

MYSQL水平拆分与垂直拆分

目前很多互联网系统都存在单表数据量过大的问题,这就降低了查询速度,影响了客户体验。为了提高查询速度,我们可以优化sql语句,优化表结构和索引,不过对那些百万级千万级的数据库表,即便是优化过后,查询速度还是满足不了要求。这时候我们就可以通过分表降低单次查询数据量,从而提高查询速度,一般分表的方式有两种:水平拆分和垂直拆分,两者各有利弊,适用于不同的情况。
水平拆分
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。
这里写图片描述 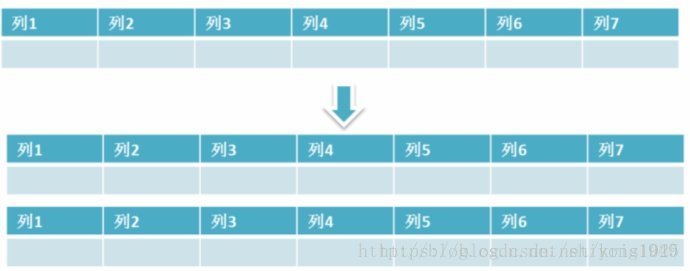
通常情况下,我们使用取模的方式来进行表的拆分;比如一张有400W的用户表users,为提高其查询效率我们把其分成4张表users1,users2,users3,users4
通过用ID取模的方法把数据分散到四张表内Id%4+1 = [1,2,3,4]
然后查询,更新,删除也是通过取模的方法来查询。
例:QQ的登录表。假设QQ的用户有100亿,如果只有一张表,每个用户登录的时候数据库都要从这100亿中查找,会很慢很慢。如果将这一张表分成100份,每张表有1亿条,就小了很多,比如qq0,qq1,qq1…qq99表。
用户登录的时候,可以将用户的id%100,那么会得到0-99的数,查询表的时候,将表名qq跟取模的数连接起来,就构建了表名。比如123456789用户,取模的89,那么就到qq89表查询,查询的时间将会大大缩短。
另外部分业务逻辑也可以通过地区,年份等字段来进行归档拆分;进行拆分后的表,只能满足部分查询的高效查询需求,这时我们就要在产品策划上,从界面上约束用户查询行为。比如我们是按年来进行归档拆分的,这个时候在页面设计上就约束用户必须要先选择年,然后才能进行查询;在做分析或者统计时,由于是自己人的需求,多点等待其实是没关系的,并且并发很低,这个时候可以用union把所有表都组合成一张视图来进行查询,然后再进行查询。
水平拆分的优点:
◆表关联基本能够在数据库端全部完成;
◆不会存在某些超大型数据量和高负载的表遇到瓶颈的问题;
◆应用程序端整体架构改动相对较少;
◆事务处理相对简单;
◆只要切分规则能够定义好,基本上较难遇到扩展性限制;
水平切分的缺点:
◆切分规则相对更为复杂,很难抽象出一个能够满足整个数据库的切分规则;
◆后期数据的维护难度有所增加,人为手工定位数据更困难;
◆应用系统各模块耦合度较高,可能会对后面数据的迁移拆分造成一定的困难。
垂直拆分
垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。表的记录并不多,但是字段却很长,表占用空间很大,检索表的时候需要执行大量的IO,严重降低了性能。这时需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
这里写图片描述
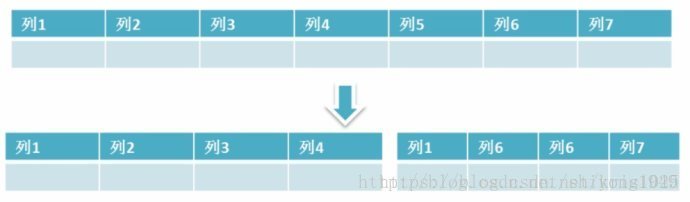
通常我们按以下原则进行垂直拆分:
1,把不常用的字段单独放在一张表;,
2,把text,blob等大字段拆分出来放在附表中;
3,经常组合查询的列放在一张表中;
例如学生答题表tt:有如下字段:
Id name 分数 题目 回答
其中题目和回答是比较大的字段,id name 分数比较小。
如果我们只想查询id为8的学生的分数:select 分数 from tt where id = 8;虽然知识查询分数,但是题目和回答这两个大字段也是要被扫描的,很消耗性能。但是我们只关心分数,并不想查询题目和回答。这就可以使用垂直分割。我们可以把题目单独放到一张表中,通过id与tt表建立一对一的关系,同样将回答单独放到一张表中。这样我们插叙tt中的分数的时候就不会扫描题目和回答了。
垂直切分的优点
◆ 数据库的拆分简单明了,拆分规则明确;
◆ 应用程序模块清晰明确,整合容易;
◆ 数据维护方便易行,容易定位;
垂直切分的缺点
◆ 部分表关联无法在数据库级别完成,需要在程序中完成;
◆ 对于访问极其频繁且数据量超大的表仍然存在性能平静,不一定能满足要求;
◆ 事务处理相对更为复杂;
◆ 切分达到一定程度之后,扩展性会遇到限制;
◆ 过读切分可能会带来系统过渡复杂而难以维护。



