
mysql-left join的坑和优化经验
参考文章:https://blog.csdn.net/weixin_39980841/article/details/110807850
CREATE TABLE classes ( `id` INT(11) NOT NULL PRIMARY KEY, `name` VARCHAR(32) NOT NULL ) INSERT INTO classes (`id`, `name`) VALUES (1, '一班'), (2, '二班'), (3, '三班'), (4, '四班') CREATE TABLE students ( `id` INT(11) NOT NULL PRIMARY KEY AUTO_INCREMENT, `class_id` INT(11) NOT NULL, `name` VARCHAR(32), `gender` VARCHAR(1) ) INSERT INTO students( `class_id`, `name`, `gender` ) VALUES (1, '小明', 'M'), (1, '小红', 'F'), (1, '小军', 'M'), (1, '小米', 'F'), (2, '小白', 'M'), (2, '小兵', 'F'), (2, '小林', 'F'), (3, '小新', 'F'), (3, '小王', 'M'), (3, '小丽', 'F')
根源
mysql 对于left join的采用类似嵌套循环的方式来进行从处理,以下面的语句为例:
SELECT * FROM LT LEFT JOIN RT ON P1(LT,RT)) WHERE P2(LT,RT)
其中P1是on过滤条件,缺失则认为是TRUE,P2是where过滤条件,缺失也认为是TRUE,该语句的执行逻辑可以描述为:
FOR each row lt in LT {// 遍历左表的每一行
BOOL b = FALSE;
FOR each row rt in RT such that P1(lt, rt) {// 遍历右表每一行,找到满足join条件的行
IF P2(lt, rt) {//满足 where 过滤条件
t:=lt||rt;//合并行,输出该行
}
b=TRUE;// lt在RT中有对应的行
}
IF (!b) { // 遍历完RT,发现lt在RT中没有有对应的行,则尝试用null补一行
IF P2(lt,NULL) {// 补上null后满足 where 过滤条件
t:=lt||NULL; // 输出lt和null补上的行
}
}
}
当然,实际情况中MySQL会使用buffer的方式进行优化,减少行比较次数,不过这不影响关键的执行流程,不在本文讨论范围之内。
从这个伪代码中,我们可以看出两点:
- 如果想对右表进行限制,则一定要在on条件中进行,若在where中进行则可能导致数据缺失,导致左表在右表中无匹配行的行在最终结果中不出现,违背了我们对left join的理解。因为对左表无右表匹配行的行而言,遍历右表后b=FALSE,所以会尝试用NULL补齐右表,但是此时我们的P2对右表行进行了限制,NULL若不满足P2(NULL一般都不会满足限制条件,除非IS NULL这种),则不会加入最终的结果中,导致结果缺失。
- 如果没有where条件,无论on条件对左表进行怎样的限制,左表的每一行都至少会有一行的合成结果,对左表行而言,若右表若没有对应的行,则右表遍历结束后b=FALSE,会用一行NULL来生成数据,而这个数据是多余的。所以对左表进行过滤必须用where。
下面展开两个需求的错误语句的执行结果和错误原因:
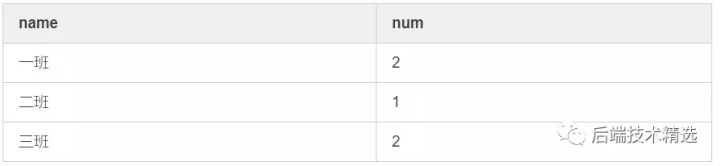
需求1
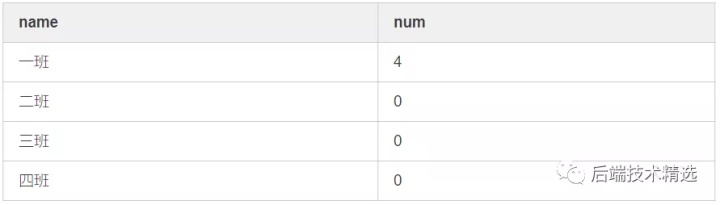
需求2
需求1由于在where条件中对右表限制,导致数据缺失(四班应该有个为0的结果)
正确的slq应该为
SELECT c.name, COUNT(s.name) AS num
FROM classes c LEFT JOIN students s
ON (s.class_id = c.id AND s.gender = 'F')
GROUP BY c.name
需求2由于在on条件中对左表限制,导致数据多余(其他班的结果也出来了,还是错的)
总结
通过上面的问题现象和分析,可以得出了结论:在left join语句中,左表过滤必须放where条件中,右表过滤必须放on条件中,这样结果才能不多不少,刚刚好。
SQL 看似简单,其实也有很多细节原理在里面,一个小小的混淆就会造成结果与预期不符,所以平时要注意这些细节原理,避免关键时候出错。
========================
根据经验。我更喜欢直接用where组合成为虚拟表,这样虚拟表能直接使用到索引,也能较少笛卡尔乘积,使得大表的查询效率大大提高,也绝不会发生错误。
优化后的sql为
SELECT c.name, COUNT(s.name) AS num
FROM classes c LEFT JOIN (SELECT * FROM students s WHERE s.gender = 'F') AS s
ON s.class_id = c.id
GROUP BY c.name

 浙公网安备 33010602011771号
浙公网安备 33010602011771号