
Mysql分组排序的三种方法以及substring_index
用惯了hive的row_number,在Mysql中想要使用分组排序的功能时,却发现不那么简单 —— 貌似不能一个函数解决。
有时候又特别需要使用,怎么办呢?不慌,这也还是有方法的。
首先建立数据表:
create table t_variable ( name_people VARCHAR(255) NOT NULL comment '姓名', grade VARCHAR(255) NOT NULL comment '年级', course VARCHAR(255) NOT NULL comment '科目', score VARCHAR(255) NOT NULL comment '分数' )ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='test_变量'; insert into t_variable(name_people, grade, course, score) values('花满楼',5,'数学',86); insert into t_variable(name_people, grade, course, score) values('陆小凤',5,'数学',94); insert into t_variable(name_people, grade, course, score) values('西门吹雪',5,'数学',90); insert into t_variable(name_people, grade, course, score) values('花满楼',5,'语文',97); insert into t_variable(name_people, grade, course, score) values('陆小凤',5,'语文',95); insert into t_variable(name_people, grade, course, score) values('西门吹雪',5,'语文',89); insert into t_variable(name_people, grade, course, score) values('花满楼',5,'科学',93); insert into t_variable(name_people, grade, course, score) values('陆小凤',5,'科学',96); insert into t_variable(name_people, grade, course, score) values('西门吹雪',5,'科学',94);
那么,分组排序:
方法一:使用变量@ —— 还可以选择排名在第几的人。
select name_people, course, score, @ss, @tt, if(@ss=course, @tt:=@tt+1, @tt:=1) as rk, @ss:=course as a_course from ( select * from t_variable order by course, score desc # 先按分组字段和排序字段进行整体排序,这样相同选择字段的记录就会前后排列 ) as t1 cross join #直接笛卡尔积 ( select @ss:='', #初始值 @tt:=0 ) as t2;

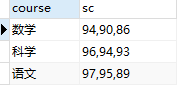
方法二:group_concat —— 同一分组内的值先连接,再选取;#[Err] 1140 - In aggregated query without GROUP BY, expression #1,使用group_concat必须用group by
select course, group_concat(score order by score desc) as sc #连接的是排序字段 from t_variable group by course #分组字段
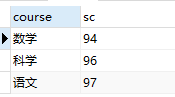
可使用 substring_index 进行选择第几个:
select course, substring_index(group_concat(score order by score desc),',',1) as sc from t_variable group by course
当然,如果要知道是哪条记录在排名第一的位置,需要用这个结果与原始表join选择一下。
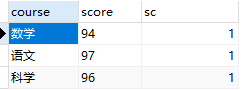
方法三:通过join查询实现
select * from ( select a.course, a.score, count(*) as sc from t_variable as a left join t_variable as b on a.course=b.course #本来的分组字段 and a.score<=b.score #本来的排序字段 group by course, #此时才对以上结果进行分组 score ) as c where c.sc=1;
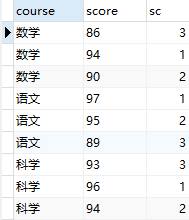
这个稍微复杂一点,是通过join之后,进行筛选,再对筛选结果分组计数得到,只需要看个中间表即可 —— 因为最大值小于等于的值只有它本身,也就是对小于等于的记录进行计数count时,值会为1,其他非最大值都会大于1:
select a.course, a.score, count(*) as sc from t_variable as a left join t_variable as b on a.course=b.course and a.score<=b.score group by course, score;
附:substring_index —— SUBSTRING_INDEX(str,delim,count),用于获取子字符串
-- str:待处理字符串
-- delim:分隔符
-- count:计数值
若count是正数,则从左往右数,第count个分隔符左边的字符串
若count是负数,则从右往左数,第count个分隔符右边的字符串
select substring_index('烽火台、长城、颐和园、北海','、',1) select substring_index('烽火台、长城、颐和园、北海','、',3) select substring_index('烽火台、长城、颐和园、北海','、',-2) select substring_index(substring_index('烽火台、长城、颐和园、北海','、',2),'、','-1') #如果选中间的子字符串,可以嵌套
#
参考:
https://blog.csdn.net/m0_37797991/article/details/80511855


 浙公网安备 33010602011771号
浙公网安备 33010602011771号