机器学习小结与面经19_2_22
- 介绍一个完整的机器学习项目流程?
- 数学抽象:根据数据明确任务目标,是分类、还是回归或者是聚类。
- 数据获取:数据决定了机器学习结果的上限,而算法只是逼近这个上限。数据要有代表性,不然肯定过拟合。对于分类问题,数据偏斜不能太严重,差距不宜过大。对于数据的量级有一个评估,多少个样本,多少个特征。根据内存估算需求。
- 预处理与特征选择:预处理、数据清洗。归一化、离散化、因子化、缺失值处理,去除共性等。筛选有效特征。
- 模型训练与调优:算法训练与调优。
- 模型诊断:对模型的实际表现进行诊断:包括过拟合、欠拟合等。常见的例如交叉验证以及绘制学习曲线等等。过拟合的基本思路是增加数据量、减少模型参数,降低模型复杂度。欠拟合就是提高特征数量和质量,增加模型复杂度。误差分析是指:参数的问题还是算法选择的问题,是特征的问题还是数据本身的问题。诊断之后需要进行调优,调优后的模型需要重新诊断,这是一个反复迭代逼近的过程,需要不断的尝试达到最优状态。6. 模型融合:工程上一般是在前端也就是数据清洗以及预处理上面与后端融合方便下功夫。因为比较标准简单容易复制,直接调参的工作不会很多,毕竟训练起来太慢了,而且效果难以保证。
- 上线运行:主要包括模型的运行速度(时间复杂度),资源消耗程度(空间复杂度)以及最后的稳定性如何。
- 信息熵与自信息:

自信息时一个事件承载的信息量。信息熵是对整个概率分布的不确定性的总体进行量化。
KL散度:
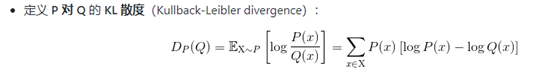
在离散型变量的情况下,KL散度衡量的是:当我们使用一种被设计成能够使得概率分布Q产生消息的长度最小的编码,发送包含由概率分布P产生的符号信息时,所需要的额外信息量。
性质:-----非负:KL散度为0当且仅当P与Q在离散型变量的情况下是相同的分布,或者在连续型变量下处处相同。
-----不对称。
交叉熵:
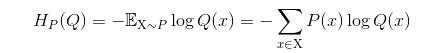
交叉熵本质上可以看成,用一个猜测的分布的编码方式去编码其真实的分布,得到的平均编码长度或者信息量。一般用于最后的损失函数。


互信息:(信息增益)
一个联合分布中的两个信息的纠缠程度或者叫做相互影响的那部分信息量。
比较典型的就是决策树的分支标准:使用的就是信息增益的方式互信息。

逻辑回归:
关键点:
定义:
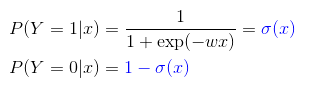
损失函数:极大似然估计;

多分类回归模型:

支持向量机:
- 简单描述:
二分类模型:定义在特征空间上间隔最大的线性分类器,间隔最大使其有别与感知机。包括核技巧,使其成为非线性分类器。
学习策略:间隔最大化。求解凸二次规划的问题。
求解凸函数二次规划的最优化算法。
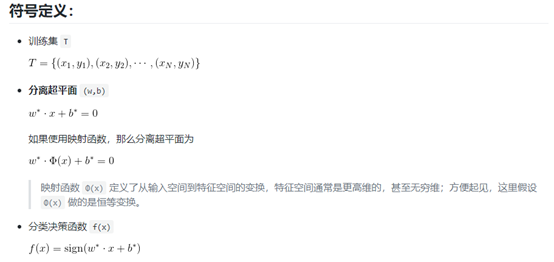
- 支持向量:训练集中与分离超平面距离最近的样本点的实例叫做支持向量。
![]()
- 分类:
训练数据线性可分:-----硬间隔最大化;线性可分SVM;
数据接近线性可分-------软间隔最大化;
数据线性不可分---------使用核技巧以及软间隔最大化。
- 核函数:
将输入从输入空间映射到特征空间后得到的特征向量之间的内积。

线性可分SVM:
a. 根据间隔最大化的目标导出标准SVM问题。
b. 使用拉格朗日乘子对偶问题的求解过程。





决策树:
特征选择;树的生成以及剪枝。
ID3与C4.5之间的区别:
前者使用信息增益进行特征选择后者使用信息增益比。
回归树:
Cart算法假设决策树是二叉树,内部取值节点为是或者否。
Cart树既可以用于分类也可以用于回归。
对回归的情况,算法使用平方误差最小化策略选择特征,对分类树使用基尼系数最小化准则选择特征。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号