种子是为了保证每次随机生成的数是一致的(即使是随机的);如果不设置,那么每次生成的随机数都是不同的。
1.3.9 max_leaf_nodes:最大叶子节点数
默认为:None。
意义:防止过拟合,默认不限制,如果设定了阈值,那么会在阈值范围内得到最优的决策树。
如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
1.3.10 min_impurity_decrease:节点划分最小不纯度
默认为:0。
意义:这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益)小于这个阈值,则该节点不再生成子节点。
sklearn 0.19.1版本之前叫 min_impurity_split。
1.3.11 class_weight:类别权重
默认为:None。
意义:在样本有较大缺失值,或类别偏差较大时可选,防止决策树向类别过大的样本倾斜。可设定None或者balanced,后者会自动根据样本的数量分布计算权重,样本数少则权重高,与min_weight_fraction_leaf对应。
不适用于回归树 sklearn.tree.DecisionTreeRegressor
1.3.12 是否排序
默认为:False。
模型参数选择的几项建议:
1.样本少数量但是样本特征非常多的时候,决策树很容易过拟合,在拟合决策树模型前,推荐先做维度规约,比如主成分分析(PCA),特征选择(Losso)。这样特征的维度会大大减小。再来拟合决策树模型效果会好。
在训练模型先,注意观察样本的类别情况(主要指分类树),如果类别分布非常不均匀,就要考虑用class_weight来限制模型过于偏向样本多的类别。
二、鸢尾花案例
2.1 官方包解决
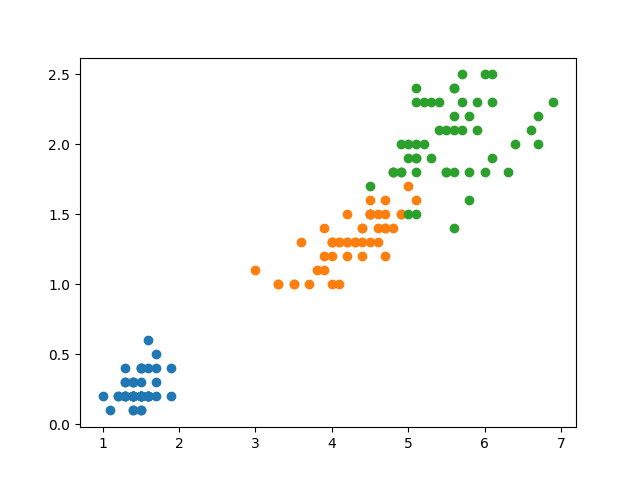
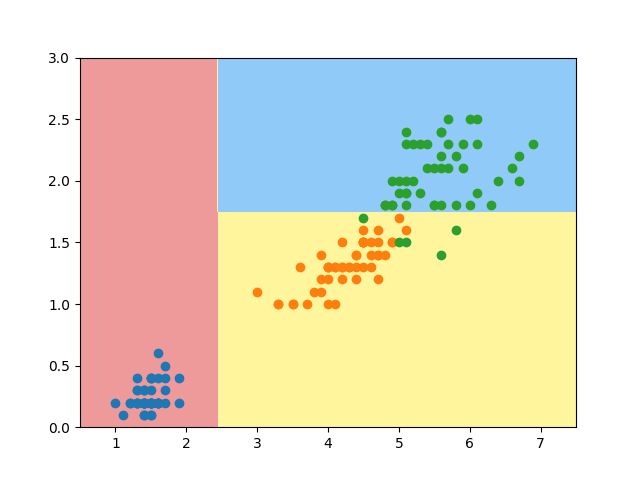
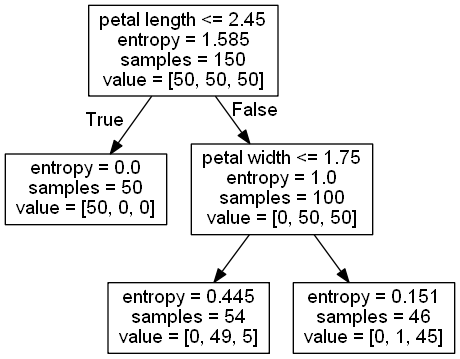
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.model_selection import GridSearchCV from matplotlib.colors import ListedColormap from sklearn import datasets from scipy.stats import pearsonr from sklearn.tree import DecisionTreeClassifier, export_graphviz # 获取数据集 iris = datasets.load_iris() # (150, 4) (150,) # print(iris['data'].shape, iris['target'].shape) df = pd.DataFrame(data=iris.data, columns=iris.feature_names) # print(iris) print(df) # 使用皮尔逊系数确认哪些列与标签强相关 dict_pear = {} for column in df.columns: dict_pear[column] = np.round(pearsonr(df[column], iris['target'])[0], 4) print(dict_pear) # {'sepal length (cm)': 0.7826, 'sepal width (cm)': -0.4267, 'petal length (cm)': 0.949, 'petal width (cm)': 0.9565} # 可以发现,petal length (cm)': 0.949, 'petal width (cm)': 0.9565 相关度较高,也为了可视化方便,选取后面两个 X = np.array(df.iloc[:, 2:]) # y是目标值 0,1,2 y = iris['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=2 ) dt_clf = DecisionTreeClassifier() # 决策树,max_depth 最高的深度,先设置2后面在调整,criterion:默认基尼系数, 建议采用交叉熵 gc = GridSearchCV(estimator=dt_clf, param_grid={'max_depth':[1, 2, 3, 4], 'criterion':['entropy'], 'random_state':[2]},cv=2) gc.fit(X_train, y_train) # 交叉验证与网格搜索相关结果如下: print("最优模型参数", gc.best_estimator_) # DecisionTreeClassifier(criterion='entropy', max_depth=2, random_state=2) # 可视化 plt.scatter(X[y == 0, 0], X[y == 0, 1]) # 采用目标值来筛选样本,吧样本的第0个和第1个特征值分别设置为散点图的x与y轴 plt.scatter(X[y == 1, 0], X[y == 1, 1]) plt.scatter(X[y == 2, 0], X[y == 2, 1]) plt.show() # 采用等高线刻画出分类图,此部分与二叉树原理无关,感兴趣同事可以参考:np.meshgrid np.c_ plt.contourf API def plot_decistion_boundary(model, axis): x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1] - axis[0])) * 100).reshape(-1, 1), np.linspace(axis[2], axis[3], int((axis[3] - axis[2])) * 100).reshape(-1, 1) ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9']) plt.contourf(x0, x1, zz, cmap=custom_cmap) # 将最优解带入到决策树中,不再设训练集与测试集 clf = DecisionTreeClassifier(criterion='entropy',random_state=2, max_depth=2) clf.fit(X, y) export_graphviz(decision_tree=clf,out_file="../data/iris.dot", feature_names=['petal length', 'petal width']) # 设置等高线的边界 plot_decistion_boundary(clf, axis=[0.5, 7.5, 0, 3]) plt.scatter(X[y == 0, 0], X[y == 0, 1]) plt.scatter(X[y == 1, 0], X[y == 1, 1]) plt.scatter(X[y == 2, 0], X[y == 2,1]) plt.show()
普通图
等高线图:
二叉树图:
2.2 简单推导
from collections import Counter import numpy as np from sklearn.datasets import load_iris # 返回的信息熵越小,则说明分割的阈值越好 def entropy(y): counter = Counter(y) res = 0.0 for num in counter.values(): p = num / len(y) res += -p * np.log2(p) return res # 实现指定维度(特征),的阈值进行分割的函数 def split(X, y, d, v): bool_left = X[:, d] < v bool_right = X[:, d] > v # 返回拆分的目标值与特征值 return X[bool_left], X[bool_right], y[bool_left], y[bool_right] # 搜索最佳列的最佳阈值 def try_split(X, y): # 存储最低的信息熵 best_entropy = np.inf # 存储最佳维度和阈值 best_d, best_v = -1, -1 # 外循环用来变量维度(特征列) for d in range(X.shape[1]): # [0,5,3,2] ==> [0,2,3,5] ==> v [1,1.5,4] sort_index = np.argsort(X[:, d]) # 内循环找到维度(特征列)的每一个阈值 for num in range(1, len(X)): # 如果两个值相等,则阈值就等于他们平均值,这样没有意义 if X[sort_index[num - 1], d] != X[sort_index[num], d]: # 阈值永远取当前列,两个值的平均数 (2.0 可以保留小数) v = (X[sort_index[num - 1], d] + X[sort_index[num], d]) / 2.0 X_l, X_r, y_l, y_r = split(X, y, d, v) # 计算当前阈值的信息熵 e = entropy(y_l) + entropy(y_r) if best_entropy > e: best_entropy = e best_d, best_v = d, v return best_entropy, best_d, best_v iris = load_iris() X = iris.data[:,2:] # y是目标值 0,1,2 y = iris['target'] # 第一次二叉树 best_entropy,best_d,best_v = try_split(X,y) print("best_d=", best_d) print("best_v=", best_v) print("best_entropy=", best_entropy) # 把特征与目标值,然后把获得维度,和当前维度的阈值传入,可以得到信息熵 X1_1, X1_r, y1_1, y1_r = split(X, y, best_d, best_v) print(entropy(y1_1)) # 0.0 print(entropy(y1_r)) # 1.0 # 第二次二叉树, 返回维度和维度的阈值 best_entropy2, best_d2, best_v2 = try_split(X1_r, y1_r) print("best_d2=", best_d2) print("best_v2=", best_v2) print("best_entropy2=", best_entropy2) # 把特征与目标值,然后把获得维度,和当前维度的阈值传入,可以得到信息熵 X2_1,X2_r,y2_1,y2_r = split(X1_r,y1_r,best_d2,best_v2) print(entropy(y2_1)) # 0.44506485705083865 print(entropy(y2_r)) # 0.15109697051711368

 浙公网安备 33010602011771号
浙公网安备 33010602011771号