
字符与编码:ASCII码、Unicode和UTF-8
字符与编码的问题,之前很少深究,但这次遇到了base64的问题,所以觉得是时候解决一下了,不一定全面,但想尽可能记录一些想知道的点。。。
- 首先,为什么需要编码??因为计算机本身可不认识:‘你在做什么?’、‘what are you doing?’等这么人类性的语言;在计算机内部,所有的信息都表示为一个二进制的字符串。而每一个二进制位(bit)有0和1两种状态,具体哪些二进制数表示什么字符,多少位表示什么字符,需要有一个标准,也就是编码。
- 字节(Byte):是计量存储容量的单位,是构成信息的一个很小的单位,上面还有KB、MB、GB、TB、PB、EB、ZB、YB等;下面还有bit(位)。
- 字符:各种文字、符号的总称。例如文字、标点、图形、数字、字母等等。
- 字符集:顾名思义,就是一定数量的字符组成的集合,字符集种类比较多,而且每个字符集包含的字符个数也不同,常见字符集主要有:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等,字符集为每一个【字符】分配一个唯一的 ID(学名为码位 / 码点 / Code Point)。
- 字符编码:将字符集中的每个字符映射为字节流的实现方案(编码方案),即属于将【码位】转换为字节序列的规则,便于计算机存储和传输;常见的字符编码有ASCII编码、UTF-8编码、GBK编码、Base64编码等。某种意义上来说,字符集与字符编码有种对应关系,例如 ASCII字符集对应有ASCII编码。
- 编码与解码:编码的过程是将字符转换成字节流,解码的过程是将字节流解析为字符。
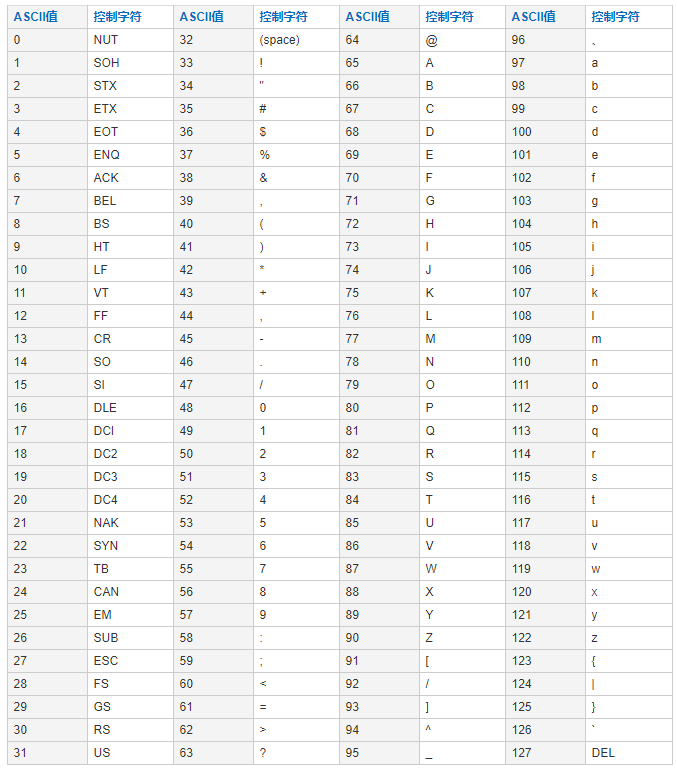
1. ASCII码:(American Standard Code for Information Interchange) 美国信息交换标准码,是美国制定的单字节字符编码系统,作用于ASCII字符集,见附录1。
因为在英语中,128个符号就可以满足,所以一直将1个字节(8位)的最高位闲置(默认为0),其他7位用于编码;后来才扩展了最高位,共可以表示256个符号。
例如:字符A,ASCII码是65(十进制),二进制是01000001,八进制是0101,十六进制是0x41。
但是,即使256位,也是不够用的,因为世界上的国家和文字、符号太多了,于是就开始扩展,出现了Unicode字符集。
2. Unicode字符集
注意:Unicode是一个符号集,包含了各国的符号、文字等,详细可查;它只规定了字符对应的二进制代码,却没有规定这个二进制代码应该如何存储。
于是出现了Unicode字符集对应的编码方式,主要是utf-8,也有utf-16、utf-32等,但utf-8是在互联网上使用最广的一种Unicode的实现方式。utf-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,并且根据不同的符号需要而变化字节长度。
3. utf-8编码
utf-8的编码规则是:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。所以对于英文字符,utf-8编码和ASCII码相同。
2)对于n字节的符号(n>1),第一个字节的前n位都为1,第n+1位为0,(其第一个字节从最高位开始,连续的二进制位为1的个数决定了其编码的字节数n),后面各字节的前两位一律为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
其编码规则如下:
# ---------------------------------------------------------------
Unicode符号范围(十六进制) | UTF-8编码方式(二进制)
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
# ---------------------------------------------------------------
4. 示例,获取汉字 '龙' 的utf-8编码值
第一步,获取 '龙' 的Unicode值:ord('龙') —— python内置函数ord,得到:40857
第二步,求得Unicode值的十六进制:hex(40857) —— 得到:9f00
第三步,获取utf-8编码:其实python有函数进行编码 —— '龙'.encode('utf-8'),可得:b'\xe9\xbe\x99',也即是:e9be99
其求取方法如下:
(1)求取 Unicode值对应的二进制值:十进制转二进制 —— python内置函数,bin(40857),得到:'0b1001111110011001',即:'1001111110011001'。
(2)由其十六进制:9f00,对应utf-8的编码规则,0800<9f00<ffff,所以属于三字节类型,上述规则第三行,即属于:'1110xxxx 10xxxxxx 10xxxxxx' 类型。
(3)从得到的二进制中,最后一个二进制位开始,依次从后向前代入上述格式中的 'x' 中,多出的位补0。
(4)于是得到:11101001 10111110 10011001,对应的十六进制为:e9 be 99,因为每4位二进制组成一个十六进制。
# ----------------------------------------------------------------
5. 获取 utf-8 编码的字节长度 —— 先编码,再len()
b = '龙'.encode('utf-8') # utf-8 编码 print('b:',b) # 结果中开头的 b 字符表示bytes类型,'\x'表示十六进制数据 print(type(b)) # 类型是'bytes' print(len(b)) # 编码的字节数,3个字节编码,因为b就是字节类型 bytes

6. utf-8 解码和编码
t = '大' str_ = t.encode('utf-8') # 编码得到字节流 print(str_) uni_ = str_.decode('utf-8') # 通过字节流,进行解码获取字符串 print(uni_)

7. 英文字母在计算机内存储的是机内码,也就是ASCII码,因为英文字母的机内码就是ASCII码。而每一个汉字在不同的编码下也有对应的内码。
utf-8 用3个字节来表示常用的一个中文字符,1个字节来表示英文字符,兼容ASCII码;
gbk、gb2312 用2个字节来表示一个中文字符,1个字节来表示英文字符,兼容ASCII码,gbk向下兼容gb2312,gb18030向下兼容gbk和gb2312;
b = 'm'.encode('gbk') print('b:',b) # 开头的 b 字符表示bytes类型 print(type(b)) #类型是'bytes' print(len(b)) #编码的字节数,因为上面先进行了编码

8. sys.getsizeof() 返回对象的内存大小:不仅仅包括字符等数据的字节数,还包含很多附带的内存开销,例如垃圾收集器等;就像一个word文档,即使什么都没写,也会有9kB的大小,因为它包含了word的头部信息。
附录1:ASCII码表
参考:
https://www.cnblogs.com/wangxiaorui/p/5287975.html
https://baike.baidu.com/item/ASCII/309296?fromtitle=ascii%E7%A0%81&fromid=99077&fr=aladdin
https://tool.oschina.net/commons?type=4
https://zhuanlan.zhihu.com/p/25148581

