

淘宝商品信息定向爬虫.py(亲测有效)


import requests import re def getHTMLText(url): try: kv = { 'cookie': '', #要换成自己网页的cookie 'user-agent':'Mozilla/5.0' # 请求头;指定访问浏览器为Mozilla5.0版本的浏览器 } r = requests.get(url,timeout=30,headers=kv) r.encoding = r.apparent_encoding return r.text except: return "" def parsePage(ilt,html): try: plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) tlt = re.findall(r'\"raw_title\"\:\".*?\"',html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) # eval函数去掉最外层的单引号,双引号 title = eval(tlt[i].split(':')[1]) ilt.append([price,title]) except: print("") def printGoodsList(ilt): tplt = "{:4}\t{:8}\t{:16}" print(tplt.format("序号","价格","商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count,g[0],g[1])) def main(): goods = '书包' depth = 2 start_url = 'https://s.taobao.com/search?q=' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44*i) html = getHTMLText(url) parsePage(infoList,html) except: continue printGoodsList(infoList) main()
查找自己cookie的步骤如下:
(1)进入淘宝页面
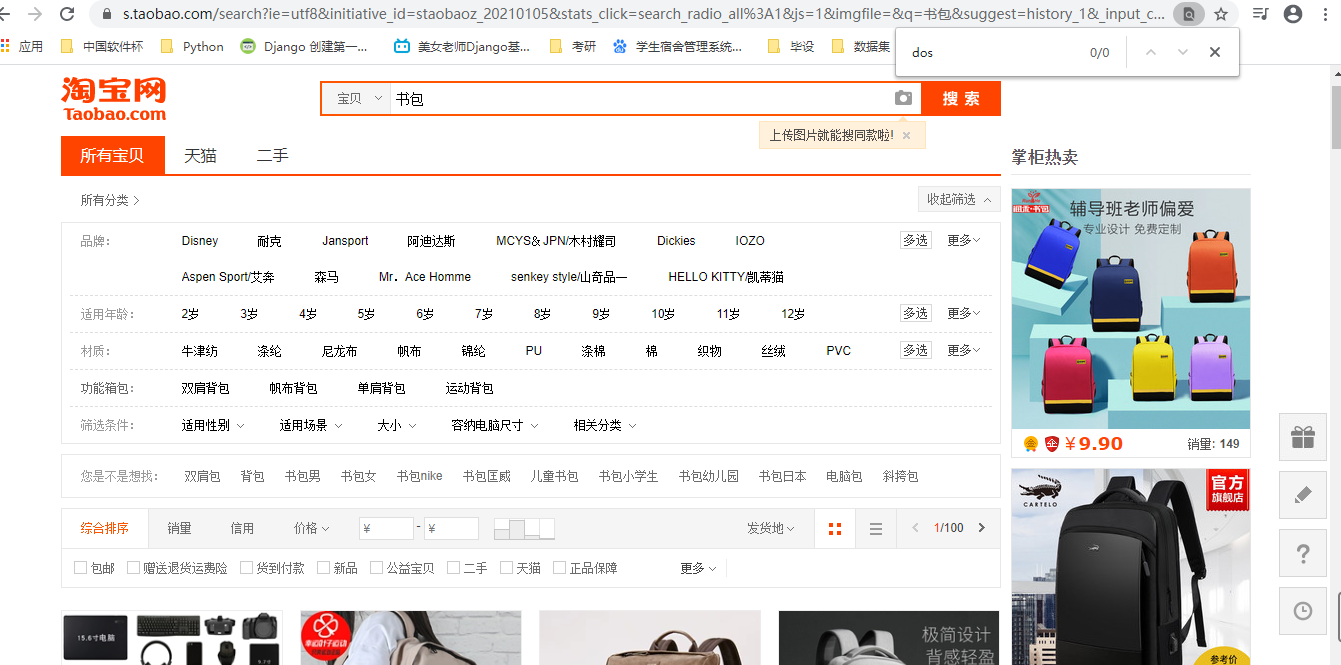
(2)按下F12,刷新页面,点击最上面的NetWork,找到下面文件
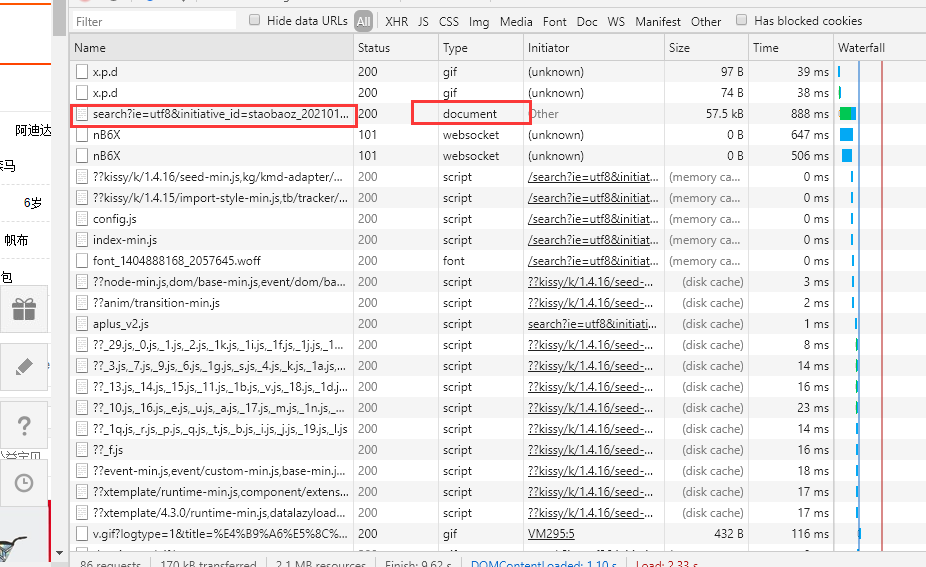
(3)找到RequestHeaders,找到里面的Cookie复制即可

