
Hadoop和Hive的关系
Hadoop和Hive的关系
1.Hadoop是一个能够对大量数据进行分布式处理的软件框架。Hadoop最核心的设计就是hdfs和mapreduce,hdfs提供存储,mapreduce用于计算。
2.Hive是Hadoop的延申。hive是一个提供了查询功能的数据仓库核心组件,Hadoop底层的hdfs为hive提供了数据存储,mapreduce为hive提供了分布式运算。
两者的关系:
hdfs上存储着海量的数据,我们要对这些数据进行计算和分析,则需要使用Java编写mapreduce程序来实现,但Java编程门槛较高,且一个mapreduce程序写起来要几十上百行。
Hive可以直接通过sql操作Hadoop,sql简单易写,可读性强,hive将用户提交的sql解析成mapreduce任务供Hadoop直接运行。过程如下图所示:
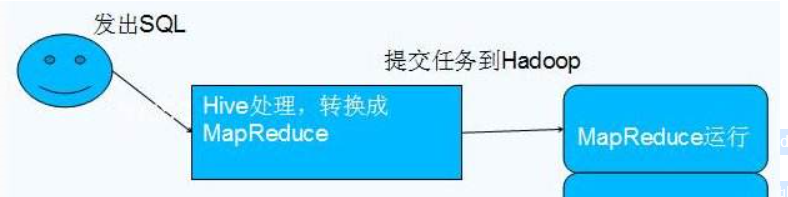
拓展:
1.hive不存储数据,hive只是对数据进行分析计算,以及计算后的结果数据实际存放在分布式系统上,如HDFS;
2.hive某种程度来说也不进行数据计算,只是个解释器,只是将用户需要对数据处理的逻辑,通过sql编程提交后解释成mapreduce程序,然后将这个MR程序提交给yarn进行调度执行。所以实际进行分布式运算的是mapreduce程序。
3.因为hive需要操作hdfs上的数据集,那么它需要知道数据的切分格式,如行列分隔符,存储类型,是否压缩,数据的存储地址等信息。
内容来源:https://blog.csdn.net/weixin_43222191/article/details/126829112


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现