应用层的容错与分层设计
针对在项目中碰到的一些容错设计问题,团队最近进行了一次技术沙龙,讨论了以下话题。
为什么需要应用层的容错设计?
一个完整的系统在内部是由很多小服务构成,服务之间以及服务与资源之间会存在远程调用。
-
每个系统的可用性不可能达到100%
-
各种网络及硬件问题,如网络拥堵、网络中断、硬件故障……
-
远程服务平均响应速度变慢
服务器平均响应速度如果慢下来,慢慢消耗掉系统所有资源,进而导致整个系统不可用。因此在分布式系统中,除了远程服务本身需要有容错设计之外,在应用层的远程调用的环节,需要有良好的容错设计。
应用层的容错设计有哪些方法?以下是微博团队使用过的一些实践。
访问MySQL的容错设计
-
写操作:如果master异常,直接抛异常。
-
读操作:如果slave有多个,先选择其中一个slave,如果获取连接失败,再选择其他的slave,如果全部不可用,最后选择master。
访问Memcached/Redis的容错设计
首先设置so_timeout,避免无限制等待;服务器连接如果IO异常,设置错误标志,一段时间停止访问;出错后定期主动(比如ping Redis)或被动(当被再次访问时)探测服务是否恢复。
Failover机制:
如果连接某个node失败, 当前pool启用一致性hash切换到backup node;如果backup node没有数据,则通过另外一个服务池(数据副本)获取数据。
访问远程HTTP API的容错设计
设置so_timeout;部分场景:短超时,重试一次;另外由于HTTP service情况的多样性,业务层面还有通用的降级机制。
访问不同资源使用不同方法存在的问题
从上面列举的部分场景来看,在访问不同资源时候,每种client访问都有一些相通的原理,但却要使用不同的重复实现。由于各个client独立实现,实现时候由于各个远程服务协议及行为的差异,导致这些容错原理无法直接复用。另外在代码层面,不同的client也使用了不同年代的一些底层库,一些早期client的实现,数据层,连接层,协议层全部耦合在一起,也造成维护成本进一步加大。
比如之前一些服务开发中碰到的类似如下的问题:
-
hbase-client由于没有实现容错设计,导致访问出现了抖动,影响了同一服务池的其他调用,需要增加类似MySQL client的容错及快速失败策略;
-
MySQL slave流量出现不均衡了,由于多个slave IP之间没有使用公用的负载均衡策略,因此需要重新添加、上线及验证。
另外目前分布式系统中大部分远程资源都是IO bound而不是CPU bound,而client大部分又是同步调用,造成大部分调用都在等待远程返回,同时也消耗了工作线程资源,以及大量线程context switch。
有没有可能统一的client?
这些策略原理上是可以公用的,能否出一个统一的client层来一劳永逸?不过这个需求不是twitter干过吗?
Finagle,不仅是平时理解的RPC框架,还有目标是想成为一个commons client,从另外一个层面,广义上访问远程资源也都可以理解成RPC,所以Finagle也常称为RPC框架。
Finagle implements uniform client and server APIs for several protocols, and is designed for high performance and concurrency.
在Twitter体系,分布式服务可以从future, service, filter三个层次理解,容错、超时、授权、tracing、重试等机制都是体现在filter中;而future则将client从多线程、队列、连接池、资源管理释放出来,从关注控制流到关注数据流。并且默认变成异步方式。
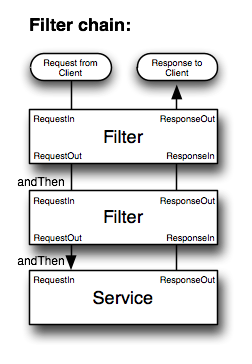
Finagle的FailFast模块会避免分发请求到出现问题的服务,它通过来记录到每个host的错误来进行标记,当出错以后,Finagle会通过一个后台线程定期重连以检查是否恢复。当host宕机时,相关的service会标记成不可用。
如果来redisign一个通用的网络client,它应该包括哪些元素?
-
具有服务的分层设计,借鉴Future/Service/Filter概念
-
具有网络的分层设计,区分协议层、数据层、传输层、连接层
-
独立的可适配的codec层,可以灵活增加HTTP,Memcache,Redis,MySQL/JDBC,Thrift等协议的支持。
-
将多年各种远程调用High availability的经验融入在实现中,如负载均衡,failover,多副本策略,开关降级等。
-
通用的远程调用实现,采用async方式来减少业务服务的开销,并通过future分离远程调用与数据流程的关注。
-
具有状态查看及统计功能
-
当然,最终要的是,具备以下通用的远程容错处理能力,超时、重试、负载均衡、failover……


 浙公网安备 33010602011771号
浙公网安备 33010602011771号