java8新特性之lambda表达式以及stream流
1. lambda表达式
1.1 什么是lambda表达式
Lambda表达式有两个特点:一是匿名函数,二是可传递
- 匿名函数的应用场景是:
通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用Lambda表达式。lambda表达式所表示的匿名函数的内容应该是很简单的,如果复杂的话,干脆就重新定义一个函数了,使用lambda就有点过于执拗了。
- 可传递使用场景是:
就是将Lambda表达式传递给其他的函数,它当做参数,Lambda作为一种更紧凑的代码风格,使Java的语言表达能力得到提升。
2. 使用lambda表达式
2.1 函数式接口
如果一个接口中,有且只有一个抽象的方法(Object类中的方法不包括在内),那这个接口就可以被看做是函数式接口。例如Runnable接口就是一个函数式接口:
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
@FunctionalInterface
public interface MyInterface {
void test();
String toString();
}
MyInterface这也是一个函数式接口,因为toString()是Object类中的方法,只是在这里进行了复写,不会增加接口中抽象方法的数量。
2.2 函数式接口实例创建的三种方式
1、lambda表达式
如果使用lambda表达式来创建一个函数式接口实例,那这个lambda表达式的入参和返回必须符合这个函数式接口中唯一的抽象方法的定义
list.forEach(item -> System.out.println(item));
Lambda 表达式的基础语法
// 语法格式一:无参数,无返回值
() -> System.out.println("Hello Lambda!");
// 语法格式二:有一个参数,并且无返回值
(x) -> System.out.println(x)
// 语法格式三:若只有一个参数,小括号可以省略不写
x -> System.out.println(x)
// 语法格式四:有两个以上的参数,有返回值,并且 Lambda 体中有多条语句
Comparator<Integer> com = (x, y) -> {
System.out.println("函数式接口");
return Integer.compare(x, y);
};
// 语法格式五:若 Lambda 体中只有一条语句, return 和 大括号都可以省略不写
Comparator<Integer> com = (x, y) -> Integer.compare(x, y);
2、方法引用
方法引用的语法是 对象::方法名
//对象的引用 :: 实例方法名
@Test
public void test1(){
// 之前我们是这样写的
Employee emp = new Employee(101, "张三", 18, 9999);
Supplier<String> sup = () -> emp.getName();
System.out.println(sup.get());
System.out.println("----------------------------------");
// 现在我们是这样写的
Supplier<String> sup2 = emp::getName;
System.out.println(sup2.get());
}
//类名 :: 静态方法名
@Test
public void test2(){
Comparator<Integer> com = (x, y) -> Integer.compare(x, y);
System.out.println("-------------------------------------");
Comparator<Integer> com2 = Integer::compare;
}
//类名 :: 实例方法名
@Test
public void test3(){
BiPredicate<String, String> bp = (x, y) -> x.equals(y);
System.out.println(bp.test("abcde", "abcde"));
System.out.println("-----------------------------------------");
BiPredicate<String, String> bp2 = String::equals;
System.out.println(bp2.test("abc", "abc"));
}
3 、构造器引用
对于person类,有两个构造器
class Person {
String firstName;
String lastName;
Person() {}
Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
}
现在有一个工厂接口用来生成person类
// Person 工厂
interface PersonFactory<P extends Person> {
P create(String firstName, String lastName);
}
我们可以通过 :: 关键字来引用 Person 类的构造器,来代替手动去实现这个工厂接口
// 直接引用 Person 构造器
PersonFactory<Person> personFactory = Person::new;
Person person = personFactory.create("Peter", "Parker");
Person::new 这段代码,能够直接引用 Person 类的构造器。然后 Java 编译器能够根据上下文选中正确的构造器去实现 PersonFactory.create 方法
3. stream用法
3.1 初步认识
Java 8引入了全新的Stream API,这里的Stream和I/O流不同,Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作,或者大批量数据操作,Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返
List<String> myList =
Arrays.asList("a1", "a2", "b1", "c2", "c1");
myList
.stream() // 创建流
.filter(s -> s.startsWith("c")) // 执行过滤,过滤出以 c 为前缀的字符串
.map(String::toUpperCase) // 转换成大写
.sorted() // 排序
.forEach(System.out::println); // for 循环打印
3.2 stream的特性
stream主要具有如下三点特性
-
(1)stream不存储数据
-
(2)stream不改变源数据
-
(3)stream的延迟执行特性
通常我们在数组或集合的基础上创建stream,stream不会专门存储数据,对stream的操作也不会影响到创建它的数组和集合,对于stream的聚合、消费或收集操作只能进行一次,再次操作会报错
由于stream的延迟执行特性,在聚合操作执行前修改数据源是允许的。
List<String> wordList;
@Before
public void init() {
wordList = new ArrayList<String>() {
{
add("a");
add("b");
add("c");
add("d");
add("e");
add("f");
add("g");
}
};
}
/**
* 延迟执行特性,在聚合操作之前都可以添加相应元素
*/
@Test
public void test() {
Stream<String> words = wordList.stream();
wordList.add("END");
long n = words.distinct().count();
System.out.println(n); // 结果是 8
}
3.3 常用api
- 创建Stream
// 1. Arrays.stream()
Integer[] arr = new Integer[]{3,4,5,49,16,27,12,56,123,74,46,489};
long count = Arrays.stream(arr).filter(i -> i > 20).count();
// 2. Stream.of()
Integer[] array = new Integer[]{3,4,8,16,19,27,23,99,76,232,33,96};
long count = Stream.of(array).filter(i->i>20).count();
long sum = Stream.of(12,77,59,3,654).filter(i->i>20).mapToInt(Integer::intValue).sum();
System.out.println("count:"+count+",sum:"+sum);
// 3. Collection.stream()
List<Integer> numbers = new ArrayList<Integer>() {
{
add(4);
add(7);
add(8);
add(3);
add(0);
}
};
numbers.stream().sorted(Comparator.reverseOrder()).forEach(i -> {
System.out.print(i + " ");
});
>2. filter
这是一个Stream的过滤转换,此方法会生成一个新的流,其中包含符合某个特定条件的所有元素,filter接受一个函数作为参数,该函数用Lambda表达式表示
```java
List<Integer> integerList = Lists.newArrayList();
integerList.add(15);
integerList.add(32);
integerList.add(5);
integerList.add(232);
integerList.add(56);
List<Integer> after = integerList.stream()
.filter(i->i>50)
.collect(Collectors.toList());
System.out.println(after);//232,56
- map
map方法指对一个流中的值进行某种形式的转换。需要传递给它一个转换的函数作为参数
List<Integer> integerList = Lists.newArrayList();
integerList.add(15);
integerList.add(32);
integerList.add(5);
integerList.add(232);
integerList.add(56);
//将Integer类型转换成String类型
List<String> afterString = integerList.stream()
.map(i->String.valueOf(i)).collect(Collectors.toList());
- flatMap
将多个Stream连接成一个Stream,这时候不是用新值取代Stream的值,与map有所区别,这是重新生成一个Stream对象取而代之
List<String> words = new ArrayList<String>();
words.add("your");
words.add("name");
public static Stream<Character> characterStream(String s){
List<Character> result = new ArrayList<>();
for (char c : s.toCharArray())
result.add(c);
return result.stream();
}
Stream<Stream<Character>> result = words.map(w -> characterStream(w));
//[['y', 'o', 'u', 'r'], ['n', 'a', 'm', 'e']]
Stream<Character> letters = words.flatMap(w -> characterStream(w));
//['y', 'o', 'u', 'r', 'n', 'a', 'm', 'e']
- limit方法和skip方法
limit(n)方法会返回一个包含n个元素的新的流(若总长小于n则返回原始流)
skip(n)方法正好相反,它会丢弃掉前面的n个元素
用limit和skip方法一起使用就可以实现日常的分页功能:
List<Integer> pageList = myList.stream()
.skip(pageNumber*pageSize)
.limit(pageSize).collect(Collectors.toList());
- distinct方法和sorted方法
-
distinct方法会根据原始流中的元素返回一个具有相同顺序、去除了重复元素的流,这个操作显然是需要记住之前读取的元素
-
sorted方法是需要遍历整个流的,并在产生任何元素之前对它进行排序。
String[] arr1 = {"abc","a","bc","abcd"};
// 按照字符长度排序
Arrays.stream(arr1).sorted(Comparator.comparing(String::length)).forEach(System.out::println);
/**
* 倒序
* reversed(),java8泛型推导的问题,所以如果comparing里面是非方法引用的lambda表达式就没办法直接使用reversed()
* Comparator.reverseOrder():也是用于翻转顺序,用于比较对象(Stream里面的类型必须是可比较的)
* Comparator. naturalOrder():返回一个自然排序比较器,用于比较对象(Stream里面的类型必须是可比较的)
*/
@Test
public void testSorted2_(){
Arrays.stream(arr1).sorted(Comparator.comparing(String::length).reversed()).forEach(System.out::println);
Arrays.stream(arr1).sorted(Comparator.reverseOrder()).forEach(System.out::println);
Arrays.stream(arr1).sorted(Comparator.naturalOrder()).forEach(System.out::println);
}
/**
* thenComparing
* 先按照首字母排序
* 之后按照String的长度排序
*/
@Test
public void testSorted3_(){
Arrays.stream(arr1).sorted(Comparator.comparing(this::com1).thenComparing(String::length)).forEach(System.out::println);
}
public char com1(String x){
return x.charAt(0);
}
- Collect
// 将一个流收集到一个List中,只需要这样写就可以。
List<Integer> thereList = hereList.stream().collect(Collectors.toList());
// 收集到Set中可以这样用
Set<Integer> thereSet = hereList.stream().collect(Collectors.toSet());
// 收集到Set时,控制Set的类型,可以这样。
TreeSet<Integer> treeSet = hereList.stream()
.collect(Collectors.toCollection(TreeSet::new));
- 聚合操作
聚合是指将流汇聚为一个值,以便在程序中使用。聚合方法都是终止操作,聚合方法包括sum,count,max,min
@Before
public void init(){
arr = new String[]{"b","ab","abc","abcd","abcde"};
}
/**
* max、min
* 最大最小值
*/
@Test
public void testMaxAndMin(){
Stream.of(arr).max(Comparator.comparing(String::length)).ifPresent(System.out::println);
Stream.of(arr).min(Comparator.comparing(String::length)).ifPresent(System.out::println);
}
/**
* count
* 计算数量
*/
@Test
public void testCount(){
long count = Stream.of(arr).count();
System.out.println(count);
}
/**
* findFirst
* 查找第一个
*/
@Test
public void testFindFirst(){
String str = Stream.of(arr).parallel().filter(x->x.length()>3).findFirst().orElse("noghing");
System.out.println(str);
}
/**
* findAny
* 找到所有匹配的元素
* 对并行流十分有效
* 只要在任何片段发现了第一个匹配元素就会结束整个运算
*/
@Test
public void testFindAny(){
Optional<String> optional = Stream.of(arr).parallel().filter(x->x.length()>3).findAny();
optional.ifPresent(System.out::println);
}
/**
* anyMatch
* 是否含有匹配元素
*/
@Test
public void testAnyMatch(){
Boolean aBoolean = Stream.of(arr).anyMatch(x->x.startsWith("a"));
System.out.println(aBoolean);
}
@Test
public void testStream1() {
Optional<Integer> optional = Stream.of(1,2,3).filter(x->x>1).reduce((x,y)->x+y);
System.out.println(optional.get());
}
- 分组和分片
Student[] students;
@Before
public void init(){
students = new Student[100];
for (int i=0;i<30;i++){
Student student = new Student("user1",i);
students[i] = student;
}
for (int i=30;i<60;i++){
Student student = new Student("user2",i);
students[i] = student;
}
for (int i=60;i<100;i++){
Student student = new Student("user3",i);
students[i] = student;
}
}
/**
* 按照名称分组
*
*/
@Test
public void testGroupBy1(){
Map<String,List<Student>> map = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName));
map.forEach((x,y)-> System.out.println(x+"->"+y));
}
/**
* 如果只有两类,使用partitioningBy会比groupingBy更有效率,按照分数是否大于50分组
*/
@Test
public void testPartitioningBy(){
Map<Boolean,List<Student>> map = Arrays.stream(students).collect(Collectors.partitioningBy(x->x.getScore()>50));
map.forEach((x,y)-> System.out.println(x+"->"+y));
}
/**
* downstream指定类型
*/
@Test
public void testGroupBy2(){
Map<String,Set<Student>> map = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.toSet()));
map.forEach((x,y)-> System.out.println(x+"->"+y));
}
/**
* downstream 聚合操作
*/
@Test
public void testGroupBy3(){
/**
* counting
*/
Map<String,Long> map1 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.counting()));
map1.forEach((x,y)-> System.out.println(x+"->"+y));
/**
* summingInt
*/
Map<String,Integer> map2 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.summingInt(Student::getScore)));
map2.forEach((x,y)-> System.out.println(x+"->"+y));
/**
* maxBy
*/
Map<String,Optional<Student>> map3 = Arrays.stream(students).collect(groupingBy(Student::getName,maxBy(Comparator.comparing(Student::getScore))));
map3.forEach((x,y)-> System.out.println(x+"->"+y));
/**
* mapping
*/
Map<String,Set<Integer>> map4 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.mapping(Student::getScore,Collectors.toSet())));
map4.forEach((x,y)-> System.out.println(x+"->"+y));
}
3.4 原始类型流
在数据量比较大的情况下,将基本数据类型(int,double...)包装成相应对象流的做法是低效的,因此,我们也可以直接将数据初始化为原始类型流,在原始类型流上的操作与对象流类似,我们只需要记住两点
-
1.原始类型流的初始化
-
2.原始类型流与流对象的转换
DoubleStream doubleStream;
IntStream intStream;
/**
* 原始类型流的初始化
*/
@Before
public void testStream1(){
doubleStream = DoubleStream.of(0.1,0.2,0.3,0.8);
intStream = IntStream.of(1,3,5,7,9);
IntStream stream1 = IntStream.rangeClosed(0,100);
IntStream stream2 = IntStream.range(0,100);
}
/**
* 流与原始类型流的转换
*/
@Test
public void testStream2(){
Stream<Double> stream = doubleStream.boxed();
doubleStream = stream.mapToDouble(Double::new);
}
3.5 并行流
和迭代器不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item;
Stream具有平行处理能力,处理的过程会分而治之,也就是将一个大任务切分成多个小任务,这表示每个任务都是一个操作
//parallel方法可以将任意的串行流转换为一个并行流
Stream.of(roomList).parallel();
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEach(out::println);
//展示顺序不一定会是1、2、3、4、5、6、7、8、9,而可能是任意的顺序
sorted()、distinct()等对并行流的影响
-
1.并行流和排序是不冲突的,
-
2.一个流是否是有序的,对于一些api可能会提高执行效率,对于另一些api可能会降低执行效率,
-
3.如果想要输出的结果是有序的,对于并行的流需要使用forEachOrdered(forEach的输出效率更高)
public class Test {
List<Integer> list;
@Before
public void init() {
Random random = new Random();
list = Stream.generate(() -> random.nextInt(100)).limit(100000000).collect(toList());
}
@org.junit.Test
public void test1() {
long begin1 = System.currentTimeMillis();
list.stream().filter(x->(x > 10)).filter(x->x<80).count();
long end1 = System.currentTimeMillis();
System.out.println("串行流执行时间:" + (end1-begin1));
list.stream().parallel().filter(x->(x > 10)).filter(x->x<80).count();
long end2 = System.currentTimeMillis();
System.out.println("并行流执行时间: " + (end2-end1));
long begin1_ = System.currentTimeMillis();
list.stream().filter(x->(x > 10)).filter(x->x<80).distinct().sorted().count();
long end1_ = System.currentTimeMillis();
System.out.println("串行流执行排序时间: " + (end1-begin1));
list.stream().parallel().filter(x->(x > 10)).filter(x->x<80).distinct().sorted().count();
long end2_ = System.currentTimeMillis();
System.out.println("并行流执行排序时间: " + (end2_-end1_));
}
}
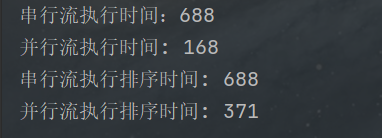
对于串行流.distinct().sorted()方法对于运行时间没有影响,但是对于并行流,会使得运行时间大大增加,因此对于包含sorted、distinct()等与全局数据相关的操作,不推荐使用并行流。
