
Python中偶尔遇到的细节疑问(一):去除列名特殊字符、标准差出现nan、切片索引可超出范围、range步长、众数
1. Pandas读取csv或excel数据时,很可能遇到的columns中,列名会带有特殊字符,例如:空格、\n、\t、双空格、引号等等,如果不想手动修改的话,可以df.rename()来解决。
df = pd.read_excel(data_path) df_ = df.rename(columns=lambda x: x.replace(" ","").replace(' ','').replace(" ","").replace(r"\t","").replace(r"\n",""))
如果还有其他的字符,也可以类似解决。
2. python计算标准差时,出现nan:这个原因可能是原始数据都是nan;
但是更有可能是求解std时参数用错了:因为python求解时,有偏估计和无偏估计是用 ddof参数来选择的,求标准差时除以的值是:n-ddof。
如果使用numpy计算的话,numpy.std() 求标准差的时候默认是除以 n,即有偏估计;如果要无偏估计,需要在np.std()参数中加入参数 ddof = 1,也就是除以的是n-1;
然而,pandas却是相反的,它默认是无偏估计,也就是除以 n-1;如果想有偏估计,需要设置参数 ddof=0,即 df.std(ddof=0)。
所以:
如果你的数值序列其他的都是nan,只有一个值不是nan,那么无偏估计时,std求解的标准差就是nan了。
3. 列表、字符串等在直接索引时,不能超出长度范围;但是切片索引时,却可以超出范围,超出范围时取值一直到末尾。
例如:
a = 'abcdefg' #print(a[10]) # 报错:IndexError: string index out of range print(a[3:10]) #不报错:返回 defg b = [2,3,4,5] # print(b[10]) # 报错:IndexError: string index out of range print(b[2:10]) #不报错:返回 [4, 5]
4. range函数,有步长参数可用
range(start, stop[, step])
有时候,步长参数可以让你减少一层for循环的使用。
for ii in range(1,8,2): print(ii)
5. pandas求取众数 mode() 方法,多个众数时,求所有众数的均值
import pandas as pd import numpy as np df = pd.DataFrame({'name':['Jack','Alex','Bob','Nancy','Mary','Alice','Jerry','Wolf'], 'course':['Chinese','Math','Math','Chinese','Math','English','Chinese','English'], 'grade':[1,1,2,2,2,2,3,3], 'score':[85,85,91,78,89,89,78,79]}) print(df.score) aa = df.score.mode() #众数 print(type(aa)) # <class 'pandas.core.series.Series'> print('aa:',aa) #如果有多个众数,会形成一个序列返回 print(np.mean(aa)) # 多个众数时,求均值
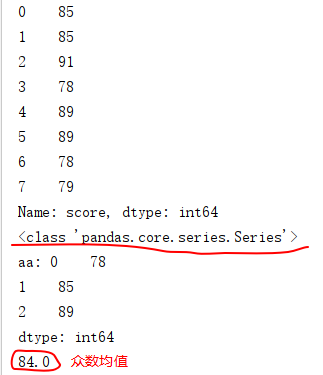
注:scipy.stats.mode() 和 df.value_counts() 均可用于求众数。
参考:
https://blog.csdn.net/katyusha1/article/details/81501893


 浙公网安备 33010602011771号
浙公网安备 33010602011771号