YOLO V1、V2、V3算法 精要解说
前言
之前无论是传统目标检测,还是RCNN,亦或是SPP NET,Faste Rcnn,Faster Rcnn,都是二阶段目标检测方法,即分为“定位目标区域”与“检测目标”两步,而YOLO V1,V2,V3都是一阶段的目标检测。
从R-CNN到FasterR-CNN网络的发展中,都是基于proposal+分类的方式来进行目标检测的,检测精度比较高,但是检测速度不行,YOLO提供了一种更加直接的思路:
直接在输出层回归boundingbox的位置和boundingbox所属类别的置信度,相比于R-CNN体系的目标检测,YOLO将目标检测从分类问题转换为回归问题。其主要特点是:
•速度快,能够达到实时的要求,在TitanX的GPU上达到45fps;
•使用全图Context信息,背景错误(把背景当做物体)比较少;
•泛化能力强;

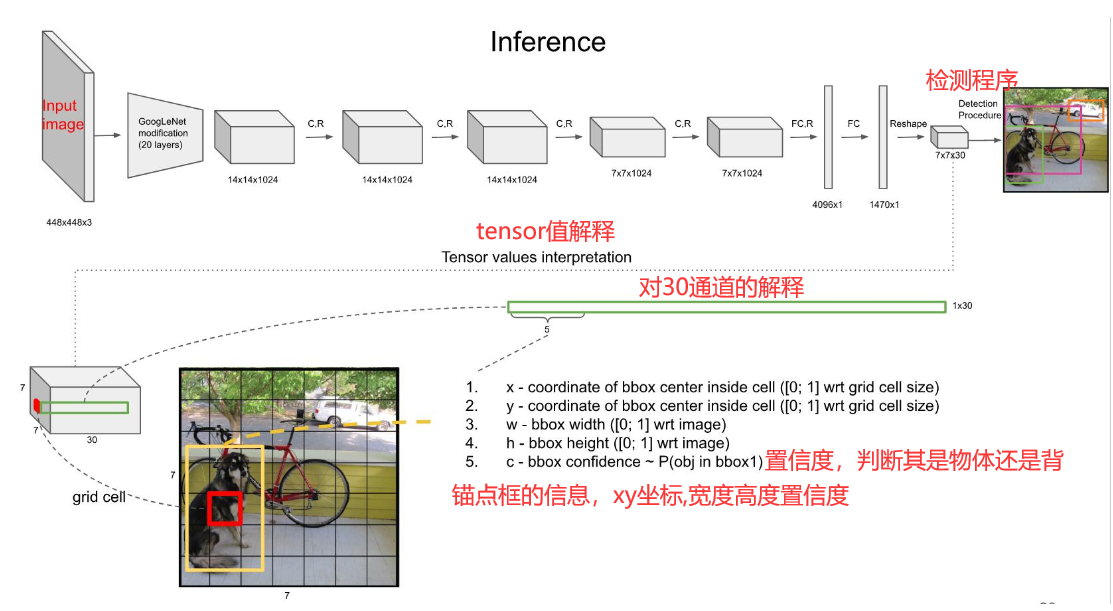
其想做的事如此看来很清晰,先判断是目标还是背景,若是目标,则再判断是属于这20个类别的哪个类(此VOC数据集是20个类别,别的数据集就是别的类别)
因为论文建议了我们一个grid cell最好是承载着两个边框,即bounding box,那么,这幅7*7个cell的图就有98个边框了,如下图
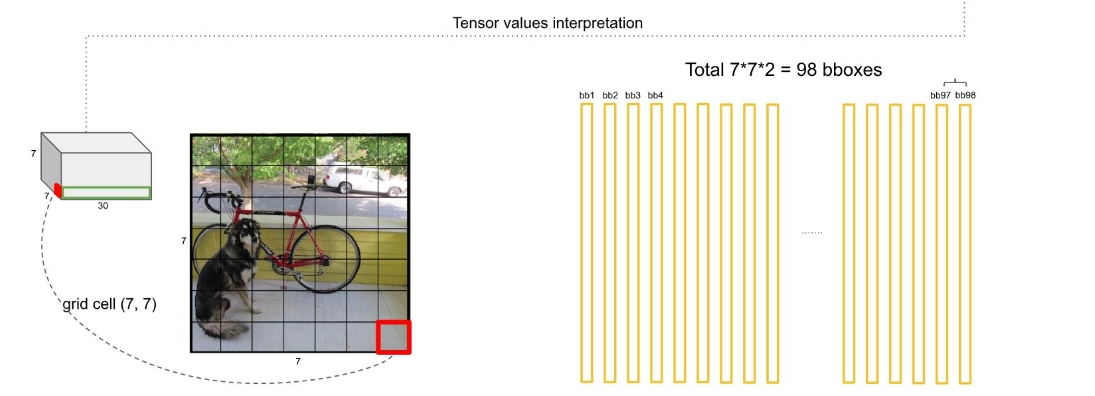
每个边框都是上面公式计算来的,我有写的,即背景还是物体的概率*20个类哪个类别的概率,如下图
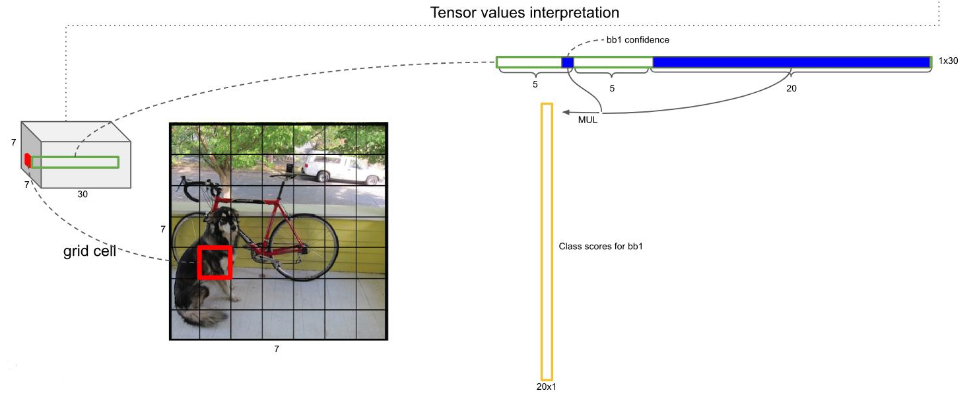
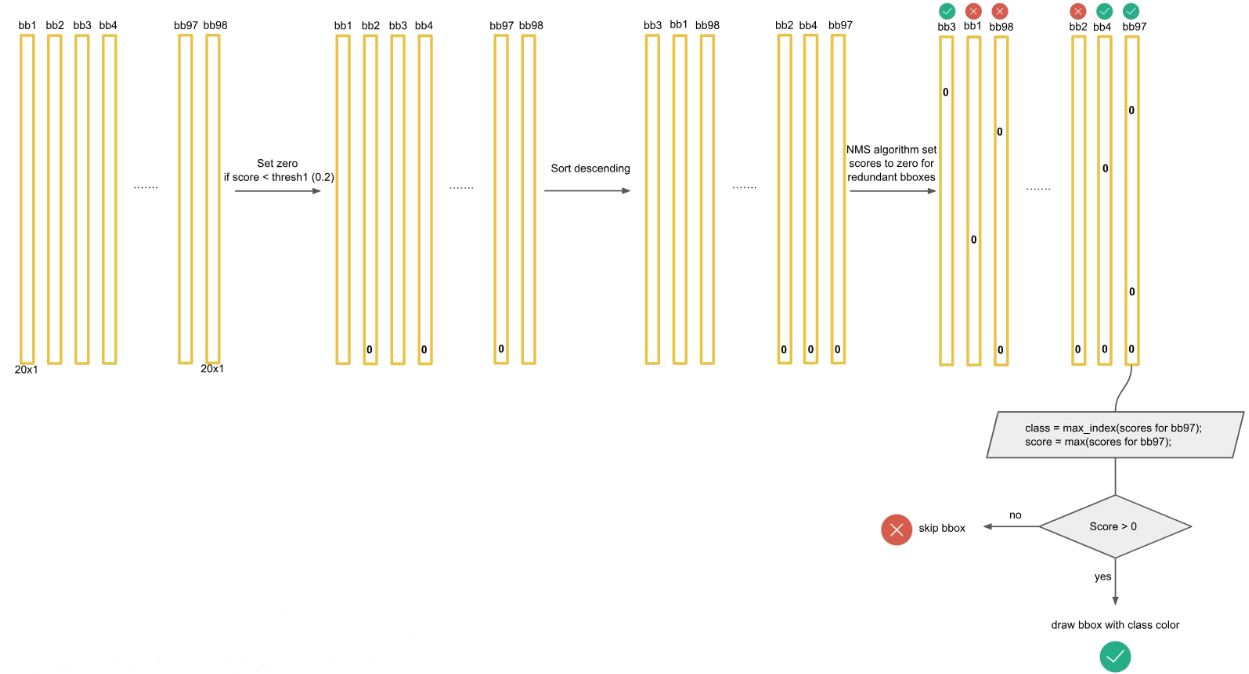
然后呢 ,就是处理这98个框框,如下图

这总共是20个类别,一行行的这么处理,直到20行处理完毕
然后对结果遍历,如果置信度的评分大于0,那这个框就可以代表此物体,如果得分小于0,就不行,如下图
来看一下损失函数吧,我把它分成了三类
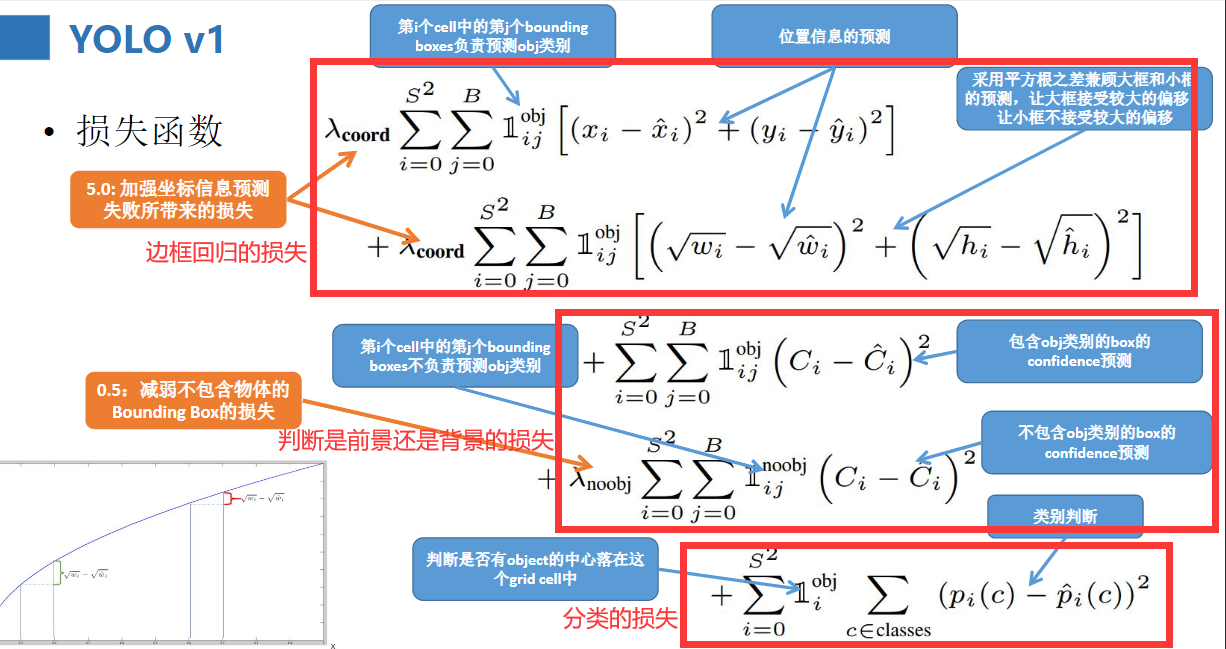
总结一下,并分析一下优缺点:


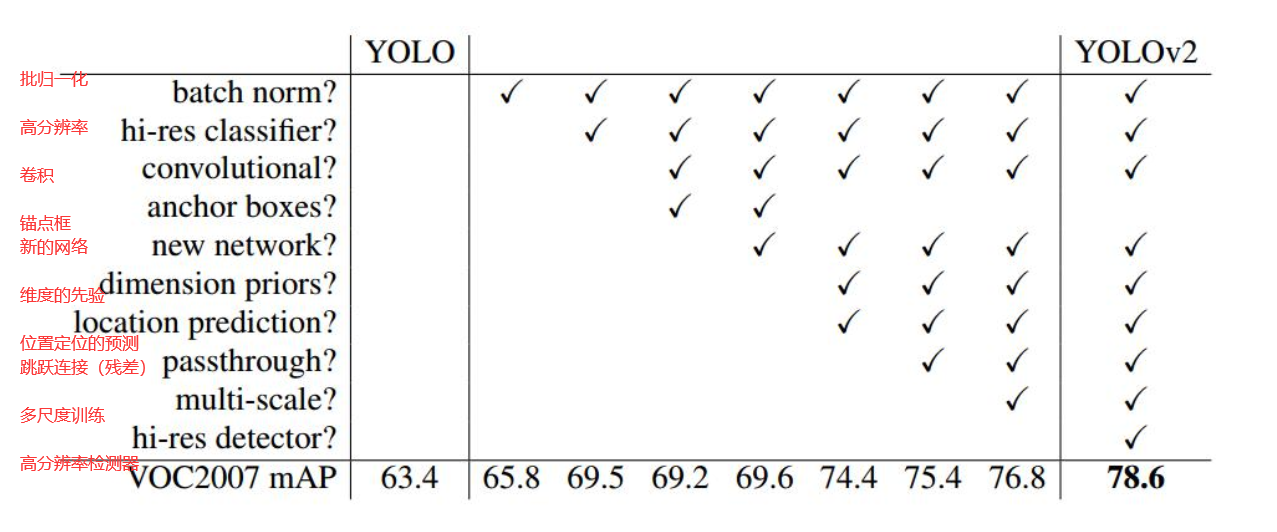
YOLO V2
算法的增强正是有了对原来的基础不断改进才得来的,YOLO V2相对于V1主要有三方面变化。
下图是聚类的不同标准下的平均IOU值
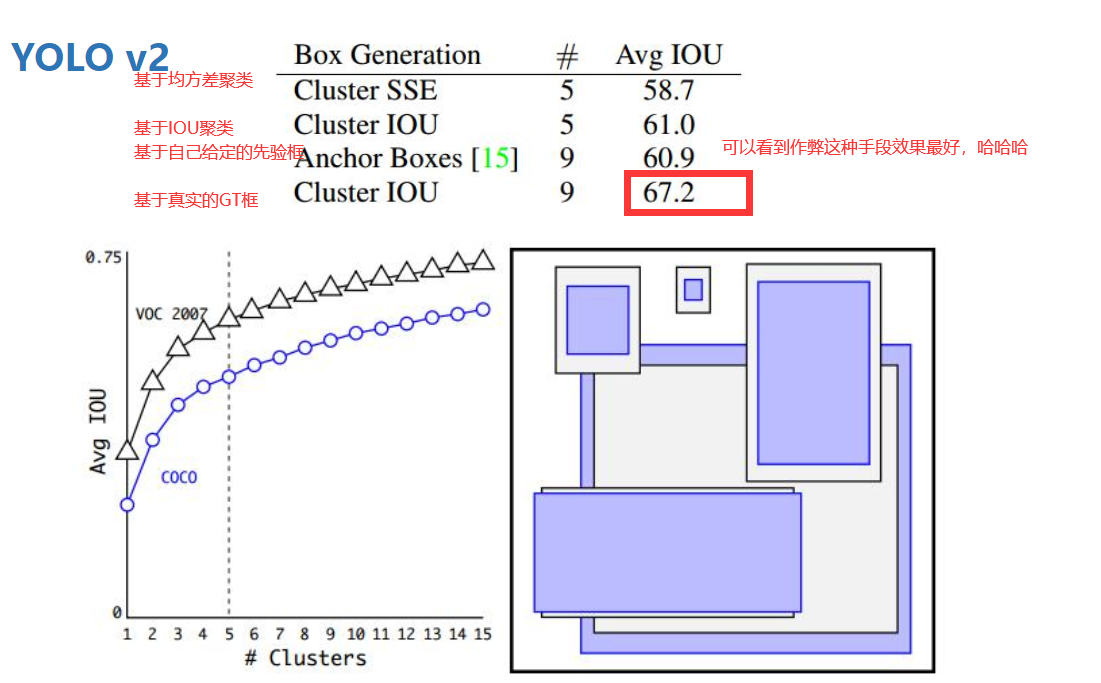
其沿用了Faster RCNN中Anchor box(锚点框)的思想,通过kmeans方法在VOC数据集(COCO数据集)上对检测物体的宽高进行了聚类分析,得出了5个聚类中心,因此选取5个anchor的宽高: (聚类时衡量指标distance = 1-IOU(bbox, cluster))
COCO: (0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434), (7.88282, 3.52778), (9.77052, 9.16828)
VOC: (1.3221, 1.73145), (3.19275, 4.00944), (5.05587, 8.09892), (9.47112, 4.84053), (11.2364, 10.0071)
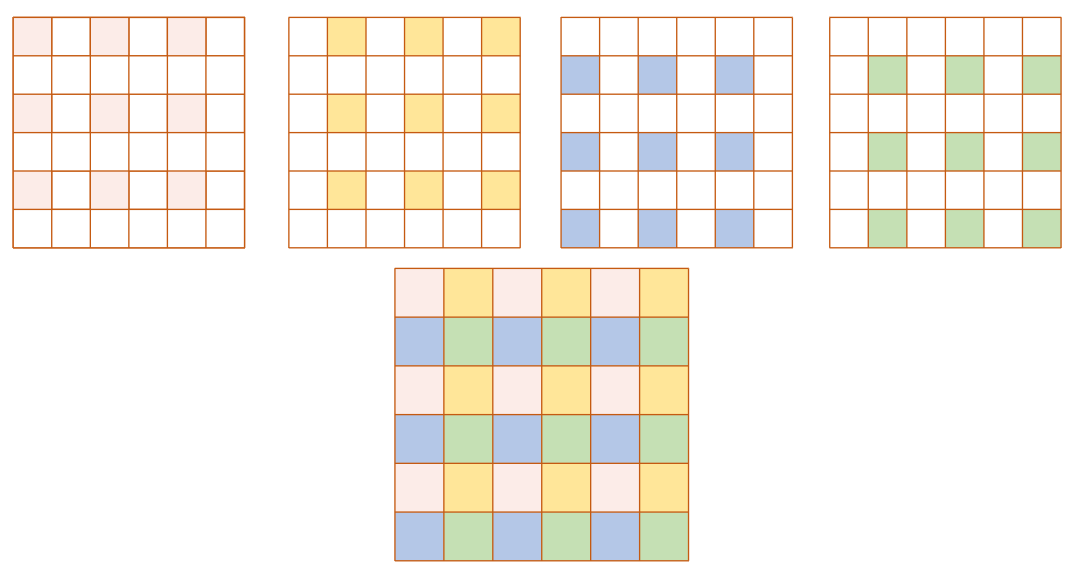
这样每个grid cell将对应5个不同宽高的anchor, 如下图所示:(上面给出的宽高是相对于grid cell,对应的实际宽高还需要乘以32(2的5次方),因为这里给出的原图大小是416*416大小的,经过卷积啊池化啊下采样了5次后变成了13*13大小的)

关于预测的bbox的计算:(416*416-------13*13 为例),卷积池化等经历了5次下采样,缩小了2的5次方倍(看下面这三段话的时候,记得看此行往上数第9到12行字,相信你会明白的)
(1) 输入图片尺寸为416*416, 最后输出结果为13*13*125,这里的125指5*(5 + 20),5表示5个anchor,25表示[x, y, w, h, confidence ] + 20 class ),即每一个anchor预测一组值。
(2) 对于每一anchor预测的25个值, x, y是相对于该grid cell左上角的偏移值,需要通过logistic函数将其处理到0-1之间。如13*13大小的grid,对于index为(6, 6)的cell,预测的x, y通过logistic计算为xoffset, yoffset, 则对应的实际x = 6 + xoffset, y = 6+yoffset, 由于0<xoffset<1, 0<yoffset<1, 预测的实际x, y总是在(6,6)的cell内。对于预测的w, h是相对于anchor的宽高,还需乘以anchor的(w, h), 就得到相应的宽高
(3) 由于上述尺度是在13*13下的,需要还原为实际的图片对应大小,还需乘以缩放倍数32



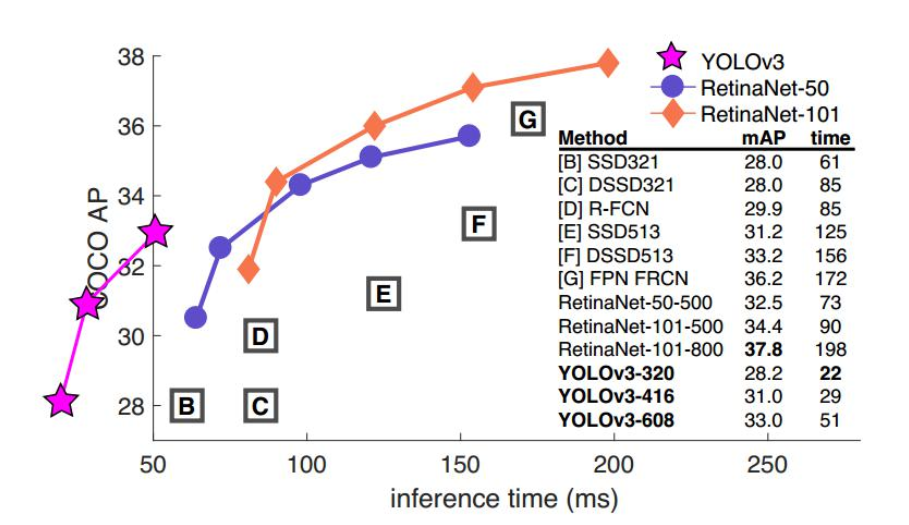
yolo v3在保证实施率(fps>36)的情况下,尽量追求性能,下面是几个主干网络的对比
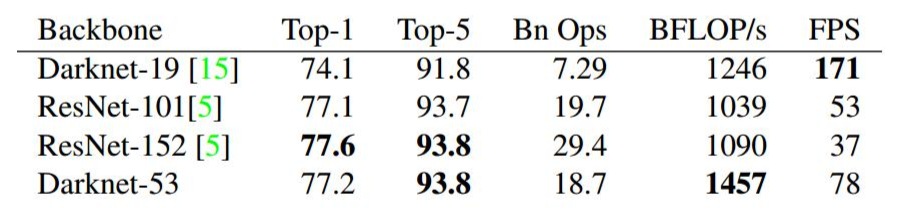
darknet为论文中使用的,效果不错,resnet在top5的准确率上和darknet一致。但是实时性略差,毕竟它本质是用来分类的网络,若用于目标检测还需要修改修改
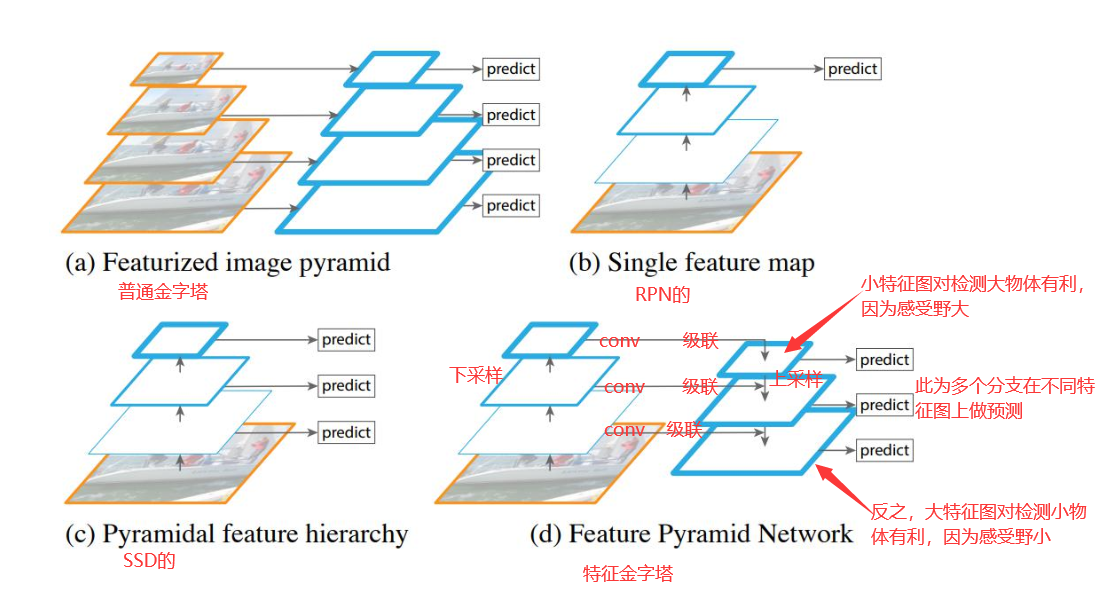
下图是特征金字塔的结构与其他几种结构的对比图
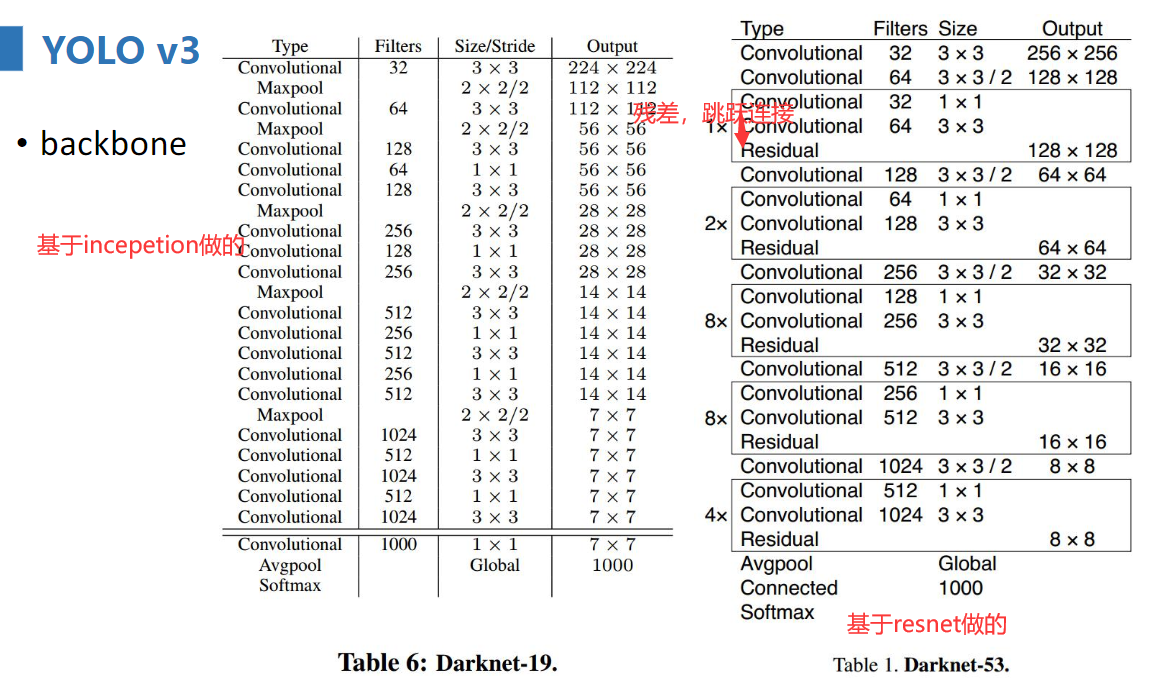
下面是yolo v3的具体结构,其中特征金字塔部分参照上图看,就能明白

来看一下损失函数吧,采用了类似YOLOv1的损失函数,其主要更改的地方是将v1中关于confidence和class类别概率部分的损失函数更改为logistic交叉熵损失函数(tf.nn.sigmoid_cross_entropy_with_logits)。

训练操作类似YOLOv1和v2,主要特点如下:
•网络结构darknet;
•输入数据完整图像,不进行hardnegativemining(难负样本的挖掘,当然,我们自己实现代码的时候可以做)或者其它操作;
•多尺度训练multiscale;
•数据增强dataaugmentation;
•批归一化batchnormalization;

致此完毕全部内容,我求求你们关注我好不好,很不容易的,一个人打两份工,晚上还要给别人织毛衣......


 浙公网安备 33010602011771号
浙公网安备 33010602011771号