Redis06---Redis持久化以及发布订阅
1. Redis持久化
-
Redis 是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以 Redis 提供了持久化功能!
-
Redis持久化
1.1 RDB(Redis DataBase)
-
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
-
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件
-
rdb保存的文件是dump.rdb
工作原理
在进行 RDB 的时候,redis 的主线程是不会做 io 操作的,主线程会 fork 一个子线程来完成该操作;
-
Redis 调用forks。同时拥有父进程和子进程。
-
子进程将数据集写入到一个临时 RDB 文件中。
-
当子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文件。
这种工作方式使得 Redis 可以从写时复制(copy-on-write)机制中获益(因为是使用子进程进行写操作,而父进程依然可以接收来自客户端的请求。)
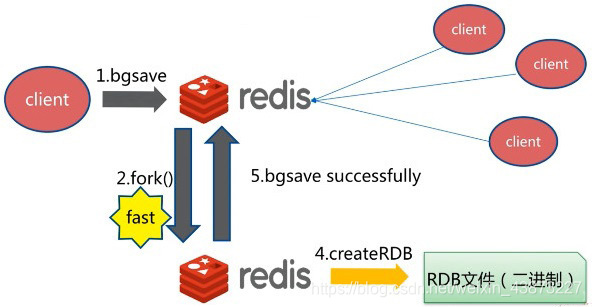
触发机制
-
save的规则满足的情况下,会自动触发rdb规则
-
执行 flushall 命令,也会触发我们的rdb规则!
-
退出redis,也会产生 rdb 文件!
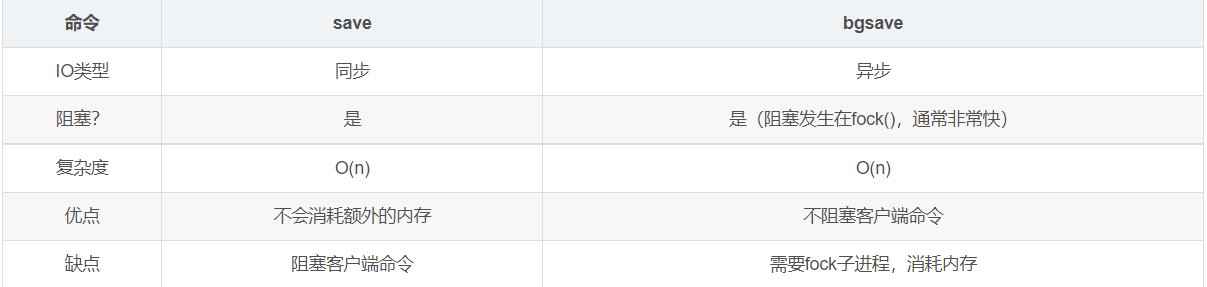
bgsave和save对比
-
由于
save命令是同步命令,会占用Redis的主进程。若Redis数据非常多时,save命令执行速度会非常慢,阻塞所有客户端的请求。 -
bgsave是异步进行,进行持久化的时候,redis 还可以将继续响应客户端请求
如何恢复rdb文件
-
只需要将rdb文件放在我们redis启动目录就可以,redis启动的时候会自动检查dump.rdb 恢复其中的数据!
-
查看需要存在的位置
127.0.0.1:6379> config get dir
"dir"
"/usr/local/bin" # 如果在这个目录下存在 dump.rdb 文件,启动就会自动恢复其中的数据
RDB优点缺点
【RDB优点】
1、适合大规模的数据恢复!
2、对数据的完整性要不高!
【RDB缺点】
1、需要一定的时间间隔进程操作!如果redis意外宕机了,这个最后一次修改数据就没有的了!
2、fork进程的时候,会占用一定的内容空间
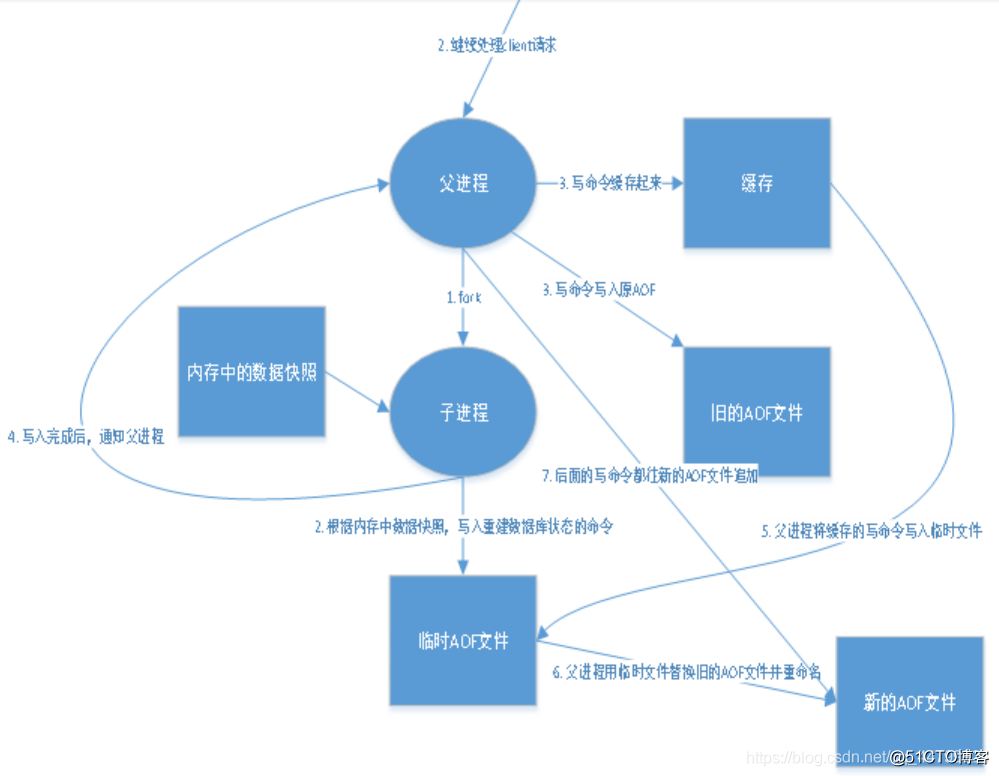
1.2 AOF(Append Only File)
-
以日志的形式来记录每个写操作,将Redis执行过的所有指令记录下来(读操作不记录),只许追加文件但不可以改写文件
-
redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
-
Aof保存的是
appendonly.aof文件
1、默认是不开启的,我们需要手动进行配置!我们只需要将 appendonly 改为yes就开启了 aof!
2、如果这个 aof 文件有错误,这时候 redis 是启动不起来的吗,我们需要修复这个aof文件 redis-check-aof --fix appendonly.aof
3、 如果文件正常,重启就可以直接恢复了,但是可能会丢失少量数据
4、重写规则说明,aof 默认就是文件的无限追加,文件会越来越大!如果 aof 文件大于 64m,太大了! fork一个新的进程来将我们的文件进行重写
appendonly no # 默认是不开启aof模式的,默认是使用rdb方式持久化的,在大部分所有的情况下, rdb完全够用!
appendfilename "appendonly.aof" # 持久化的文件的名字
# appendfsync always # 每次修改都会 sync。消耗性能
appendfsync everysec # 每秒执行一次 sync,可能会丢失这1s的数据!
# appendfsync no # 不执行 sync,这个时候操作系统自己同步数据,速度最快!
# rewrite 重写
优点和缺点
【优点】
1、每一次修改都同步,文件的完整会更加好!
2、每秒同步一次,可能会丢失一秒的数据
3、从不同步,效率最高的!
【缺点】
1、相对于数据文件来说,aof远远大于 rdb,修复的速度也比 rdb慢!
2、Aof 运行效率也要比 rdb 慢,所以我们redis默认的配置就是rdb持久化!
1.3 扩展
1、RDB 持久化方式能够在指定的时间间隔内对你的数据进行快照存储
2、AOF 持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以Redis 协议追加保存每次写的操作到文件末尾,Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
3、只做缓存,如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化
4、同时开启两种持久化方式在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。RDB 的数据不实时,同时使用两者时服务器重启也只会找AOF文件,那要不要只使用AOF呢?作者建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有AOF可能潜在的Bug,留着作为一个万一的手段。
5、性能建议因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留 save 900 1 这条规则。如果Enable AOF ,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了,代价一是带来了持续的IO,二是AOF rewrite 的最后将 rewrite 过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上,默认超过原大小100%大小重写可以改到适当的数值。如果不Enable AOF ,仅靠 Master-Slave Repllcation 实现高可用性也可以,能省掉一大笔IO,也减少了rewrite时带来的系统波动。代价是如果Master/Slave 同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个 Master/Slave 中的 RDB文件,载入较新的那个,微博就是这种架构。
2. Redis发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
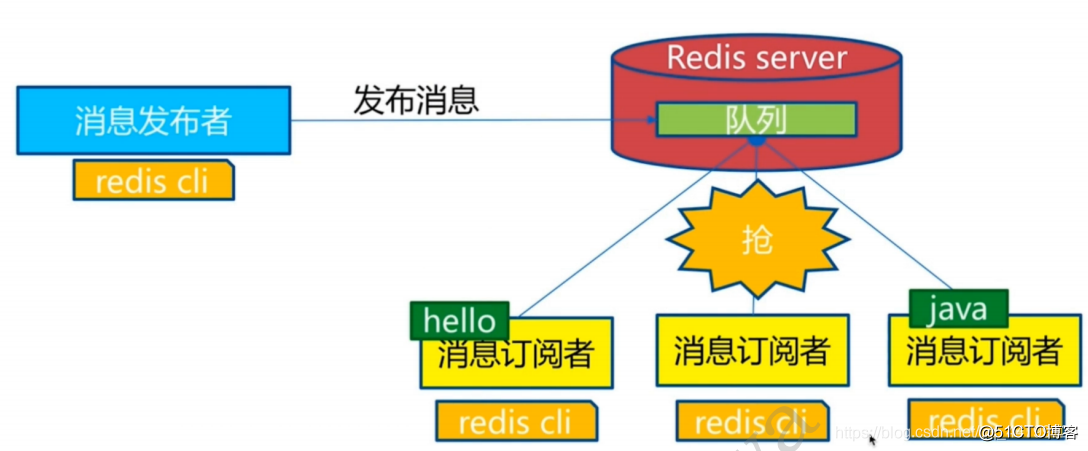
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
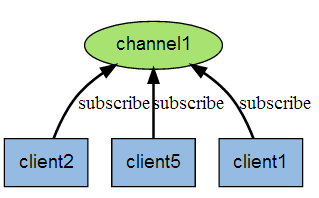
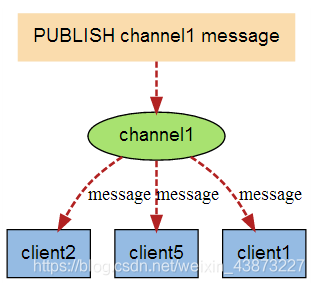
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
命令
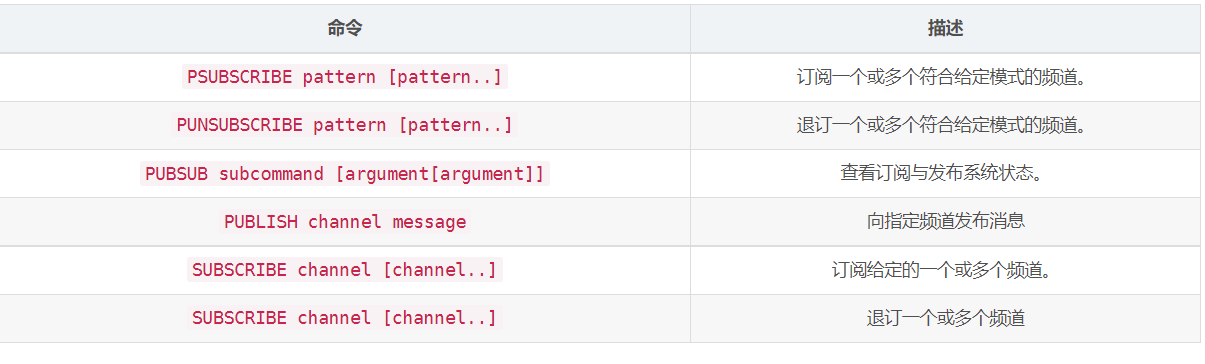
示例
------------订阅端----------------------
127.0.0.1:6379> SUBSCRIBE sakura # 订阅sakura频道
Reading messages... (press Ctrl-C to quit) # 等待接收消息
1) "subscribe" # 订阅成功的消息
2) "sakura"
3) (integer) 1
1) "message" # 接收到来自sakura频道的消息 "hello world"
2) "sakura"
3) "hello world"
1) "message" # 接收到来自sakura频道的消息 "hello i am sakura"
2) "sakura"
3) "hello i am sakura"
--------------消息发布端-------------------
127.0.0.1:6379> PUBLISH sakura "hello world" # 发布消息到sakura频道
(integer) 1
127.0.0.1:6379> PUBLISH sakura "hello i am sakura" # 发布消息
(integer) 1
-----------------查看活跃的频道------------
127.0.0.1:6379> PUBSUB channels
1) "sakura"
原理
每个 Redis 服务器进程都维持着一个表示服务器状态的 redis.h/redisServer 结构, 结构的 pubsub_channels 属性是一个字典, 这个字典就用于保存订阅频道的信息,其中,字典的键为正在被订阅的频道, 而字典的值则是一个链表, 链表中保存了所有订阅这个频道的客户端。客户端订阅,就被链接到对应频道的链表的尾部,退订则就是将客户端节点从链表中移除。
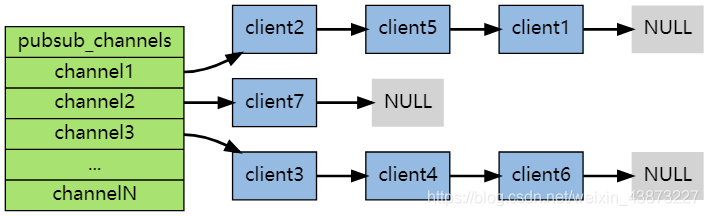
缺点
1、如果一个客户端订阅了频道,但自己读取消息的速度却不够快的话,那么不断积压的消息会使redis输出缓冲区的体积变得越来越大,这可能使得redis本身的速度变慢,甚至直接崩溃。
2、这和数据传输可靠性有关,如果在订阅方断线,那么他将会丢失所有在短线期间发布者发布的消息。
应用
-
消息订阅:公众号订阅,微博关注等等(起始更多是使用消息队列来进行实现)
-
多人在线聊天室。
-
稍微复杂的场景,我们就会使用消息中间件MQ处理。
