K近邻
一、概述
1.1 关键点
- 我们提出了k近邻算法,算法的核心思想是,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
更通俗说一遍算法的过程,来了一个新的输入实例,我们算出该实例与每一个训练点的距离(这里的复杂度为0(n)比较大,所以引出了下文的kd树等结构),然后找到前k个,这k个哪个类别数最多,我们就判断新的输入实例就是哪类!
- 与该实例最近邻的k个实例,这个最近邻的定义是通过不同距离函数来定义,我们最常用的是欧式距离
- 为了保证每个特征同等重要性,我们这里对每个特征进行归一化或者标准化
- k值的选取,既不能太大,也不能太小,何值为最好,需要实验调整参数确定,可以通过网格搜索来确定
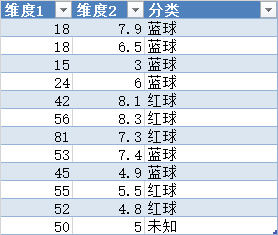
1.2 构造数据
由下表画出下图
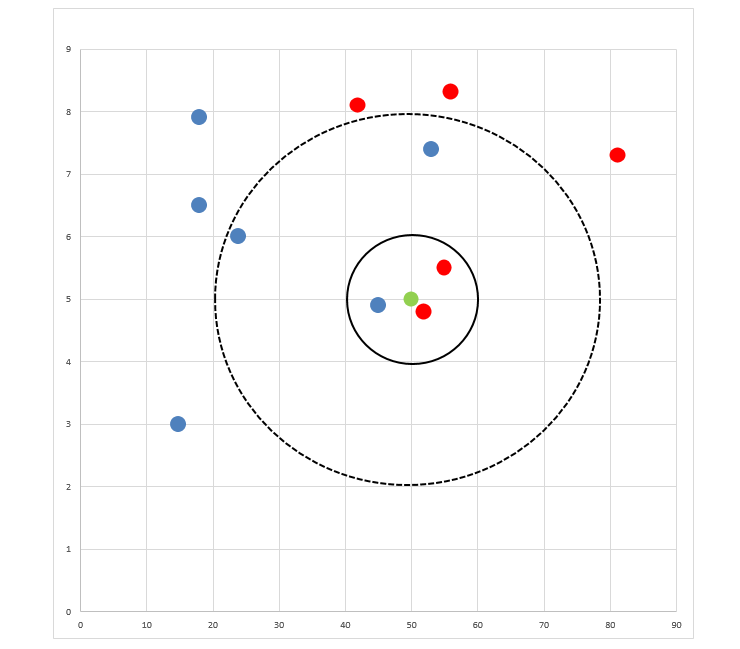
- 如果K=3,绿色圆球的最邻近的3个球是2个红球和1个蓝球,少数从属于多数,基于统计的方法,判定绿球的这个待分类点属于红球。
- 如果K=5,绿色圆球的最邻近的5个邻居是2个红球和3个蓝球,还是少数从属于多数,基于统计的方法,判定绿球的这个待分类点属于蓝球。
二、代码实现
import numpy as np import pandas as pd from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import GridSearchCV from sklearn.neighbors import KNeighborsClassifier from sklearn.neighbors import RadiusNeighborsClassifier # 构造数据 维度1 = [18, 18, 15, 24, 42, 56, 81, 53, 45, 55, 52] 维度2 = [79, 65, 30, 60, 81, 83, 73, 74, 49, 55, 48] 分类 = ['蓝球', '蓝球', '蓝球', '蓝球', '红球', '红球', '红球', '蓝球', '蓝球', '红球', '红球'] X_test = [[50, 50]] data = np.transpose(np.array([维度1, 维度2, 分类])) df = pd.DataFrame(data=data, columns=['维度1', '维度2', '分类']) X_train = np.array(df.iloc[:, :2]) y_train = df['分类'] mm = MinMaxScaler() X_train = mm.fit_transform(X_train) X_test = mm.transform(X_test) # 制定不同的邻居数,获得不同结果 result_dict = {} for i in range(len(分类)): # 遍历邻居数 n = i + 1 knn = KNeighborsClassifier(n_neighbors=n) knn.fit(X_train, y_train) result = knn.predict(X_test)[0] result_dict[n] = result print(result_dict) # 多种KNN算法比较 models = [] # 靠K值来定邻居,不管跨越多大半径 models.append(('knn', KNeighborsClassifier(n_neighbors=5))) # 距离可以查看源码, 距离的倒数作为权重 models.append(('knn with weights', KNeighborsClassifier(n_neighbors=5, weights='distance'))) # 靠半径来确定邻居,半径范围内有多少算多少 models.append(('radius neighbors', RadiusNeighborsClassifier(radius=20))) # 靠半径来确定邻居,半径范围内有多少算多少, 距离的倒数 models.append(('radius neighbors', RadiusNeighborsClassifier(radius=20, weights='distance'))) result_list = [] for name, model in models: model.fit(X_train, y_train) result_list.append((name, model.predict(X_test)[0])) print(result_list) # 交叉验证,网格搜索,寻找最优参数 knn_cv = KNeighborsClassifier() # 不配置参数 gc = GridSearchCV(estimator=knn_cv, param_grid={'n_neighbors': [3, 4, 5]}, cv=2) # 模型训练 gc.fit(X_train, y_train) # 交叉验证与网格搜索相关结果如下: print("最优模型参数", gc.best_estimator_) print('平均最优训练分数', gc.best_score_) print('交叉验证打印结果', gc.cv_results_)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号