python爬取疫情防控数据
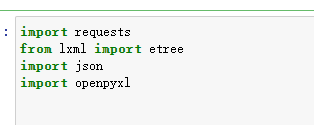
需要添加和调用的库
具体代码
1 import requests 2 from lxml import etree 3 import json 4 import openpyxl 5 6 7 #通用爬虫 8 url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia' 9 headers = { 10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36" 11 } 12 #发出请求并获取相应的网页数据 13 response = requests.get(url=url,headers=headers).text 14 #在使用xpath的时候要用树形态 15 html = etree.HTML(response) 16 #用xpath来获取我们之前找到的页面json数据 并打印看看 17 json_text = html.xpath('//script[@type="application/json"]/text()') 18 json_text = json_text[0] 19 print(json_text)
#用python本地自带的库转换一下json数据 result = json.loads(json_text) # print(result) #通过打印出转换的对象我们可以看到我们要的数据都要key为component对应的值之下 所以现在我们将值拿出来 result = result["component"] #再次打印看看结果 # print(result) # 获取国内当前数据 result = result[0]['caseList'] print(result)
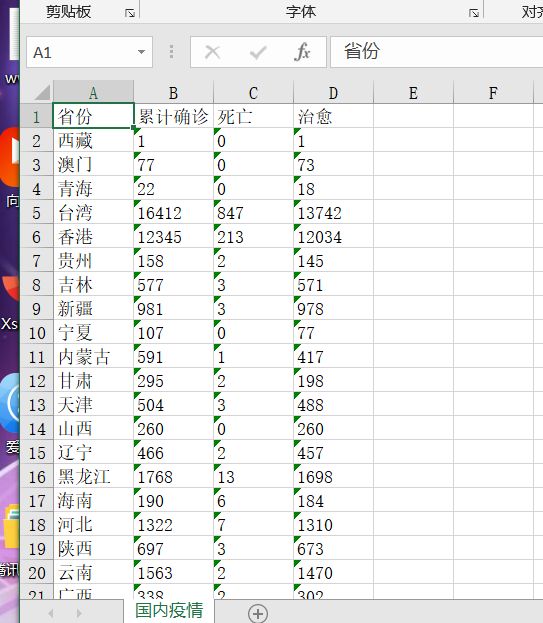
# 创建工作簿 wb = openpyxl.Workbook() # 创建工作表 ws = wb.active # 设置表的标题 ws.title = "国内疫情" # 写入表头 ws.append(["省份","累计确诊","死亡","治愈"]) #获取各省份的数据并写入 for line in result: line_name = [line["area"],line["confirmed"],line["died"],line["crued"]] for ele in line_name: if ele == '': ele = 0 ws.append(line_name) #保存到excel中 wb.save('./国内疫情数据.xlsx')
爬取的数据