Kmeans
一、KMeans算法步骤
是最简单的聚类算法之一,算法接受参数 k ;然后将事先输入的n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
- 指定要分成的聚类数,算法的K值默认为5,也叫5个簇(聚类)
- 然后在样本空间中随机挑选K个数据点,作为簇的质心。很明显这些质心不是最优解
-
遍历集合中每一个数据点,计算它们与每个质心的距离(例如:欧氏距离)。数据点离哪个质心近,就归属于哪一个类别 。此时K个类别已经开始形成(物以类聚,距离群分)
- 现在每一个质心都聚集很多样本点。接下来再次计算每个簇新的质心。(每个簇的新质心的属性值等于此簇中所有样本的属性值得平均值)
- 一直重复进行步骤(3)和(4),直到达到算法指定的最大迭代次数,或者收敛到算法能够接受的阈值为止。
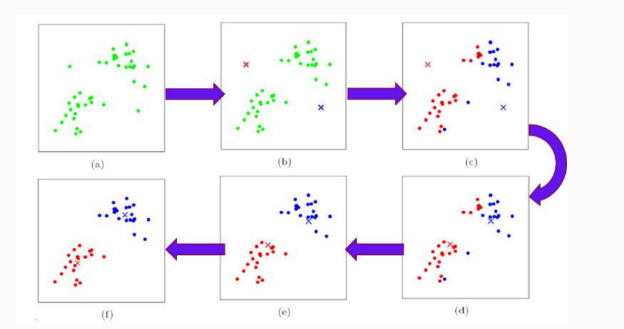
二、 极简案例
K值决定了初始质心的数量。K值为几,就要有几个质心(后续就会划分成几个群体),这里为了更好的演示算法的原理我们采用了一维数据来进行计算与分析。
2.1 算法演示





2.2 代码实现
from sklearn.cluster import KMeans import numpy as np # 上面测试样本数据 x = np.array([15,15,16,19,19,20,20,21,22,28,35,40,41,42,43,44,60,61,65]) km = KMeans(n_clusters=2) # 唯一一个在训练时不需要目标值的算法 res=km.fit(x.reshape(-1,1)) # k-means算法训练的过程就是找质心的过程 print(km.cluster_centers_) # 打印分组的标签 print(km.labels_)
三、样本分群
3.1 所需数据
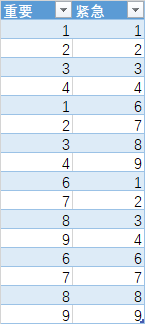
制成图表为
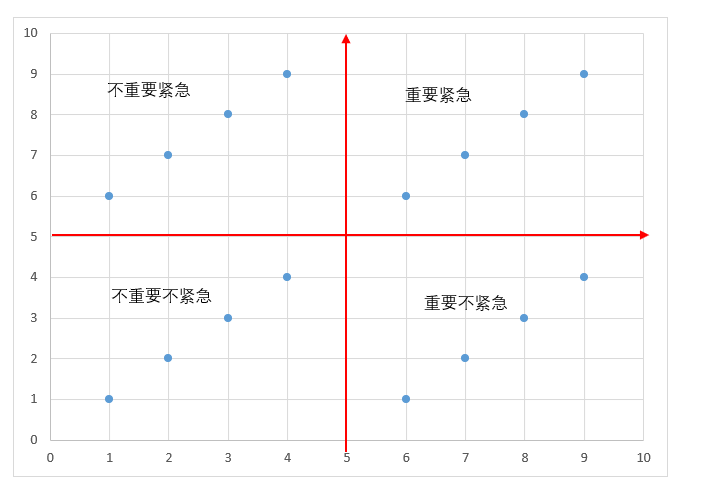
使用Keans完成分群。
3.2 代码实现
import numpy as np import pandas as pd from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score zy = [1, 2, 3, 4, 1, 2, 3, 4, 6, 7, 8, 9, 6, 7, 8, 9] jj = [1, 2, 3, 4, 6, 7, 8, 9, 1, 2, 3, 4, 6, 7, 8, 9] data = np.transpose(np.array([zy, jj])) score_list = [] # 用来存储每个K下模型的轮廓系数 silhouette_int = -1 # 默认轮廓系数值域分布为[-1,1],因此silhouette_int初始值可以设置为-1 for n_clusters in range(2, 6): # 遍历从2到6个有限组,类似网格搜索 model_kmeans = KMeans(n_clusters=n_clusters) # 创建聚类模型对象 labels_tmp = model_kmeans.fit_predict(data) # 训练聚类模型 silhouette_tmp = silhouette_score(data, labels_tmp) # 得到每个K下的平均轮廓系数, if silhouette_tmp > silhouette_int: # 如果当前轮廓系数更高 best_k = n_clusters # 保存K将最好的K存储下来 silhouette_int = silhouette_tmp # 保存平均轮廓得分 score_list.append((n_clusters, silhouette_tmp)) # 将每次K及其得分追加到列表 print('{:*^60}'.format('不同 n_clusters 对应的得分为')) print(np.array(score_list)) # 打印输出所有K下的详细得分 print(f'n_clusters 最优解为:{best_k} 轮廓系数为: {silhouette_int}') KM = KMeans(n_clusters=best_k) # 将最优解代入 label = KM.fit_predict(data) # 对数据进行分群 df = pd.DataFrame(data=np.transpose(np.array([zy, jj, label])), columns=['zy','jj', 'label']) print('{:*^60}'.format('最优解')) print(df)
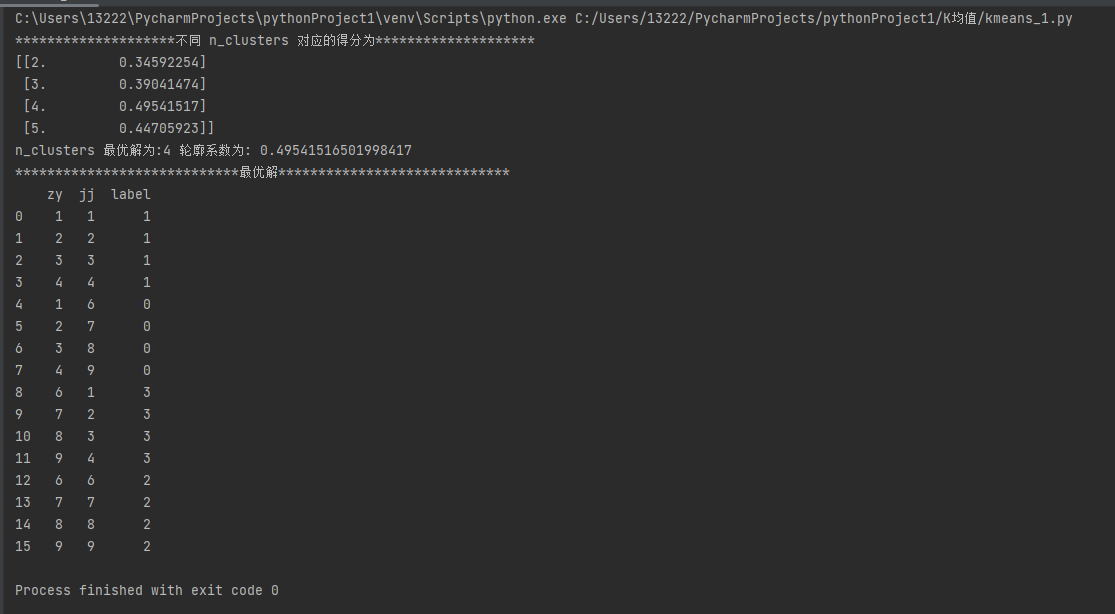
改代码的实现过程为:
-
定义初始变量score_list和silhouette_int。score_list,用来存储每个K下模型的平均轮廓系数,方便在最终打印输出详细计算结果。silhouette_int 的初始值设置为-1,如果循环得到的轮廓系数值比该值大,则将其赋值给silhouette_int。
-
使用for循环遍历每个值,这里的K的范围确定为2~5。一般而言,用于聚类分析的K的确定不会太大。如果值太大,那么聚类效果可能不明显,因为大量信息都会被分散到各个类之中,从而导致数据的碎片化。还需要根据分析需求确定,如果用来做数据分析,K太大将导致可能无法找到各个群的核心差异特征。
- 最后打印输出每个K值下详细信息以及最后K值和最优轮廓系数得分
- 将最优解K=4带入,打印输出
3.3 轮廓系数
参考:https://www.cnblogs.com/qianslup/p/16847591.html 中轮廓系数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号