


面试备考
一。网易大数据开发面经
一面:
1.自我介绍
尊敬的面试官您好,我是来自河北省的袁志良。本科就读于燕山大学里仁学院。正如大家所见,我的内在和外表一样敦厚和实在,成长的经历已经使我不骄不躁,不浮不飘。我本人,虽然不善于花言巧语,但是真诚和厚道总能使我很好的融入集体,收获朋友。我知识和技能扎实,能够决心钻研,并解决各种疑难问题,并从中获取自信和快乐。公司的口号是********,我感觉也非常适合我,也相信,我能够快速的融入集体,并不断为公司创造新的价值。
2.项目介绍
----------------------
3.了解hashmap和 hashtable吗,介绍一下他们的区别?
①hm出现的比ht晚一些,但都是基于哈希表来实现键值映射的工具,可以增删改查键值对,可以对其提供遍历视图。
虽然都实现了Map、Cloneable、Serializable三个接口。但是HashMap继承自抽象类AbstractMap,而HashTable继承自抽象类Dictionary。
②对空值的表现
hm支持空的键、值,而ht遇到空时会抛出异常,原因是hm对null赋值为0。
③数据结构上基本相同。
④算法
在创建之初,给定初始化大小,ht会直接使用,hm则会扩充为2的幂次方大小。
⑤线程安全
ht是同步的,hm不是,所以要做同步代码块synchronized,或者用ConcurrentHashMap。
最后:ht已经淘汰了。
4.java里set,Array和map等容器了解吗?他们的继承关系写一下。最顶层好像是java.util.Collection和java.util.Map?
①容器是用来存储数据的。set:一种包含已排序对象的关联容器,只是单纯的键的集合。
array:有序元素序列,可存储多个相同类型数据,而且是连续的。
map:键值对容器,数据成对出现,key值不能重复。
collecttion
list set map
ArrayList / Linklist /Vector HashSet/TreeSet HashMap/HashTable/TreeMap
5.线程安全有了解吗?介绍一下
线程安全:即多线程访问数据保持一致性。(保证其读写一致性);线程安全则是多线程操作同一个对象不会有问题。
线程安全必须要使用很多synchronized关键字来同步控制,所以必然会导致性能的降低。
PHP两种执行方式:线程安全用ISAPI;非线程安全用FastCGI。
ArrayList是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
StringBuilder是非线程安全的,StringBuffer是线程安全的。
6.介绍GC
GC就是电脑的垃圾回收机制,当使用new关键字时,就会在堆中创建对象,而并没手动释放内存,java的自动垃圾回收机制起作用,当对象不被占用的时候,机制就会在莫一时刻将内存释放,不会导致堆内存溢出。
7.介绍spark,client提交application后,接下来的流程,driver,yarn怎么通讯,开始执行?
①spark是大数据计算引擎,用Scala语言进行实现的,他是一种面向对象(把数据和对数据处理的方法写到一起,作为互相依赖的整体--对象。抽象出共性,形成类,通过接口实现与外部通信。)、函数式编程语言(指数学上的函数:给定输入固定的输出,没有副作用)、能够像操作本地集合对象一样,轻松的操作分布式数据集。 特点:运行速度快,易用性好,通用性强,随处可运行。
②client提交application后:client向RM发出请求--》RM返回一个applicationID--》client向RM回应application的相关信息ASC--》
RM接收到ASC相关信息后,他会调度一个合适的container(容器)来启动AM(放置服务方法的地方)--》当AM启动后,RM给AM集群最大和最小的资源信息--》AM获得资源后,会请求一些一定数目的container--》RM根据AM的申请,尽可能的满足AM请求的container。
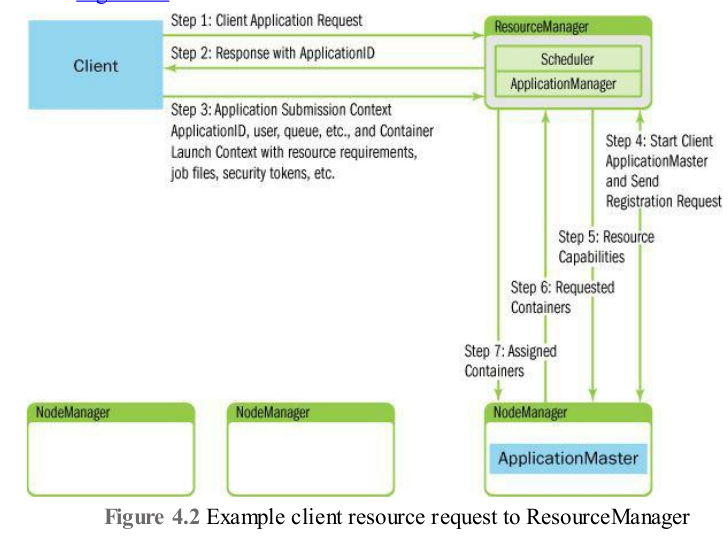
③driver,yarn通信:Driver才负责SQL的解析和元数据获取;
spark从提交到运行的全流程,下面再详细分析。
- 1、用户通过spark-submit脚本提交应用。
- 2、spark-submit根据用户代码及配置确定使用哪个资源管理器,以及在合适的位置启动driver。
- 3、driver与集群管理器(如YARN)通信,申请资源以启动executor。
- 4、集群管理器启动executor。
- 5、driver进程执行用户的代码,根据程序中定义的transformation和action,进行stage的划分,然后以task的形式发送到executor。(通过DAGScheduler划分stage,通过TaskScheduler和TaskSchedulerBackend来真正申请资源运行task)
- 6、task在executor中进行计算并保存结果。
- 7、如果driver中的main()方法执行完成退出,或者调用了SparkContext#stop(),driver会终止executor进程,并且通过集群管理器释放资源。
8.用队列实现栈的功能,手写代码?
栈:先进后出 队列:先进新出 略
二面:
1.自我介绍
2.参与的项目,代码量,实验环境等
3.MapReduce的过程,map,shuffle,reduce这些?
简单流程:读取到HDFS上的数据后,会有一个拆分split的过程,形成map键值对,随后要对得到的数据进行洗牌shuffle,通过内部hash机制,分到不同的位置上,最后经过reduce计算,得到数据的结果。
4.HDFS写数据的过程?
①client发起文件请求,Namenode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;②对文件切分,并请求第一个block应该传输到哪些datenode上;③namenode返回datenode;④client请求一台datenode上传数据,1收到后继续调用2,2去调用3,建立pipeline,返回客户端;⑤client开始上传第一个block,1收到后传给2,2再传给3;每台都会形成应答队列;⑥一个block上传成功后,client再次请求namenode上传第二个。
5.spark工作机制,哪些角色,作用?
???????
内部流程:主要由sparkcontext(spark上下文)、cluster manager(资源管理器)、executor(单个节点的执行进程)组成。
job 、stage、task是基本单位。spark催生job,job拆分为stage,stage划分为多个task。
数据块RDD:代码执行,driver根据action算子生成DAG图,图通过shuffle拆分为stage和task,传给Task Scheduler调用;通过调度算法,将task分给work node中的executor执行。
DAG scheduler为每一个job划分stage,并将单个stage分成多个task,然后他会将stage作为taskSet提交给底层的Task Scheduler执行。
Task Scheduler负责将DAGS cheduer产生的task调度到executor中执行。
6.spark yarn模式下的cluster模式和client模式有什么区别?
通常,cluster适用于生产环境,client更适用于交互、调试模式。
深层次:就是进程的区别。cluster向yarn申请资源,并监督执行状况,作业提交后可以关闭客户端client;
client仅仅想yarn请求executor,client会和请求的容器(container)通信来调度工作,不能离开。
网易云大数据面试
一面:
1.项目介绍
2.数据密度分布不均匀的解决方案?
算法问题 svm算法。采样--》合成--》加权--》分类
3.手写归并排序?
算法:分---》治
4.java:hashmap与hashset的区别;threadlocal原理;垃圾收集算法?
| HashMap | HashSet |
| 实现了Map接口 | 实现Set接口 |
| 存储键值对 | 仅存储对象 |
| 调用put()向map中添加元素 | 调用add()方法向Set中添加元素 |
| HashMap使用键(Key)计算Hashcode |
HashSet使用成员对象来计算hashcode值, 对于两个对象来说hashcode可能相同, 所以equals()方法用来判断对象的相等性, 如果两个对象不同的话,那么返回false |
| HashMap相对于HashSet较快,因为它是使用唯一的键获取对象 | HashSet较HashMap来说比较慢 |
ThreadLocal提供了set和get访问器用来访问与当前线程相关联的线程局部变量。
get函数就是从当前线程的threadlocalmap中取出当前线程对应的变量的副本;
在每个线程中,都维护了一个threadlocals对象,在没有ThreadLocal变量的时候是null的。一旦在ThreadLocal的createMap函数中初始化之后,这个threadlocals就初始化了。
5Linux:从日志文件中搜索带有abcde关键字的行;grep /awk /sed?
grep -r lisi 文件名|awk -F ='{print $1}'
二面:
1.自我介绍
2.HDFS create一个文件的流程?
HDFS:具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征。
客户端(HDFSClient)向NN发送请求,获取文件信息,NN会在缓存中查找是否存在请求创建的文件项,如果没有,就在NameSystem中创建一个新的文件项,添加到系统文件的目录树中。
3.HDFS写入流程?
写入:客户端client向NN发送RPC请求,NN检查文件是否存在和权限问题,client会切分文件,并向NN申请块和DN,此时形成管道pipeline,开始写入,调用的DN依次调用,最后写入完成,返回给客户端一个确认队列。
读取:客户端client向NN发送RPC请求,NN返回DN地址和文件部分或者全部,client选取最近的DN读取文件,读取完毕,关闭DN连接。
4.MapReduce第一代架构及其通信?
客户端client会向JobTracker发送一个作业,JobTracker会把作业拆分为多分,分给TaskTracker(任务执行者),(每个TT内部会有Map和Reduce的task),TT会隔一段时间性JT发送心跳信息,如果在一段时间内没有收到,JT人文TT已死 ,会更换TT。
5.yarn结构及其流程?
结构:客户端client提交作业请求后,有ResourceManager进行调度,(由scheduler和Application Manager组成),并要求NodeManager启动可以寄存和占用的资源任务,然后分布到不同的节点上。(AM被分配到不同节点上,不会互相影响)
流程:用户向yarn提交应用程序,RM为该应用程序分配第一个容器(container),并与NM通信,ApplicationMaster首先向RM注册,并通过轮询方式向RM申请资源,随后与NM通信,要求启动任务,NM配置好环境启动任务,各个任务通过RPC协议向AM汇报情况,以便任务失败后重启,应用程序完成,AM向RM 注销关闭自己。
面经:
1。链表反转?
分为迭代和递归,类似冒泡排序,先断开(存储后),在依次挪动指针。
2.大文件排序?
算法排序:https://blog.csdn.net/zhushuai1221/article/details/51781002
7.如何停止一个线程?
使用退出标志exit;或者用Boolean变量写一个方法,都会在while执行时停止。
8.虚拟机新生代怎么执行?
对象被存储在堆中,首先进入新生代,(分为一个Eden和两个Survivor),分布在Eden和其中一个survivor上,经过依次GC(复制算法)后,复制到另外一个survivor上,原来的两块被清除,此时年龄为1,每经过一次GC,年龄加一,默认到15后,进入老年代。
9,。cap原理?
c--一致性 a--可用性 p--分区容忍
总结:只可能满足其二。nosql主要是A P ;关系型数据库主要是 C A(即ACID);hbase是C P。
10.namenode宕机怎么处理?regionserver宕机怎么处理?
NN宕机:①利用secondNN来恢复,但容易造成数据丢失;②利用及时备份NFS(网络文件系统),设置多个data目录,数据不易丢失。
③利用Avatar NameNode,也是利用客户端访问时放在NFS中。
RS宕机:Master检测宕机的RS,然后HLog进行切分,Region重新分配并打开,HLog回放补救数据,恢复完成。
11.hbase如何保证数据一致性?
分为强一致性和弱一致性(允许某一时间偶尔不一致)
发消息给中间件--》中间件入库消息,返回结果--》业务操作--》操作结果返回中间件--》更改存储状态
强一致性: 每个region同时只有一台RegionServer来管理,region所有的请求也都是有RS来管理的,自然是强一致性的。
12.宕机回滚时如果有写数据怎么办?
宕机回滚的时候是无法写入数据的啊,有写如果HLog失败,也会重新发起的。如果有写入之前的操作,通过日志,会在回滚后重新得到原来的状态。
13.读blockcache时,如果有删除数据进memstore,怎么保证一致性?
HBase上Regionserver的内存分为两个部分,一部分作为Memstore,主要用来写;另外一部分作为BlockCache,主要用于读数据。
blockcache主要是读,先到memstore中找,如果没有或者进入删除数据,就会到blockcache中找,如果还没有,那就到磁盘中读。
14.memsotore多大刷盘?
memstore一般占40%,blockcache一般占20%,所以超过40%默认值就要刷盘,也可以自定义值。
15.小文件怎么合并?
①如果是本地文件:使用脚本,循环所有文件路径,通过globStatus()方法获得所有路径,通过IOUtils.CopBytes(in,out,4096,false)方法合并上传。也可以用MapReduce方法进行打包。
②hadoop提供了CombinFilesInputFormat类来实现合并。
网易云大数据面经
1.ArrayList和linkedlist的区别,他们是不是安全的?
都是list接口的实现类,区别:
ArrayList:是线性表;随机访问比较快,如get和set;线程不安全,都是单线程的,需要实现同步代码块。
LinkedList:是链表数据结构;有指针,所以插入和删除较快;线程不安全。
2.如何解决不安全问题?
ArrayList和LinkedList:使用synchronize关键字,可直接使用Collections.synchronize()方法。
3.多线程有几种同步方式?
多线程的两种实现方法:继承Thread类;实现Runnable接口。
同步实现:①synchronize关键字修饰或者代码块;②使用特殊变量volatile修饰实现,免锁机制;
③使用重入锁实现,类似synchronized;④使用ThreadLocal管理变量,变为局部变量。
4.volatile的用法,和他的作用?
volatile关键字为域变量提供了免锁机制,每次使用该域都会重新计算。
就是在命名变量时,用volatile进行修饰,后面不再用synchronize。
5.线程池机制,如果有高并发的请求出现如何处理?
机制: 预先创建线程,放入空闲队列,然后对这些资源重复利用,可执行多个任务。避免过度消耗资源。
高并发时:请求入库,由线程池执行后续任务。
6.hm底层原理,如何扩容的,和ht的区别?
原理:首先通过hash算法计算key在数组中的位置,然后放入Entry中,如果位置上已经有元素了,就会放在链表的头上。
扩容:即数组扩大机制,每次翻倍,然后重新计算位置。
区别看第一题。
7.悲观锁和乐观锁讲一下,lock和synchronize是悲观锁还是乐观锁?乐观锁里的cas了解吗?
乐观锁:总认为不会产生并发问题,每次去取数据的时候总是认为不会有其他线程对数据进行修改,因此不会上锁,但是在更新时会判断其他线程有没有对数据进行了修改,一般会使用版本号version和CSA(存、预期、新)判断。
悲观锁:总是假设最坏的情况,每次取数据时,都会认为被其他线程修改了,所以都会加锁(读锁,写锁,行锁),当其他线程访问数据的时候,都要阻塞挂起。lock和synchronize就是悲观锁。
CAS:即compare and set,涉及到数据的内存值,预期值,新值。但需要更新的时候,判断当前内存值和之前取到的值是否相等,若相等,用新值更新,若失败则重试,一直循环。
8.面向对象的三大特性和六大原则.?
三大特性:封装,继承,多态,抽象
六大原则:单一功能、可开放和封闭、子可替换父、上下依赖、接口分离、最小依赖。
9.数据库的四大特性?
关系型数据库:ACID A:原子性(不可分割) C:一致性(事务一致) I:隔离性(各表互不影响) D:持久性(执行后不可恢复)
10.MySQL数据库有几种索引方式?索引的底层数据结构是什么?还知道哪些索引?
索引方式:普通索引(index),唯一索引(unique),主键索引(primary key),组合索引,全文索引(fulltext)。
结构:B -Tree(二叉树)、B+Tree(红黑树)
11,假设t表有abcdef字段,有以下需求:select a,b,c from t where a=1and c>1
select a,b,c from t where a>1 and c<1时,
如何建立索引?
12.Redis数据库讲一下应用案例?
它使用内存提供主存储支持,而仅使用硬盘做持久性的存储;它的数据模型非常独特,用的是单线程。另一个大区别在于,你可以在开发环境中使用Redis的功能,但却不需要转到Redis。
13.中间件里的kafka了解吗?
通过O(1)的磁盘数据结构提供消息的持久化;支持Hadoop并行数据加载。
14.大数据里的MapReduce讲一下?
数据输入--拆分---map键值--输出键值--打散重分--map键值--输出键值。
15.Linux里用过哪些命令?用怎么搭建一个简单服务器?
搭建服务器步骤:利用Tomcat和eclipse--》新建工程项目--》编写servlet,继承httpservlet-->web.xml中配置servlet和servlet.mapping映射--》运行,获取网页。
简单搭建:启动IIS(Internet information service)--》准备一个HTML文件,命名.htm,放在本地路径--》浏览器打开ip或者localhost。
java大数据开发面试
一。java基础
1.java接口和抽象类的区别?
抽象类:不能被实例化,是对共同属性和方法的抽取,作为子类继承的对象。只能继承一个,实现多个接口。
接口:是抽象方法的集合,子类实现接口。只能用public修饰,可以继承多个接口。
2.java实现多线程的方法?
继承Thread类实现、实现Runnable接口、实现Collable接口 通过FutureTask包装器来创建Thread线程、使用ExecutorService、collable、Future实现有返回结果的线程。
3.n个线程访问N个资源同步的方法?
首先:多线程死锁的四个必须因素:互斥性、保持和请求、不可剥夺性、形成闭环。
破坏其中之一即可不发生死锁。最简单方法:指定锁的顺序,并强制线程按照指定顺序获取锁,因此所有线程都是以同样的加锁和释放锁,就不会出现死锁。
二。Linux
1.Linux内存管理机制(表示范围太大)?
Linux内存分为物理内存和虚拟内存,是分页存储机制,Linux会时不时进行页面交互操作,根据自身算法,将物理内存不常使用的清除,以便物理内存有更多的空闲;
2.Linux的内核空间讲一下?
Linux的操作系统和驱动程序运行在内核空间,应用程序运行在用户空间,两者不能简单的使用指针传递,因为Linux使用时虚拟内存机制,用户空间数据可能被换出,当内核空间使用用户空间指针的时候,对应数据可能不在内存中。
3.共享内存如何实现?
4.什么是函数调用?系统调用?
网易大数据面经
1.def三个线程在abc三个线程后运行如何实现?
思路:创建只有一个线程的线程池,来操作不限数量的线程队列,队列是按照先进先出的原则,所以这样只会有一个线程在执行,当一个线程完成之后,下一个线程继续,知道所有线程结束,但线程池不会关闭,会处于等待状态,直到shutdown才会关闭。
代码如下:
public class onlyPoll(){
public static void main(string[] args){
//创建三个线程 ,分别打印abc
Thread a=new Thread(new Runnable(){
public void run(){
System.out.println(Thread.currentThread.getName+"A")
}
});
//依次复制上面为B C 线程
//创建线程池 ,将线程分别放入,形成一个队列
ExcutorService excutor=Excutors.newSingleThreadExcutor();
excutor.submit(a);
excutor.submit(b);
excutor.submit(c);
//结束线程池
excutor.shutdown();
}
}
2.消息队列?
是消息传输过程中保存消息的容器。通过异步请求,来缓解连接的压力。
3.设计模式,手写你认为最安全的单例模式?
4.数据库索引?
5.B+树 画出来。说说优点?
6.数据库引擎?
7,聚集索引和非聚集索引?
8.查询条件or能不能走索引,原因?
9。栅栏和闭锁的区别和原理?
10.synchronize的原理?
11.aqs原理?
12.锁的优化(偏向锁怎么实现)?
13.如何查看索引状态?
14、java异常的继承模式?
15.java线程池?
16,用户连续登陆三天或五天,会给用户送积分,问数据库怎么设计以及程序怎么实现?
360,阿里面经
1.tcp和udp区别?
2.http和https 区别?
3.HTTPS的具体工作原理?
4.什时候应该建立索引?注意事项?
5.海量数据分页显示的实现?
6.单例模式?
7.进程和线程?
8.线程状态,具体怎么运行的?
9.Redis的数据结构?
10.Redis是基于内存吗?
11.Redis的list zset的底层实现?
12.跳表?
13.数组和链表的区别?
14,异步队列的实现?
15.怎么设置缓存的失效时间?
16.怎么更新失效缓存?
17.nio原理?
18,静态方法内部能不能调用非静态方法?
19.jdk1.8的新特性?
20.继承和组合?
21.判断数是不是2的幂次方?
22.判断两个单链表是否相交?
23.topk要求时间复杂度?
24.把一个数组中的空格移到最后,不改变相对次序?
