作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
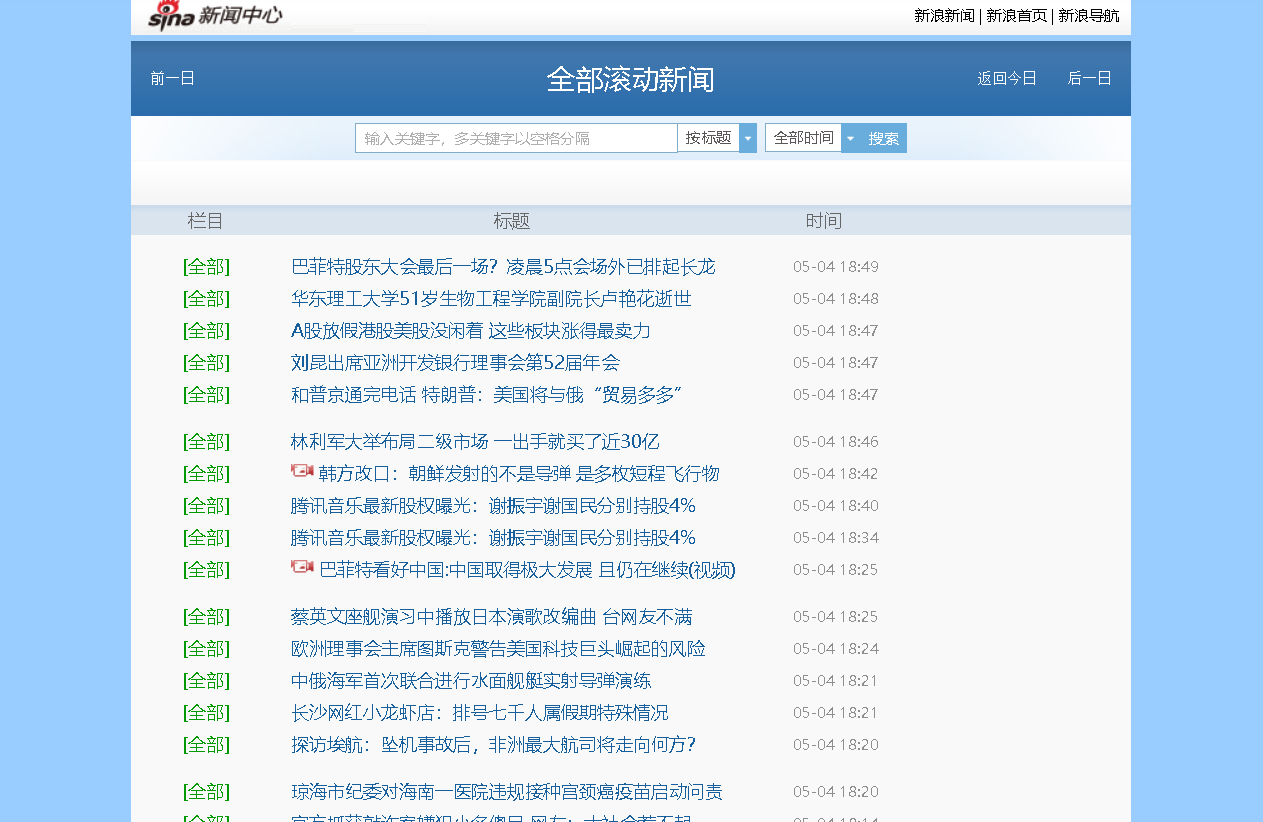
爬去主题:新浪滚动新闻中心
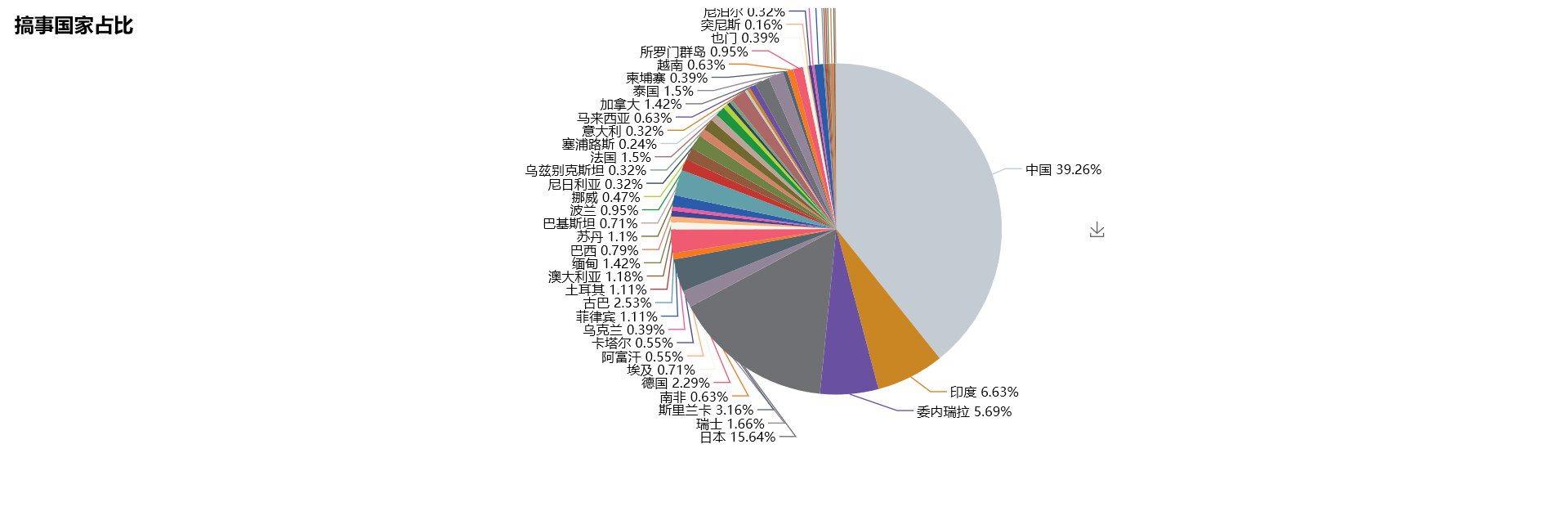
新闻太多条,于是不想看新闻,但是又想要大概了解某段时间大概发生了什么事
2.爬取对象:滚动新闻中心的新闻标题、日期、时间
爬取网址可由日期来区分:http://roll.news.sina.com.cn/s/channel.php?ch=01#col=89&spec=&type=&date=2019-05-04&ch=01&k=&offset_page=0&offset_num=0&num=60&asc=&page=
输入了相应的日期就会生成相应日期内的新闻
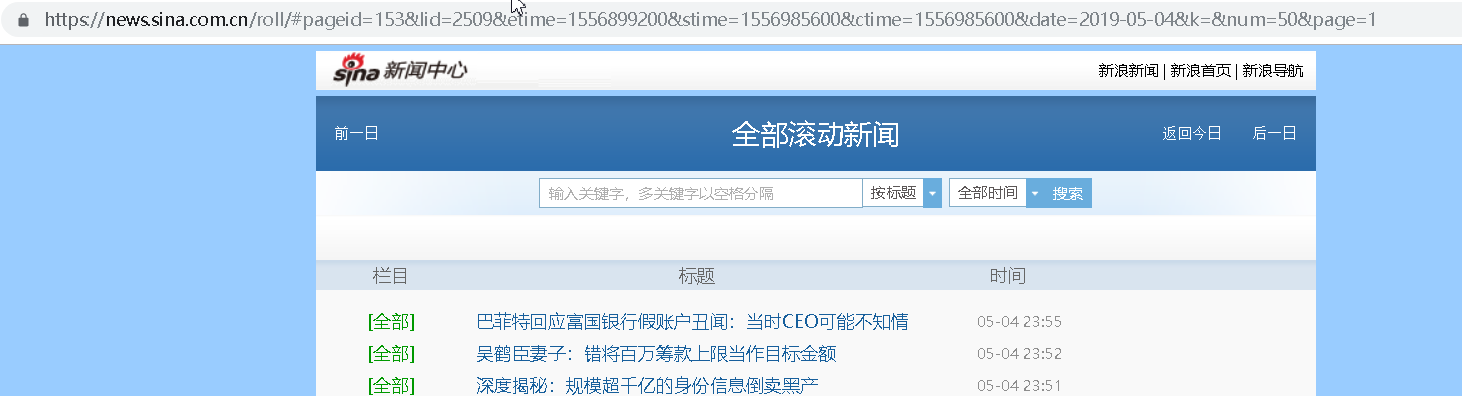
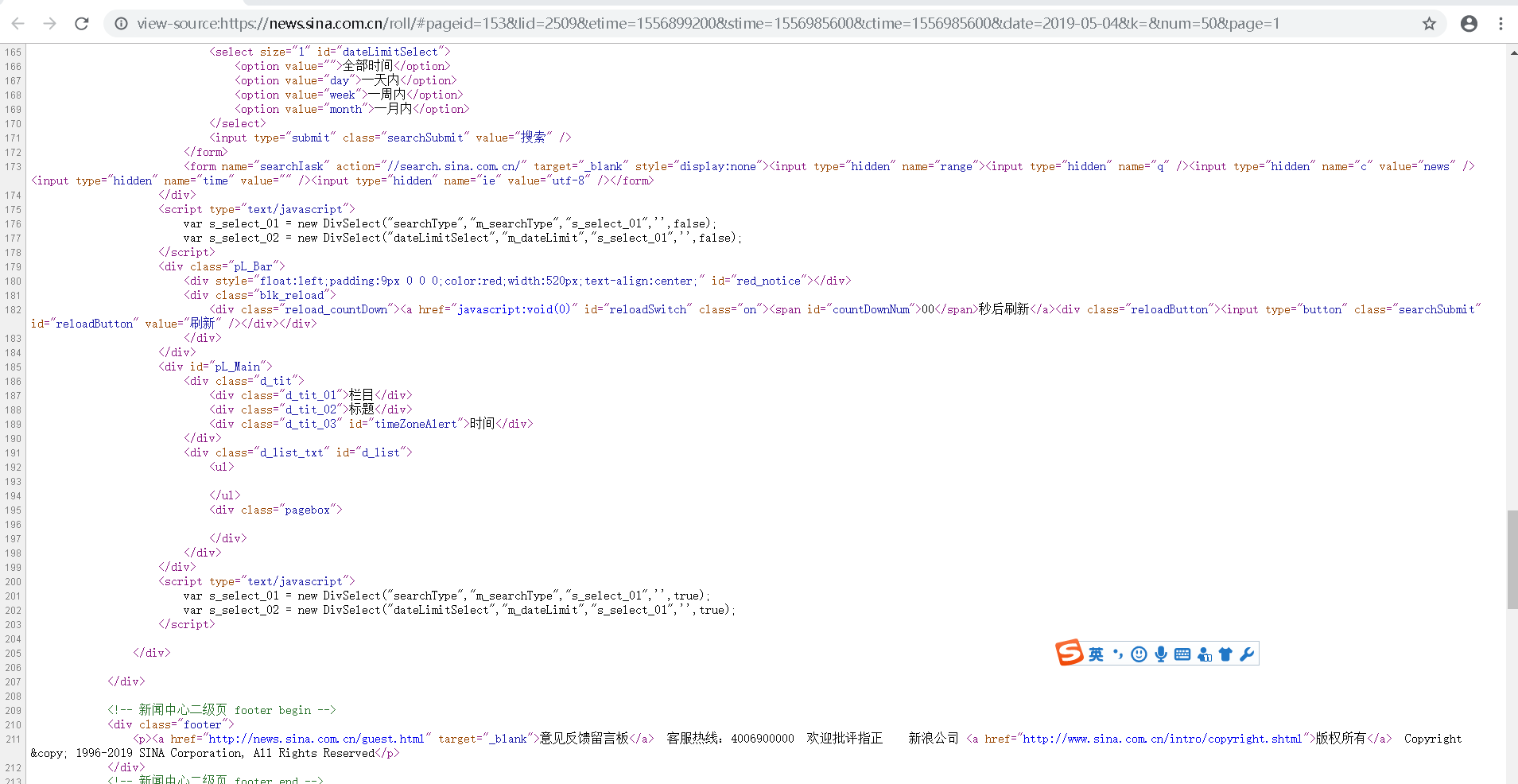
3.了解爬取对象的限制与约束:新浪网的源代码并没有直接显示出爬取内容,导致用requests获取的源代码无法分析出想要的数据
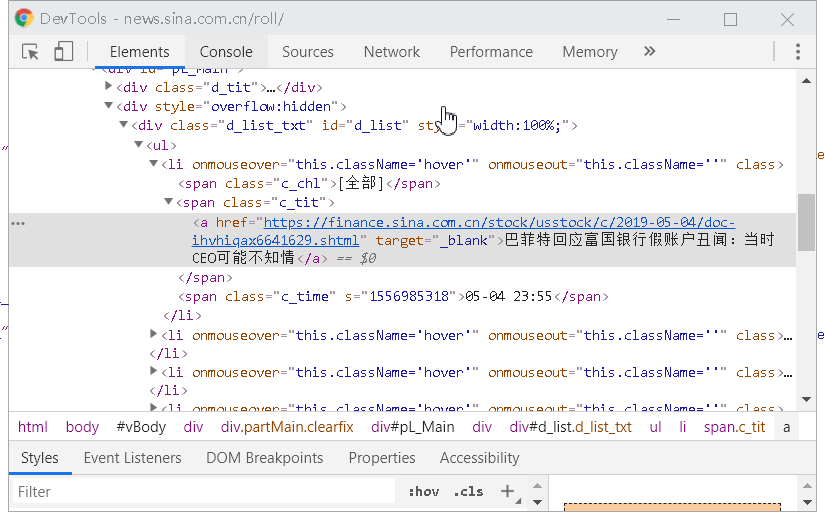
解决办法:用selenium的webdriver xpath直接进行定位
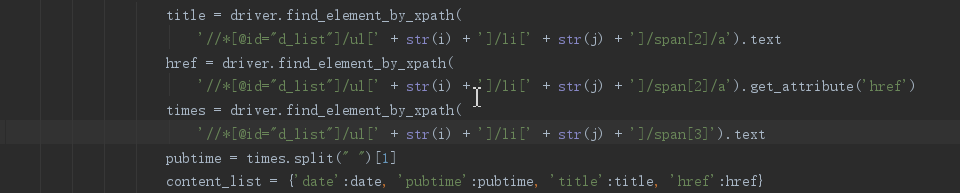
4.爬取相应内容:
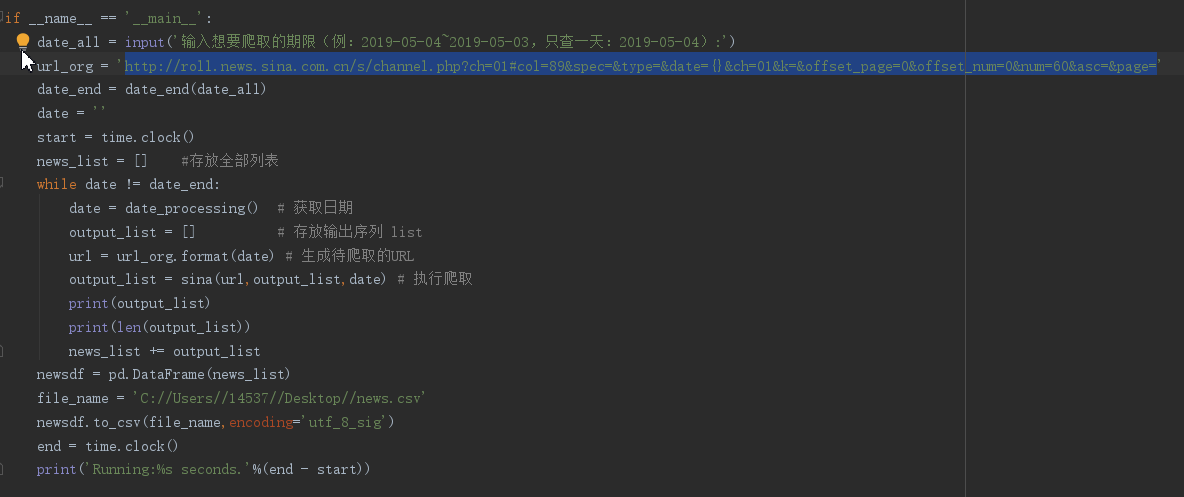
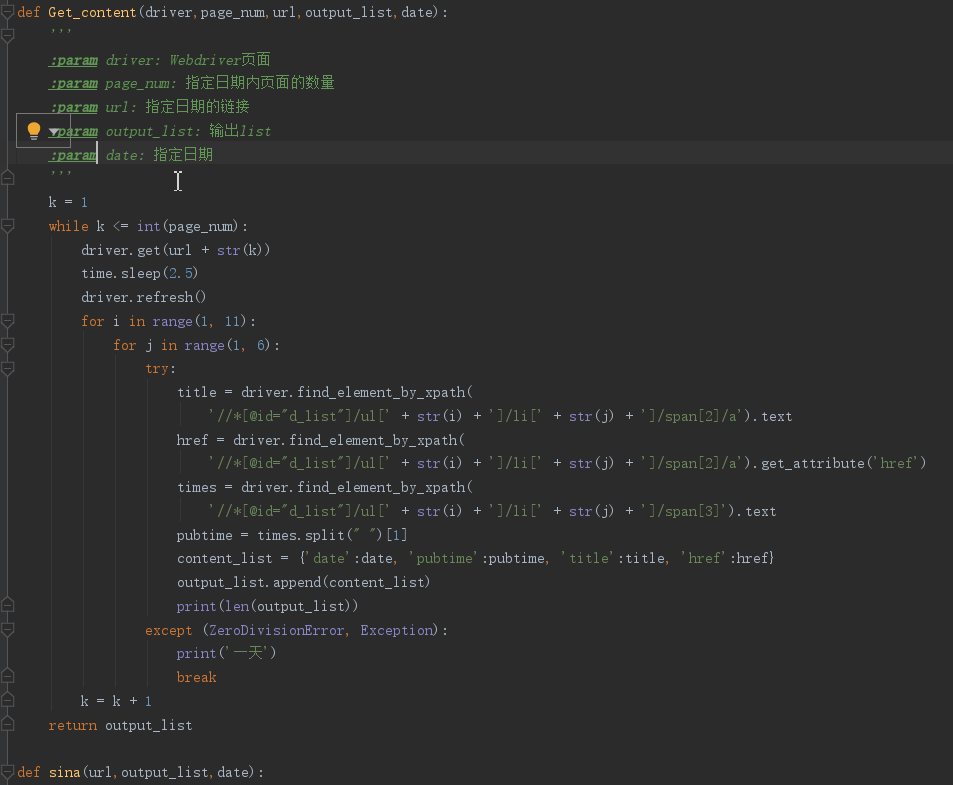
爬取到的评论信息:日期、网址、发布时间、新闻标题

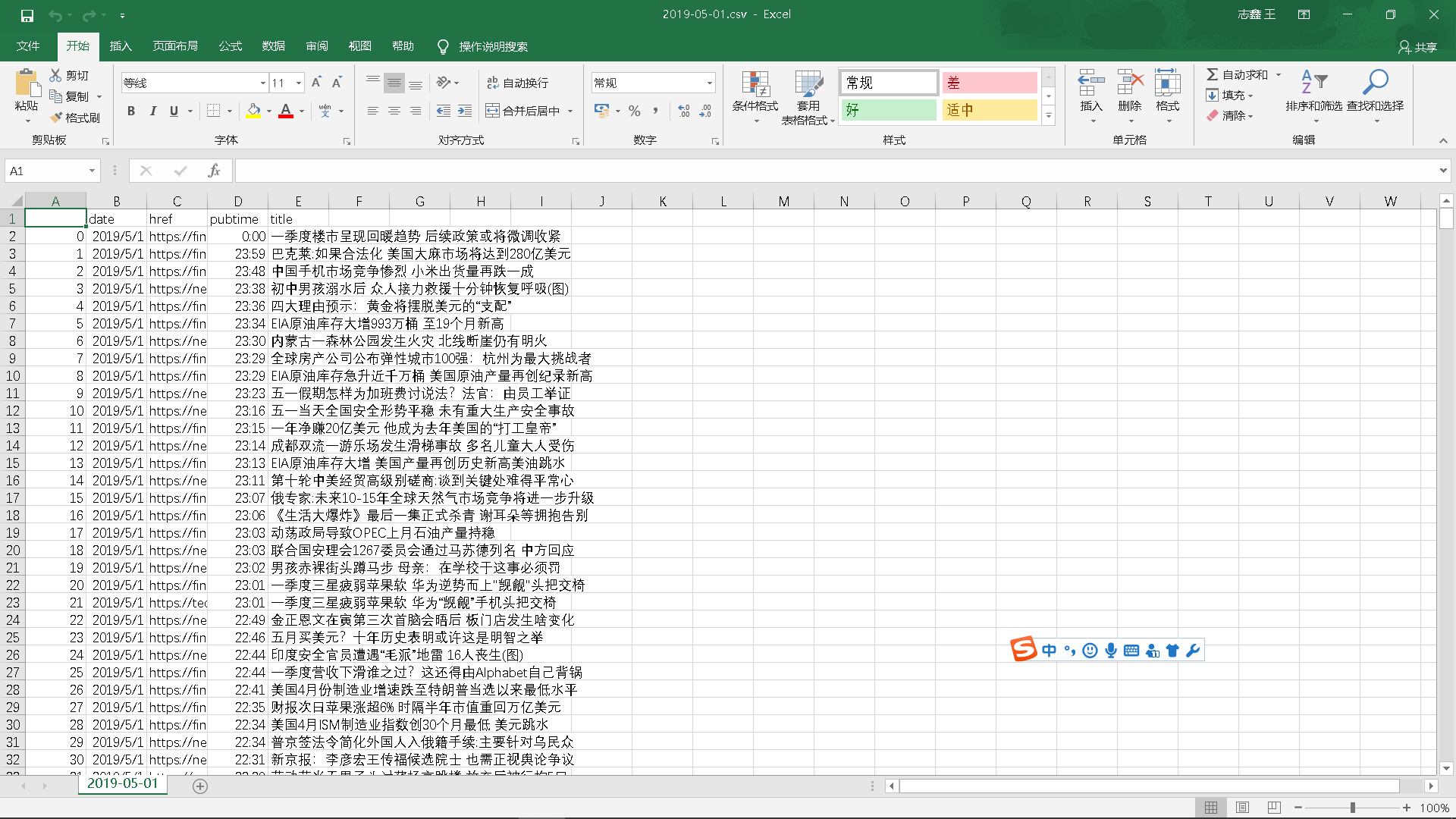
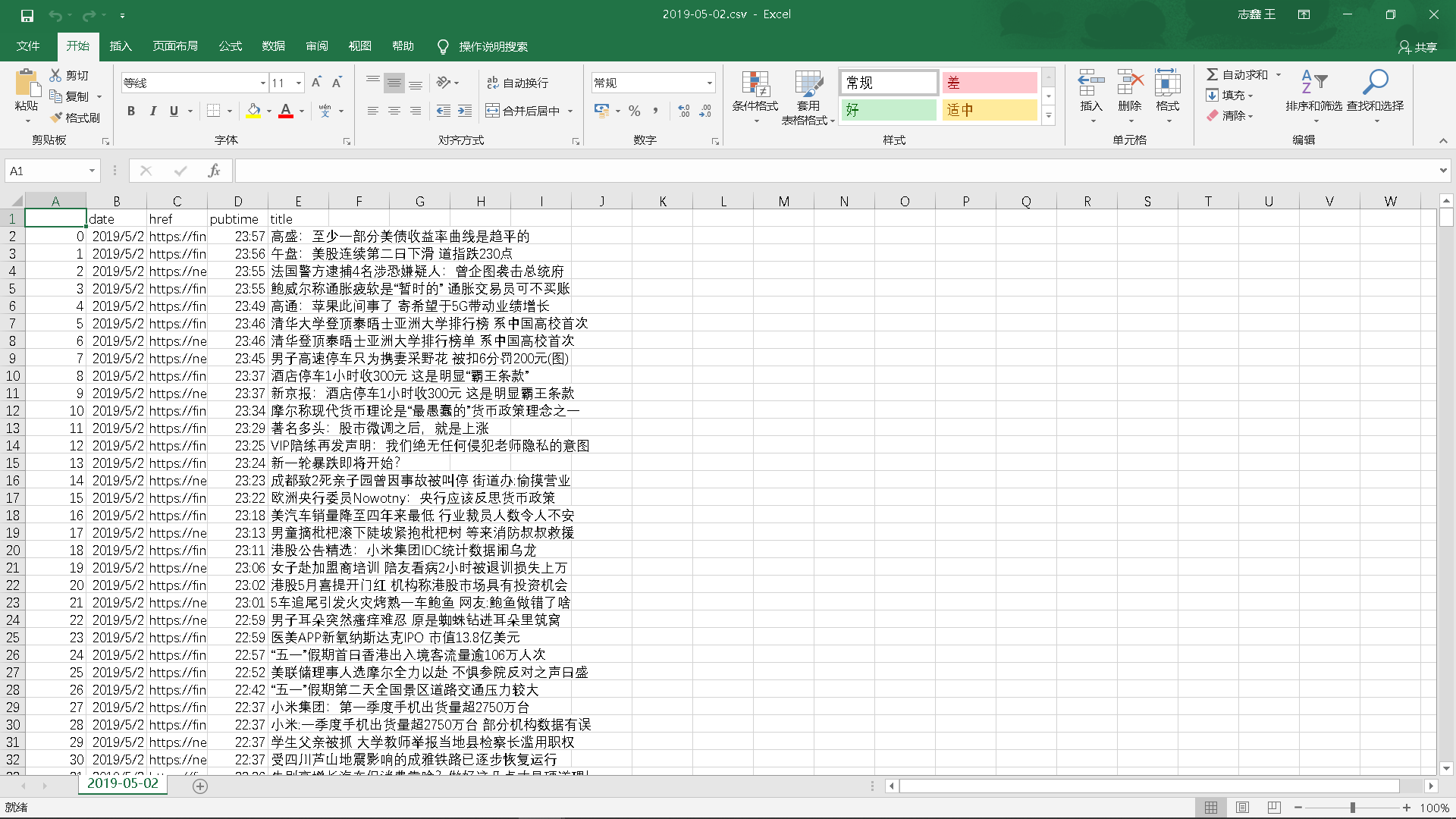
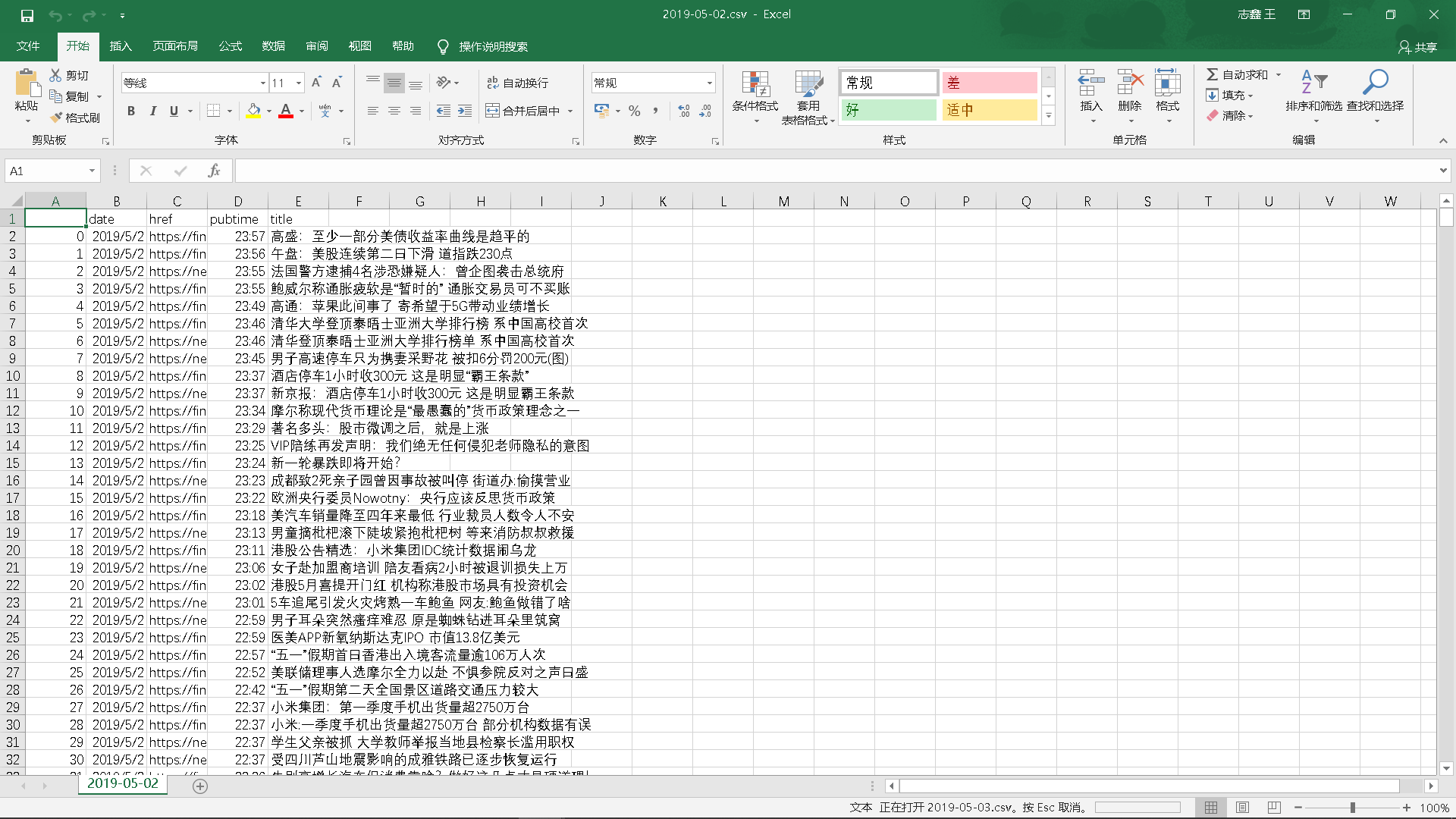
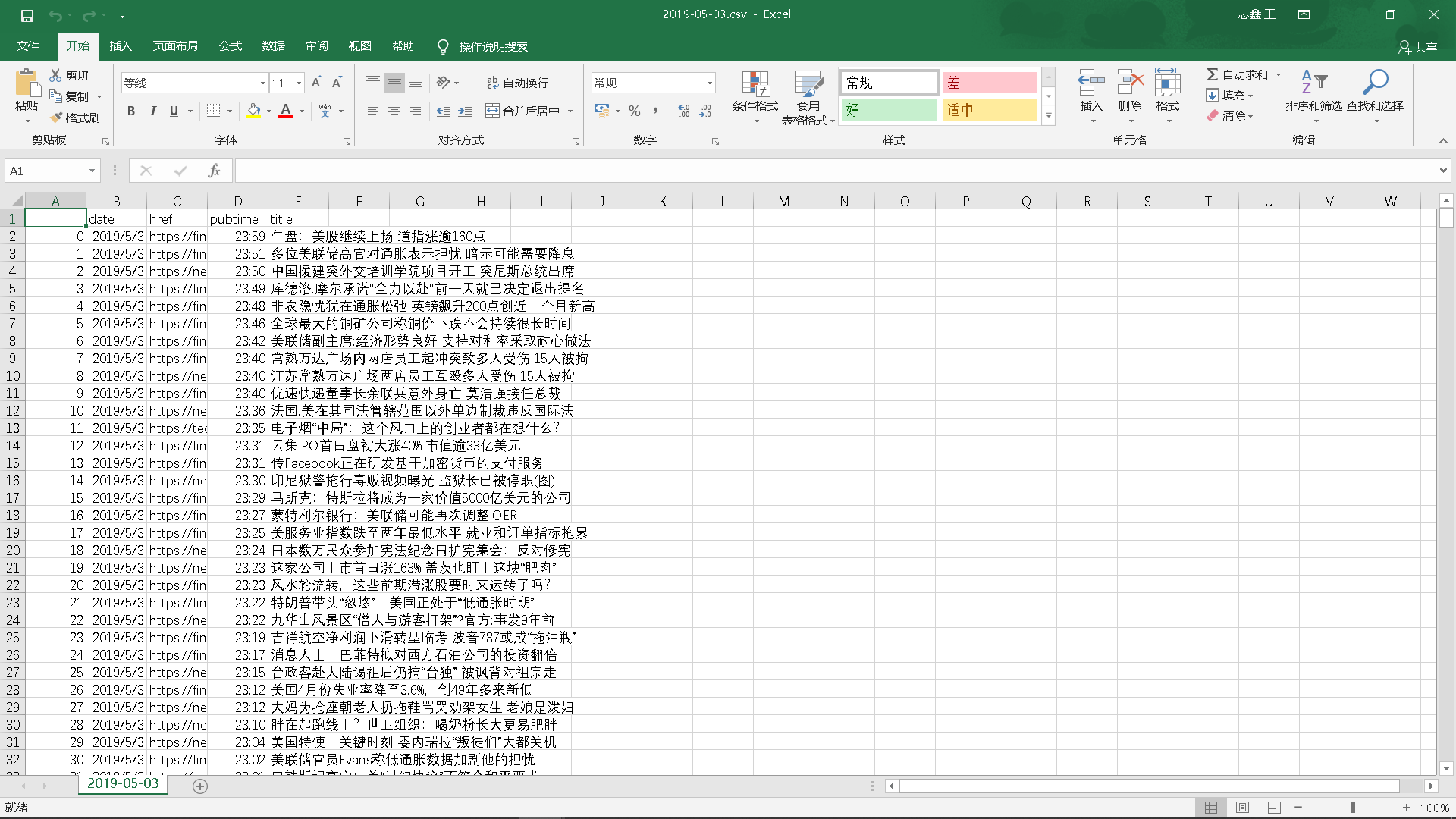
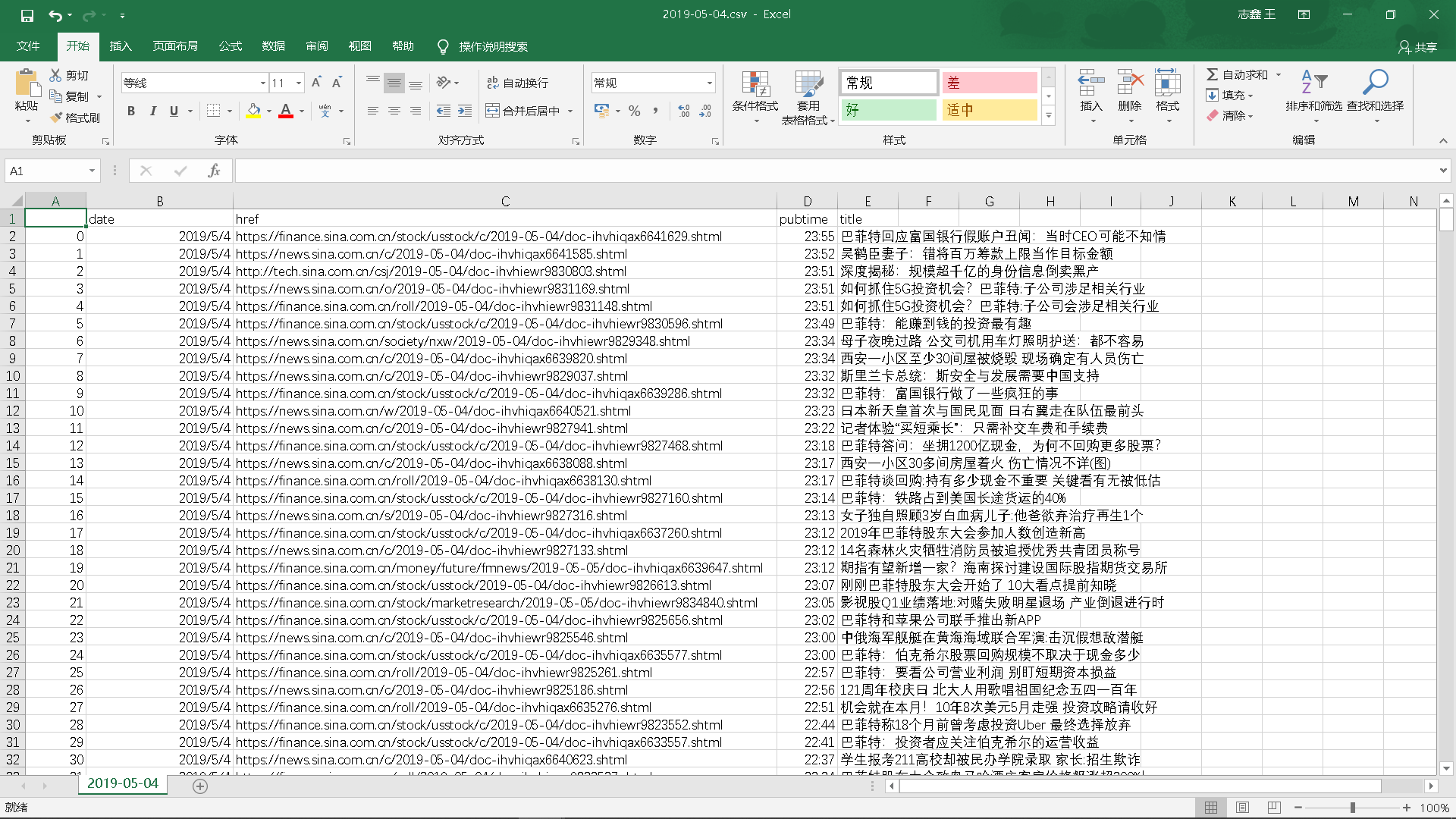
5.做数据分析与文本分析
1 import jieba 2 from scipy.misc import imread 3 import matplotlib.pyplot as plt 4 import pandas as pd 5 from wordcloud import WordCloud 6 import csv 7 import jieba 8 9 day = ['2019-05-01','2019-05-02','2019-05-03','2019-05-04'] 10 all_list=[] 11 row = [] # 每行的列组 12 column=[] # 标题的列组 13 times = [] # 时间的列组 14 for i in day : 15 path = 'C://Users//14537//Desktop//{}.csv'.format(i) 16 file = open(path, 'r',encoding='utf-8') 17 lines = file.readlines() 18 file.close() 19 20 for line in lines: 21 row.append(line.split(',')) 22 for col in row: 23 column.append(col[4]) 24 times.append(col[3]) 25 26 # print(times) 27 28 title = " ".join(str(i).strip('\n') for i in column) 29 30 # print(title) 31 jieba.load_userdict(r'D:\大三(2)\python\xinwen\国外货币译名.txt') #词库文本文件 32 jieba.load_userdict(r'D:\大三(2)\python\xinwen\股票基金名称集合.txt') 33 jieba.load_userdict(r'D:\大三(2)\python\xinwen\联合国成员国名单.txt') 34 text = jieba.lcut(title) 35 # print(text) 36 37 with open(r"C:\Users\14537\Desktop\stops_chinese.txt",'r',encoding="utf-8")as f: 38 stops = f.read().split('\n') 39 tokens = [token for token in text if token not in stops] 40 # print(len(tokens),len(text)) 41 42 # print(tokens) 43 cut_text = "".join(tokens) 44 cut_text = cut_text.strip('\n').strip(' ').strip('title') 45 # print(cut_text) 46 47 ZiDian = {} 48 49 for str in times: 50 str = str.strip('pubtime') 51 if str in ZiDian.keys(): 52 ZiDian[str] = ZiDian[str] + 1 53 else: 54 ZiDian[str] = 1 55 ZiDian.pop('') 56 a2 = sorted(ZiDian.items(), key=lambda x: x[0]) 57 # print(a2) 58 59 60 im = imread(r'D:\大三(2)\python\xinwen\xinwen.jpg') 61 mywcl = WordCloud(background_color='white',mask=im,width=8000,height=4000,margin=2,max_font_size=150,max_words=2000,font_path='simsun.ttc').generate(cut_text) 62 63 64 plt.imshow(mywcl) 65 plt.axis("off") 66 67 plt.show() 68 mywcl.to_file(r'C:\Users\14537\Desktop\xinwen.png') 69 70 xZou = [] 71 yZou = [] 72 for i in a2: 73 xZou.append(i[0]) 74 yZou.append(i[1]) 75 76 # print(xZou) 77 # print(yZou) 78 79 from pyecharts import Bar 80 pie=Bar("发布时间",width=1000) 81 pie.add('比例情况',list(xZou), list(yZou)) 82 pie.render('.\搞事时间柱状图.html')
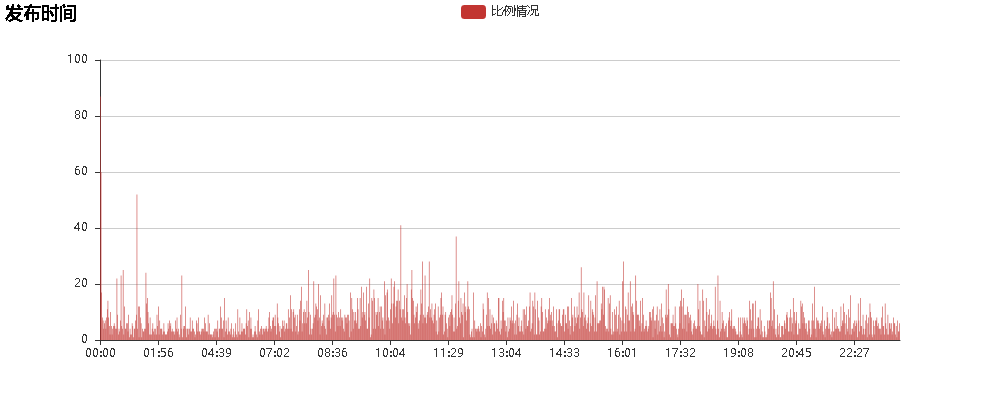
生成词云和柱状图: