Windows逆向安全(一)之基础知识(七)
汇编C语言类型转换
类型转换
类型转换的使用场景
类型转换一般为由数据宽度小的转换成数据宽度大的,不然可能会有高位数据被截断的现象,引起数据丢失
需要一个变量来存储一个数据,刚开始这个数据的数据宽度较小,后来发现存不下了,需要换一个数据宽度更大的变量来存储
类型转换相关汇编指令
MOVSX
先符号扩展,再传送
MOV AL,0FF
MOVSX CX,AL
MOV AL,80
MOVSX CX,AL
MOVZX
先零扩展,再传送
MOV AL,0FF
MOVZX CX,AL
MOV AL,80
MOVSX CX,AL
类型转换例子
#include "stdafx.h"
int main(int argc, char* argv[])
{
unsigned char i=0xFF;
printf("%d\n",i);
int j=i+1;
i=i+1;
printf("%d\n",i);
printf("%d\n",j);
return 0;
}
我们来看看以上代码的运行结果:

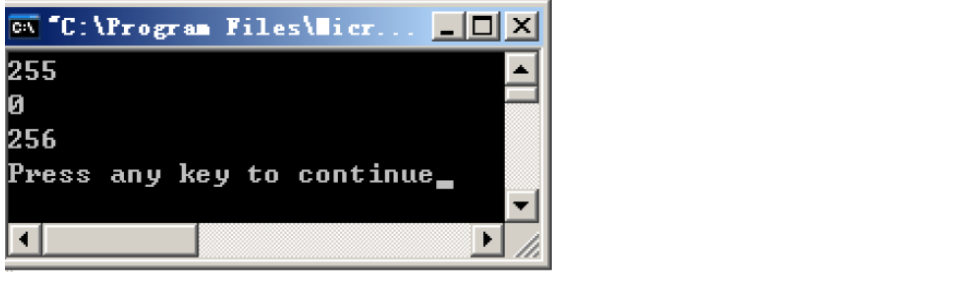
分析结果
首先输出的是一个无符号数 i,0xFF对应的十进制为255
接着输出的是i自增1后的结果,我们发现255+1变成了0,这是因为char的数据宽度为8位,最大便是0xFF了,再加上一就超出了char的数据宽度,也就是发生了上溢。于是数据变成了0
最后输出的是类型转换后i+1的结果,正确地显示为256
汇编观察
汇编代码
大致了解了产生上述结果的原因,用汇编来更透彻地分析:
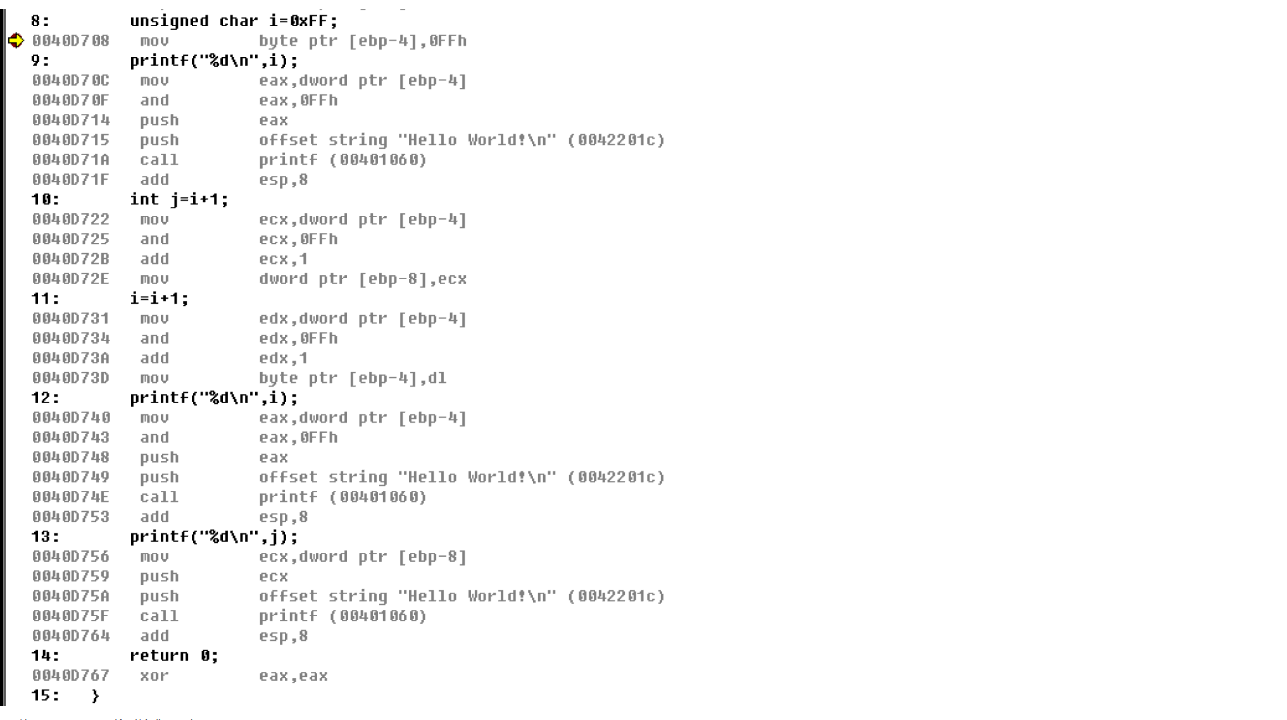
我们这里提取出 去除printf输出的部分,得到汇编代码如下:
8: unsigned char i=0xFF;
0040D708 mov byte ptr [ebp-4],0FFh
10: int j=i+1;
0040D722 mov ecx,dword ptr [ebp-4]
0040D725 and ecx,0FFh
0040D72B add ecx,1
0040D72E mov dword ptr [ebp-8],ecx
11: i=i+1;
0040D731 mov edx,dword ptr [ebp-4]
0040D734 and edx,0FFh
0040D73A add edx,1
0040D73D mov byte ptr [ebp-4],dl
结果有些尴尬,ԾㅂԾ, 我们发现并没有用到前面所说的movsx或movzx指令,但是先不着急,先看看这段汇编代码做了些什么
对应i赋值
很稀松平常的,char对应数据宽度为byte赋值
8: unsigned char i=0xFF;
0040D708 mov byte ptr [ebp-4],0FFh
对应j赋值
接下来就是j的赋值
10: int j=i+1;
0040D722 mov ecx,dword ptr [ebp-4]
0040D725 and ecx,0FFh
0040D72B add ecx,1
0040D72E mov dword ptr [ebp-8],ecx
可以看到:首先是直接将前面的 i 赋值给ecx,并且赋值的长度为dword,很明显将超出char长度的内容也赋值到了ecx
mov ecx,dword ptr [ebp-4]
然后下一句很关键
and ecx,0FFh
与操作,将之前多超出的部分和0相与,也就是将超出的部分全部清零(用零填充),相当于MOVZX指令的零填充
接下来就是加一的操作
add ecx,1
最后就是将ecx赋值给了我们的变量j
mov dword ptr [ebp-8],ecx
对应i=i+1
和前面j的赋值似曾相识,直接将前面i赋值给edx,并且赋值的长度为dword,很明显将超出char长度的内容也赋值到了edx
mov edx,dword ptr [ebp-4]
接着也是与操作,超出来的部分清零
and edx,0FFh
接下来就是加一的操作
add edx,1
最后是赋值
mov byte ptr [ebp-4],dl
将edx的低8位赋值给i
通过前面的分析,可以发现,无论是 i 自己+1还是用数据宽度较高的 j 来接收 i +1的结果
期间都是要先取出超出 i 数据宽度的dword长度的数据,然后再使用and 0xFF,把超出的部分清零
换言之,char的计算也会先转换为int的计算,最后再转回来
还有就是汇编指令并非一成不变,不是一定要使用movsx或movzx指令,也可以通过这种取出超出长度的数据,然后再将超出的部分清零的操作来实现类movzx指令的结果
自写汇编实现功能
前面虽然我们分析了,汇编代码,但很可惜编译器并没有使用movzx指令来实现操作,本着学习巩固的精神,我们自己写汇编来实现上述的功能,以此来加深对movzx的理解
#include "stdafx.h"
unsigned char i=0xFF;
int j=0;
void _declspec (naked) func(){
_asm{
//保留调用前堆栈
push ebp
//提升堆栈
mov ebp,esp
sub esp,0x40
//保护现场
push ebx
push esi
push edi
//初始化提升的堆栈,填充缓冲区
mov eax,0xCCCCCCCC
mov ecx,0x10
lea edi,dword ptr ds:[ebp-0x40]
rep stosd
//函数核心功能
//将i零扩充赋值给ecx
movzx ecx,i
//ecx自增1
inc ecx
//将ecx赋值给j
mov j,ecx
//直接让i自增1
inc i
//恢复现场
pop edi
pop esi
pop ebx
//降低堆栈
mov esp,ebp
pop ebp
//返回
ret
}
}
int main(int argc, char* argv[])
{
printf("%d\n",i);
func();
printf("%d\n",i);
printf("%d\n",j);
return 0;
}
执行后的结果为:

和前面的执行结果一致
上面的代码看似很多,其实核心功能就只有四句:
//函数核心功能
//将i零扩充赋值给ecx
movzx ecx,i
//ecx自增1
inc ecx
//将ecx赋值给j
mov j,ecx
//直接让i自增1
inc i
我们这里使用了movzx指令,实现了相同的功能,也顺便引入了一个新的汇编语句:
inc eax 相当于 add eax,1 也就是eax=eax+1
优点是速度比add指令快,占用空间小
与之相对的便是:dec指令,自减1
关于movzx和movsx的区别
案例一
#include "stdafx.h"
void function(){
char i=0xFF;
int j=0;
_asm{
movsx eax,i
mov j,eax
}
printf("%d\t%x\n",j,j);
_asm{
movzx eax,i
mov j,eax
}
printf("%d\t%x\n",j,j);
}
int main(int argc, char* argv[])
{
function();
return 0;
}
运行结果
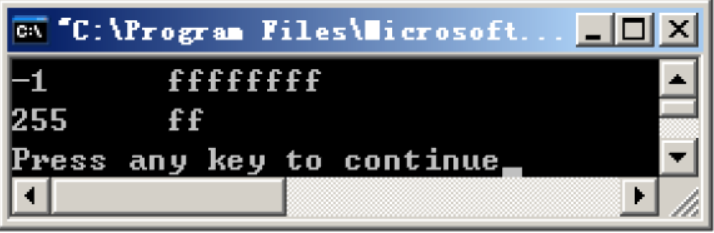
分析
void function(){
char i=0xFF;
int j=0;
_asm{
movsx eax,i
mov j,eax
}
printf("%d\t%x\n",j,j);
_asm{
movzx eax,i
mov j,eax
}
printf("%d\t%x\n",j,j);
}
首先声明一个char类型的变量i,默认为有符号数,然后再声明一个变量j初始化
char i=0xFF;
int j=0;
然后就是先将i带符号扩展到eax,接着再用eax赋值给j
_asm{
movsx eax,i
mov j,eax
}
带符号扩展解释:
首先将 i :0xFF转化为二进制 : 1111 1111
i是一个有符号数,最高位为符号位即1
符号扩展就是将要扩展的高位全部用符号位进行填充,这里就是将eax的高24位用1填充(低8位直接为i赋值),得到的结果转换为十六进制就是ffffffff,8个f,对应输出的结果
再看下面:
_asm{
movzx eax,i
mov j,eax
}
和前面类似,只不过是将movsx改为movzx
无符号扩展解释:
直接将eax的高24位用0填充(低8位直接为i赋值),得到的结果为000000ff,2个f,对应输出的结果
案例二
将上面的ff改为8b即可
void function(){
char i=0x8b;
int j=0;
_asm{
movsx eax,i
mov j,eax
}
printf("%d\t%x\n",j,j);
_asm{
movzx eax,i
mov j,eax
}
printf("%d\t%x\n",j,j);
}
运行结果
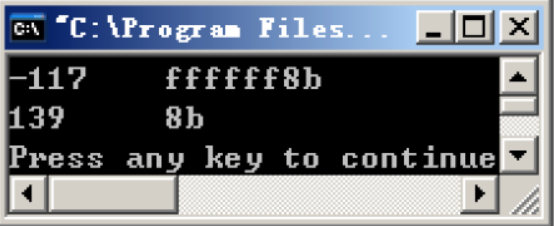
分析
有了前面分析的经验,直接来看f8如何有符号扩展
先将8b转化为二进制数:
8b:1000 1011
这里的符号位也就是最高位为1,于是将eax的高24位用1(符号位)填充,低8位直接为8b,得到的结果转化为十六进制:ffffff8b
与之类似,无符号扩展则是将eax的高24位用0填充,低8位依旧为8b,得到的结果转化为十六进制:0000008b
得到的结果运行结果一致
简单地来说,有符号扩展:movsx,就是将被扩展数的最高位(符号位),对应SF标志位的内容(修改SF标志位可以改变符号扩展的结果),填充到扩展的高位部分
而无符号扩展则直接用0填充扩展的高位部分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号