字符编码总结
1、 Python2 只用了ascll码。不支持中文。
文件编码默认:ascii码,字符串编码默认是ascii码
如果文件头声明了GBK,那字符串的编码就是GBK
Unicode是单独类型
Python2不会把字符编码转成unicode
2、Python3 不兼容python2, 文件默认编码是UTF-8, 字符串编码是unicode
3、Unicoude 万国码支持所有国家的编码,并且跟任何国家的编码都有一个映射表。只是
python代码的编码。
ASCII 占1个字节,只支持英文
GB2312 占2个字节,支持6700+汉字
Unicoude 2-4字节,至少占俩。
UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
UTF-32: 使用4个字节表示所有字符;
4、代码存硬盘上文件头必须声明一个编码格式:utf-8或gbk
注:写代码的字符编码是什么文件头就必须声明什么代码。
注2:程序代码编码不可互转,utf-8写的代码不可转GB否则不成功也退不回来。
如果出现编码问题:就是编码设置出错了。
1、 Python解释器默认编码:utf-8
2、 Python源文件文件编码
3、 Terminal使用的编码
4、 操作系统的语言设置。
5、python代码执行流程。
1、解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
2、把代码字符串按照python的语法规则进行解释。
3、所有的变量字符都会以unicode编码声明。
Python3文件自动以文件头编码格式读取到内存并自动转换成unicode编码
Python2 读取到内存并不自动转为unicode编码手动转:
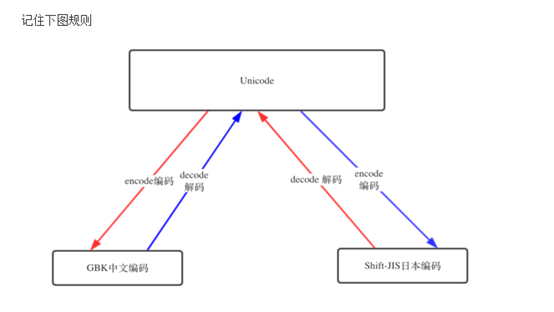
UTF-8 -- > decode解码 --> unicode
unicode -- > encode 编码 --> GBK/utf-8
S = “路飞学成”
S2 = s.decode(“utf-8”) #将之前的编码UTF-8 解码成unicode
S3 = S2.encode(‘gbk’) #将之前s2 unicode编码转成GBK

 浙公网安备 33010602011771号
浙公网安备 33010602011771号