面试:TCP、UDP如何解决丢包问题
文章目录
一、TCP丢包原因、解决办法
-
1.1 TCP为什么会丢包
-
1.2 TCP传输协议如何解决丢包问题
-
1.3 其他丢包情况(拓展)
-
1.4 补充
- 1.4.1 TCP端口号
- 1.4.2 多个TCP请求的逻辑
- 1.4.3 处理大量TCP连接请求的方法
- 1.4.4 总结
二、UDP丢包
-
2.1 UDP协议
- 2.1.1 UDP简介
- 2.1.2 UDP协议特点
- 2.1.3 基于UDP实现的用户层协议
- 2.1.4 TCP与UDP的区别
-
2.2 UDP丢包原因
-
2.3 如何解决UDP丢包问题
一、TCP丢包原因、解决办法
TCP是基于不可靠的网络实现可靠的传输,肯定也会存在掉包的情况,如果通信中发现缺少数据或者丢包,那么,最大的可能在于程序发送的过程或者接收的过程出现问题。
例如服务端要给客户端发送大量数据,Send频率很高,那么就很有可能在Send环节出现错误(1.程序处理逻辑错误,2.多线程同步问题,3.缓冲区溢出等),如果没有对Send发送失败做处理,那么客户端收到的数据比理论要收到的数据少,就会造成丢数据,丢包现象。
1.1 TCP为什么会丢包
TCP协议(Transimission Control Protocol)是以一种面向连接的、可靠的、基于字节流的传输层通信协议。
TCP是基于不可靠的网路实现可靠传输,肯定会存在丢包问题。
如果在通信过程中,发现缺少数据或者丢包,那边么最大的可能性是程序发送过程或者接受过程中出现问题
例如:我有2台服务器 ,A和B服务器。A服务器发送数据给B服务器频率过高时,B服务器来不及处理,造成数据丢包。(原因可能是程序逻辑问题,多线程同步问题,缓冲区溢出问题)。
如果A服务器不对发送频率进行控制,或者数据进行重发的话,那么B服务器收到数据就会少。就会造成丢失数据
1.2 TCP传输协议如何解决丢包问题
为了保障传输可靠性,TCP协议本身有如下规定:
- 基于数据块传输/数据分片:应用数据被分割成TCP认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
- 对失序数据包重新排序以及去重:TCP为了保证不发生丢包,就给每个包一个序列号,有了序列号能够将接收到的数据根据序列号排序,并且去掉亚复序列号的数据就可以实现数据包去重。
- 校验和:TCP将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
- 重传机制:在数据包丢失或延迟的情况下,重新发送数据包,直到收到对方的确认应答(ACK)。TCP重传机制主要有:基于计时器的重传(也就是超时重传)、快速重传(基于接收端的反馈信息来引发重传)、SACK(在快速重传的基础上,返回最近收到的报文段的序列号范围,这样客户端就知道,哪些数据包已经到达服务器了)、D-SACK(重复SACK,在SACK的基础上,额外携带信息,告知发送方有哪些数据包自己重复接收了)。关于重传机制的详细介绍,可以查看详解TCP超时与重传机制这篇文章。
- 流量控制(滑动窗口):TCP连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP使用的流量控制协议是可变大小的滑动窗口协议(TCP利用滑动窗口实现流量控制)。
- 拥塞控制(慢开始、拥塞避免、快重传和快恢复):当网络拥塞时,减少数据的发送。TCP在发送数据的时候,需要考虑两个因素:一是接收方的接收能力,二是网络的拥塞程度。接收方的接收能力由滑动窗口表示,表示接收方还有多少缓冲区可以用来接收数据。网络的拥塞程度由拥塞窗口表示,它是发送方根据网络状况自己维护的一个值,表示发送方认为可以在网络中传输的数据量。发送方发送数据的大小是滑动窗口和拥塞窗口的最小值,这样可以保证发送方既不会超过接收方的接收能力,也不会造成网络的过度拥塞。
- 自主重传ARQ(停止等待ARQ、连续ARQ):接收端接收到分片数据时,根据分片数据序号向发送端发送一个确认,超时重传
关于TCP如何保障传输可靠性,可查阅 计算机网络常见面试题(一):TCP/IP五层模型、TCP三次握手、四次挥手,TCP传输可靠性保障、ARQ协议
1.3 其他丢包情况(拓展)
按理说,TCP协议经过处理、已能保障传输可靠性,但是IP协议是不可靠、无连接的,以下情况仍有可能会丢包:
- 服务端要给客户端发送大量数据时,Send频率很高,Send环节可能出现错误(程序处理逻辑错误、多线程同步问题、缓冲区溢出等)
- 有大量TCP连接请求
- 网络较差(譬如握手过程中丢包) :TCP 本身具有重传机制,但在极端情况下,丢包仍然可能发生
对应解决方案如下:
1、服务端要给客户端发送大量数据时,Send频率很高,Send环节可能出现错误(程序处理逻辑错误、多线程同步问题、缓冲区溢出等)
- 对Send失败做处理
2、有大量TCP连接请求
- 优化服务器配置、使用高效的 I/O 处理机制(多线程、多进程、事件驱动模型、异步IO)、负载均衡和合理管理连接,提高服务器的并发处理能力和稳定性
- 具体见本文1.4.3小节
3、网络较差(譬如握手过程中丢包) :TCP 本身具有重传机制,但在极端情况下,丢包仍然可能发生
(1)调整TCP参数
- 增加重传次数和超时时间:可以通过调整内核参数来增加 TCP 的重传次数和超时时间,以提高在网络不稳定情况下的可靠性
# 增加重传次数
sudo sysctl -w net.ipv4.tcp_retries2=15
# 增加超时时间
sudo sysctl -w net.ipv4.tcp_fin_timeout=30
- 调整拥塞控制算法:选择合适的拥塞控制算法可以改善网络性能。Linux 提供了多种拥塞控制算法,如
reno、cubic、bbr等
# 查看当前使用的拥塞控制算法
sysctl net.ipv4.tcp_congestion_control
# 设置为 BBR( Bottleneck Bandwidth and RTT)
sudo sysctl -w net.ipv4.tcp_congestion_control=bbr
(2)使用TCP快速重传和恢复
- 快速重传:快速重传允许发送方在接收到三个重复的 ACK 后立即重传丢失的段,而不是等待重传计时器到期
# 开启快速重传
sudo sysctl -w net.ipv4.tcp_frto=2
- 快速恢复:快速恢复是在快速重传之后的一种机制,旨在更快地恢复连接
(3)使用TCP快速打开
TCP 快速打开(TCP Fast Open,简称 TFO)是一种优化 TCP 连接建立过程的技术。传统的 TCP 连接建立需要三次握手(SYN, SYN-ACK, ACK),而在某些情况下,这三次握手会导致额外的延迟。TCP 快速打开允许客户端在第一次 SYN 包中携带数据,从而减少了一次往返时间(RTT),提高了连接建立的速度。
TCP 快速打开的工作原理
- 客户端发送 SYN 包:客户端在发送 SYN 包时,不仅包含 SYN 标志,还携带了数据。
- 服务器响应 SYN-ACK 包:服务器在响应 SYN-ACK 包时,也包含对客户端数据的确认。
- 客户端发送 ACK 包:客户端发送 ACK 包,同时可以继续发送更多数据。
- 数据传输:连接建立完成,双方可以立即开始数据传输。
TCP 快速打开(TCP Fast Open)可以减少建立连接的时间,从而减少丢包的可能性。
# 开启 TCP 快速打开
sudo sysctl -w net.ipv4.tcp_fastopen=3
参数3的含义是:客户端和服务器都支持 TFO、客户端可以发送 TFO 请求、服务器可以接受 TFO 请求
(4)优化网络设备和驱动、调整网络设备参数
可以通过调整网络设备的参数来优化性能,例如增加接收缓冲区大小。
# 增加接收缓冲区大小
sudo ethtool -G eth0 rx 4096
(5)使用网络监控工具
使用网络监控工具(如 Wireshark、tcpdump)来监控和分析网络流量,及时发现和解决问题。
# 使用 tcpdump 抓包
sudo tcpdump -i eth0 -w capture.pcap
1.4 补充
TCP(传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。TCP 端口是用于标识网络应用的逻辑地址。每个 TCP 连接由源 IP 地址、源端口号、目标 IP 地址和目标端口号唯一标识。
- 端口号:是一个 16 位的数字,范围从 0 到 65535。其中,0-1023 是众所周知的系统端口,通常由系统进程使用;1024-49151 是注册端口,可以被用户进程使用;49152-65535 是动态或私有端口,通常由操作系统自动分配。
1.4.1 TCP端口号
TCP(传输控制协议)端口号是一个 16 位的数字,用于标识网络应用程序的逻辑地址。每个 TCP 连接由四个部分唯一标识:
- 源 IP 地址
- 源端口号
- 目标 IP 地址
- 目标端口号
端口号的范围是从 0 到 65535,其中:
- 0-1023:熟知端口,通常由系统进程使用。
- 1024-49151:注册端口,可以被用户进程使用。
- 49152-65535:动态或私有端口,通常由操作系统自动分配。
1.4.2 多个TCP请求的逻辑
当有多个 TCP 请求时,这些请求并不一定都使用同一个端口。实际上,每个连接都有唯一的四元组(源 IP 地址、源端口号、目标 IP 地址、目标端口号)来区分。
1)服务器端口
服务器通常监听一个固定的端口,例如 HTTP 服务通常监听 80 端口,HTTPS 服务通常监听 443 端口。当客户端发起连接请求时,服务器的监听端口会接受连接请求,并为每个连接分配一个新的端口。
2)客户端端口
客户端发起连接时,操作系统会为每个连接分配一个临时端口(通常是动态端口,范围在 49152-65535 之间)。这个临时端口在连接期间是唯一的。
3)示例说明
假设有一个 Web 服务器监听 80 端口,两个客户端分别从不同的 IP 地址发起连接:
- 客户端 A:IP 地址 192.168.1.1,操作系统为其分配临时端口 50000
- 客户端 B:IP 地址 192.168.1.2,操作系统为其分配临时端口 50001
服务器接收到这两个连接请求后,会为每个连接分配一个新的端口:
- 连接 1:(192.168.1.1:50000, 服务器 IP:80)
- 连接 2:(192.168.1.2:50001, 服务器 IP:80)
尽管服务器监听的是同一个端口(80),但由于每个连接的四元组不同,服务器可以区分这些连接并同时处理它们。
1.4.3 处理大量TCP连接请求的方法
当有大量 TCP 连接请求时,服务器需要采取一些措施来有效地管理和处理这些连接,以保证系统的性能和稳定性。以下是一些常见的处理方法:
1. 使用高性能服务器
- 多核处理器:使用多核处理器可以提高服务器的并发处理能力。
- 高内存:增加服务器的内存容量,以支持更多的连接和更大的缓存。
2. 优化网络配置
- 调整内核参数:优化 Linux 内核参数,如
net.core.somaxconn(最大监听队列长度)、net.ipv4.tcp_max_syn_backlog(SYN 队列长度)、net.ipv4.tcp_fin_timeout(FIN 超时时间)等。 - 使用 TCP 快速打开:启用 TCP 快速打开(TCP Fast Open)可以减少建立连接的时间。
3. 使用连接池
- 连接复用:使用连接池技术,复用已建立的连接,减少连接建立和断开的开销。
- 连接池管理:合理管理连接池的大小,避免过多的空闲连接占用资源。
4. 服务器端优化
-
多线程模型:使用多线程模型,每个线程处理一部分连接。
-
多进程模型:每个连接由一个独立的进程处理。这种方法可以利用多核处理器的优势,但进程间的通信和资源管理较为复杂。
-
事件驱动模型:使用事件驱动模型(如 epoll、kqueue),高效处理大量的 I/O 事件。这种方法可以高效地处理大量连接,适用于高并发场景
-
异步 I/O框架:使用异步 I/O 模型,如 Node.js、Python 的 asyncio,可以在单个线程中处理多个连接,提高并发处理能力。
5. 负载均衡
- 反向代理:使用反向代理服务器(如 Nginx、HAProxy)将请求分发到多个后端服务器,分散负载。
- 集群:构建服务器集群,通过负载均衡算法将请求分发到不同的节点。
6. 限制连接速率
- 限流:使用限流算法(如令牌桶、漏桶)限制客户端的连接速率,防止突发流量冲击。
- 连接超时:设置合理的连接超时时间,及时关闭不活跃的连接。
7. 优化应用程序
- 减少响应时间:优化应用程序的逻辑,减少每个请求的处理时间。
- 缓存:使用缓存机制,减少对后端数据库的访问频率。
- 异步处理:将耗时的操作异步处理,提高响应速度。
1.4.4 总结
- TCP 端口号:用于标识网络应用程序的逻辑地址,每个连接由四元组(源 IP 地址、源端口号、目标 IP 地址、目标端口号)唯一标识。
- 多个 TCP 请求:服务器监听一个固定端口,但每个连接都会分配一个唯一的四元组,因此可以同时处理多个连接。
- 处理大量 TCP 连接请求:优化服务器配置、使用高效的 I/O 处理机制(多线程、多进程、事件驱动模型、异步IO)、负载均衡和合理管理连接,提高服务器的并发处理能力和稳定性
- 其他丢包情况
- 服务端要给客户端发送大量数据时,Send频率很高,Send环节可能出现错误(程序处理逻辑错误、多线程同步问题、缓冲区溢出等) ——对Send失败做处理
- 有大量TCP连接请求 ——优化服务器配置、使用高效的 I/O 处理机制(多线程、多进程、事件驱动模型、异步IO)、负载均衡和合理管理连接,提高服务器的并发处理能力和稳定性
- 网络较差(譬如握手过程中丢包) :TCP 本身具有重传机制,但在极端情况下,丢包仍然可能发生 ——调整TCP参数、使用TCP快速重传和恢复、使用TCP快速打开、优化网络设备和驱动、调整网络设备参数、使用网络监控工具
二、UDP丢包
2.1 UDP协议
2.1.1 UDP简介
- UDP(User Datagram Protocol)是一种无连接的传输层协议,它提供了一种简单的、不可靠的数据传输服务。
- UDP 提供了不面向连接的通信,且不对传送的数据报进行可靠的保证,适用于一次传送少量的数据,不适用于传输大量的数据。
- UDP属于网络协议栈中的传输层协议,直接负责数据的传输和接收
2.1.2 UDP协议特点
- 无连接:两台主机在使用UDP进行数据传输时,不需要建立连接,只需知道对端的IP和端口号即可把数据发送过去。
- 不可靠:UDP协议没有确认重传机制,如果因为网络故障导致报文无法发到对方,或者对方收到了报文,但是传输过程中乱序了,对方校验失败后把乱序的包丢了,UDP协议层也不会给应用层任何错误反馈信息。(在网络中,“不可靠”是个中性词,因为可靠就意味着要付出更多的代价去维护可靠,实现起来会复杂很多;而“不可靠”的话,实现起来会更简单)
- 面向数据报:UDP传输数据时,是以数据报文为单位一个个地发出去,然后一个个地接收的,这导致上面应用层无法灵活控制数据数据的读写次数和数量。
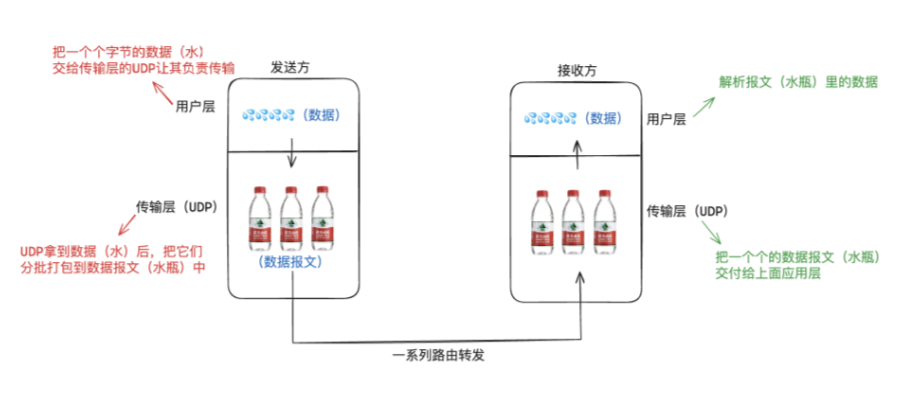
2.1.3 基于UDP实现的用户层协议
- NFS:网络文件系统
- TFTP:简单文件传输协议
- DHCP:动态主机配置协议
- BOOTP:启动协议(用于无盘设备启动)
- DNS:域名解析协议
2.1.4 TCP与UDP的区别
| TCP | UDP |
|---|---|
| 面向连接 | 无连接 |
| 提供可靠服务 | 不保证可靠交互 |
| 有状态 | 无状态 |
| 面向字节流 | 面向报文 |
| 传输效率较慢 | 传输效率较快 |
| 有拥塞控制 | 没有拥塞控制 |
| 每一条TCP连接只能是stron | 支持一对一、一对多、多对一、多对多 |
| 首部开销20字节 | 首部开销8字节 |
2.2 UDP丢包原因
1、接收端处理时间过长导致丢包:
调用recv方法接收端收到数据后,处理数据花了一些时间,处理完后再次调用recv方法,在这二次调用间隔里,发过来的包可能丢失。对于这种情况可以修改接收端,将包接收后存入一个缓冲区,然后迅速返回继续recv。
2、发送的包巨大丢包:
虽然send方法会帮你做大包切割成小包发送的事情,但包太大也不行。例如超过50K的一个udp包,不切割直接通过send方法发送也会导致这个包丢失。这种情况需要切割成小包再逐个send。
3、发送的包较大,超过接受者缓存导致丢包:
包超过mtu size数倍,几个大的udp包可能会超过接收者的缓冲,导致丢包。这种情况可以设置socket接收缓冲。以前遇到过这种问题,我把接收缓冲设置成64K就解决了。
4、发送的包频率太快:
虽然每个包的大小都小于mtu size 但是频率太快,例如40多个mut size的包连续发送中间不sleep,也有可能导致丢包。这种情况也有时可以通过设置socket接收缓冲解决,但有时解决不了。所以在发送频率过快的时候还是考虑sleep一下吧。
5、局域网内不丢包,公网上丢包:
这个问题我也是通过切割小包并sleep发送解决的。如果流量太大,这个办法也不灵了。总之udp丢包总是会有的,如果出现了用我的方法解决不了,还有这个几个方法: 要么减小流量,要么换tcp协议传输,要么做丢包重传的工作。
2.3 如何解决UDP丢包问题
1.发送频率过高导致丢包
很多人会不理解发送速度过快为什么会产生丢包,原因就是UDP的SendTo不会造成线程阻塞,也就是说,UDP的SentTo不会像TCP中的SendTo那样,直到数据完全发送才会return回调用函数,它不保证当执行下一条语句时数据是否被发送(SendTo方法是异步的)。这样,如果要发送的数据过多或者过大,那么在缓冲区满的那个瞬间要发送的报文就很有可能被丢失。至于对“过快”的解释,作者这样说:“A few packets a second are not an issue; hundreds or thousands may be an issue.”(一秒钟几个数据包不算什么,但是一秒钟成百上千的数据包就不好办了)。
要解决接收方丢包的问题很简单,首先要保证程序执行后马上开始监听(如果数据包不确定什么时候发过来的话),其次,要在收到一个数据包后最短的时间内重新回到监听状态,其间要尽量避免复杂的操作(比较好的解决办法是使用多线程回调机制)。
2.报文过大丢包
至于报文过大的问题,可以通过控制报文大小来解决,使得每个报文的长度小于MTU。以太网的MTU通常是1500 bytes,其他一些诸如拨号连接的网络MTU值为1280 bytes,如果使用speaking这样很难得到MTU的网络,那么最好将报文长度控制在1280 bytes以下。
3.发送方丢包
发送方丢包:内部缓冲区(internal buffers)已满,并且发送速度过快(即发送两个报文之间的间隔过短); 接收方丢包:Socket未开始监听; 虽然UDP的报文长度最大可以达到64 kb,但是当报文过大时,稳定性会大大减弱。这是因为当报文过大时会被分割,使得每个分割块(翻译可能有误差,原文是fragmentation)的长度小于MTU,然后分别发送,并在接收方重新组合(reassemble),但是如果其中一个报文丢失,那么其他已收到的报文都无法返回给程序,也就无法得到完整的数据了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号