Linux的NUMA机制
NUMA(Non-Uniform Memory Access)字面直译为“非一致性内存访问”,对于Linux内核来说最早出现在2.6.7版本上。这种特性对于当下大内存+多CPU为潮流的X86平台来说确实会有不少的性能提升,但相反的,如果配置不当的话,也是一个很大的坑。本文就从头开始说说Linux下关于CPU NUMA特性的配置和调优。
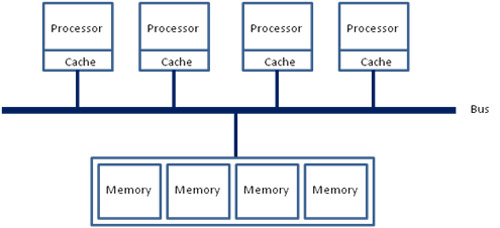
在若干年前,对于x86架构的计算机,那时的内存控制器还没有整合进CPU,所有内存的访问都需要通过北桥芯片来完成。此时的内存访问如下图所示,被称为UMA(uniform memory access, 一致性内存访问 )。这样的访问对于软件层面来说非常容易实现:总线模型保证了所有的内存访问是一致的,不必考虑由不同内存地址之前的差异。
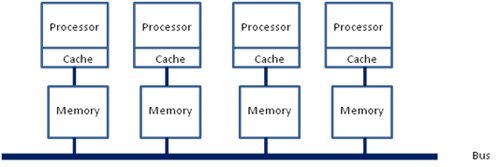
之后的x86平台经历了一场从“拼频率”到“拼核心数”的转变,越来越多的核心被尽可能地塞进了同一块芯片上,各个核心对于内存带宽的争抢访问成为了瓶颈;此时软件、OS方面对于SMP多核心CPU的支持也愈发成熟;再加上各种商业上的考量,x86平台也顺水推舟的搞了NUMA(Non-uniform memory access, 非一致性内存访问)。
在这种架构之下,每个Socket都会有一个独立的内存控制器IMC(integrated memory controllers, 集成内存控制器),分属于不同的socket之内的IMC之间通过QPI link通讯。
然后就是进一步的架构演进,由于每个socket上都会有多个core进行内存访问,这就会在每个core的内部出现一个类似最早SMP架构相似的内存访问总线,这个总线被称为IMC bus。
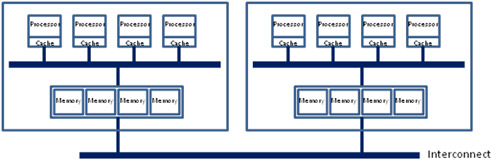
于是,很明显的,在这种架构之下,两个socket各自管理1/2的内存插槽,如果要访问不属于本socket的内存则必须通过QPI link。也就是说内存的访问出现了本地/远程(local/remote)的概念,内存的延时是会有显著的区别的。
——————————————————————————————————————————————————————————————————————————————————————————————————————
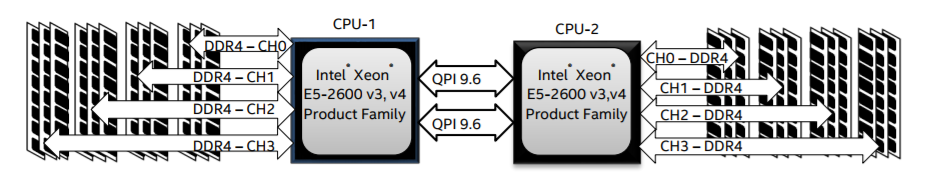
回到当前世面上的CPU,工程上的实现其实更加复杂了。以Xeon 2699 v4系列CPU的标准来看,两个Socket之之间通过各自的一条9.6GT/s的QPI link互访。而每个Socket事实上有2个内存控制器。双通道的缘故,每个控制器又有两个内存通道(channel),每个通道最多支持3根内存条(DIMM)。理论上最大单socket支持76.8GB/s的内存带宽,而两个QPI link,每个QPI link有9.6GT/s的速率(~57.6GB/s)事实上QPI link已经出现瓶颈了。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Linux提供了一个一个手工调优的命令numactl(默认不安装),在Centos7.0上的安装命令如下
[root@realhost /]# yum -y install numactl
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
iso | 3.6 kB 00:00:00
Resolving Dependencies
--> Running transaction check
---> Package numactl.x86_64 0:2.0.12-3.el7 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
==============================================================================================================================================================================================================
Package Arch Version Repository Size
==============================================================================================================================================================================================================
Installing:
numactl x86_64 2.0.12-3.el7 iso 65 k
Transaction Summary
==============================================================================================================================================================================================================
Install 1 Package
Total download size: 65 k
Installed size: 141 k
Downloading packages:
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : numactl-2.0.12-3.el7.x86_64 1/1
Verifying : numactl-2.0.12-3.el7.x86_64 1/1
Installed:
numactl.x86_64 0:2.0.12-3.el7
Complete!
首先你可以通过它查看系统的numa状态
[root@realhost /]# numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3
node 0 size: 1023 MB
node 0 free: 147 MB
node distances:
node 0
0: 10
可以看到,此系统共有1个node(因为是跑在windows上的虚拟机),共有1170M内存
这里假设我的虚拟机有多个node ,并且我要执行一个java param命令。最好的优化方案时python在node0中执行,而java在node1中执行,那命令是
numactl --cpubind=0 --membind=0 python param
numactl --cpubind=1 --membind=1 java param
numactl 命令详解
语法:
numactl [--interleave nodes] [--preferred node] [--membind nodes]
[--cpunodebind nodes] [--physcpubind cpus] [--localalloc] [--] {arguments ...}
numactl --show
numactl --hardware
numactl [--huge] [--offset offset] [--shmmode shmmode] [--length length] [--strict]
[--shmid id] --shm shmkeyfile | --file tmpfsfile
[--touch] [--dump] [--dump-nodes] memory policy
主要参数:
--interleave=nodes, -i nodes
这个选项用于设定内存的交织分配模式。 也就是说系统在为多个节点分配内存空间的时候,将会以轮询分发的方式被分配给这多个节点.
如果在当前众多的交织分配内存节点中的目标节点无法正确的分配内存空间的话,内存空间将会由其他的节点来分配。
--membind=nodes, -m nodes
选项 '--membind' 仅用来从节点中分配内存空间所用。 如果在这些节点中无法分配出所请求的空间大小的话该分配操作将会失败.
上述命令中指定需要分配空间的 nodes 的方式可以遵照上述 N,N,N , N-N ,N 这种方式来指定.
--cpunodebind=nodes, -N nodes
上述命令仅用于施加在运行与 cpu 上的进程。这个命令用于显示 cpu 的个数,cpu 数目信息同样记录在系统中的存放处理器领域信息的 /proc/cpuinfo 文件夹下,
或者是按照关联的中央处理器信息 在当前的中央处理器集中所存放.
--localalloc , -l
这个命令选项通常是为当前的节点分配内存的
--preferred=node
该命令由于指定优先分配内存空间的节点,如果无法将空间分配给该节点的话,应该分配给该节点上的空间将会被分发到其他的节点上
该命令选项后面仅接收一个单独的节点标号. 相关的表示方式也可以使用.
--show,-s
该命令用于显示 NUMA 机制作用在当前运行的那些进程上
--hardware , -H
该命令用于显示当前系统中有多少个可用的节点.
--huge
当创建一个基于大内存页面的系统级的共享内存段的时候,使用 --huge 这个选项。
--huge 选项仅在 --shmid 或是 --shm 命令的后面使用才有效.
--offset
该参数选项用于指定共享内存段中的位移量的偏移。 默认的情况下偏移量是 0 。 有效的偏移量单位是 m (用于表示 MB)
g (用于表示 GB) , k (用于表示 KB ), 其他没有指定的被认为是以字节为单位.
--strict
这个参数选项 当施加了 NUMA 调度机制的共享内存段区域的页面被施加了另一个机制而导致错误的时候,
使用 --strict 选项将会把错误信息显示出来. 默认情况是不使用该选项的。
--shmmode shmmode
该选项仅在 --shmid 或是 --shm 之前使用才会生效。 当创建一个共享内存段的时候,通过整型数值来指定
共享内存的共享的模式类型.
--length length
Apply policy to length range in the shared memory segment or make the segment length long Default is to use the remaining
length Required when a shared memory segment is created and specifies the length of the new segment then .
Valid units are m ( for MB ) , g( for GB) , k ( for KB) , otherwise it specifies bytes.
--shmid id
通过ID 号码来创建或使用一个共享内存段。
(如果共享内存段已经存在,那么通过 shmid 来指定下面要使用某个 ID 的共享内存段 ; 如果该 ID 对应的共享内存段并不存在的话,那么就创建一个)
--shm shmkeyfile
通过存放在 shmkeyfile(共享内存-键文件)中的 ID 号码来创建或者是使用一个共享内存段。
访问 shmkeyfile 文件的进程是通过 fork(3 arguments) 方法来实现的.
--file tmpfsfile
将 numa 机制施加于文件上面, 这个文件属于 tmpfs或者是 hugetlbfs 这种特殊的文件系统
--touch
通过将 numa 机制施加于刚刚页面上来实现内存的早期 numa 化。
默认情况下是不使用该选项,如果存在映射或是访问页面的应用的话,将会使用该早期实行 NUMA 机制的这种方法.
--dump
该选项用于废除将已经 numa 化的特定区域上的 NUMA性质.
(--dump ) 选项后,有效指定 node 的书写方式
all 用于将所有的节点上的 NUMA 特性移除
number 通过指定 node 后接的数值来废除该数字对应的 node
number1(number2) node number1(node number2)上的 NUMA 特性将会被移除
number1-number2 node number1 -- node number2 区间上的所有存在的 node 的 NUMA 特性将会被移除
!nodes 除了 nodes 所指定的节点以外的所有节点上的 NUMA 特性全都会被移除

