
21年双十一大促稳定性保障记录
2022-03-03 09:18 第二个卿老师 阅读(212) 评论(0) 编辑 收藏 举报为了保证“双十一”大促期间,系统能稳定运行且保障业务的高可用,相关开发、运维、测试人员成立了一个稳定性小组。
开发和运维的主要任务是生产环境架构升级为K8S集群,毕竟测试环境使用K8S一年多了,而我主要负责业务的性能测试。
测试核心:评估系统性能、分析性能变化趋势、定位系统瓶颈风险、协助规划系统容量。
测试目的:评估系统性能是否满足新的业务需求
技术背景
生产环境架构(双十一前得从旧架构升级到新架构):
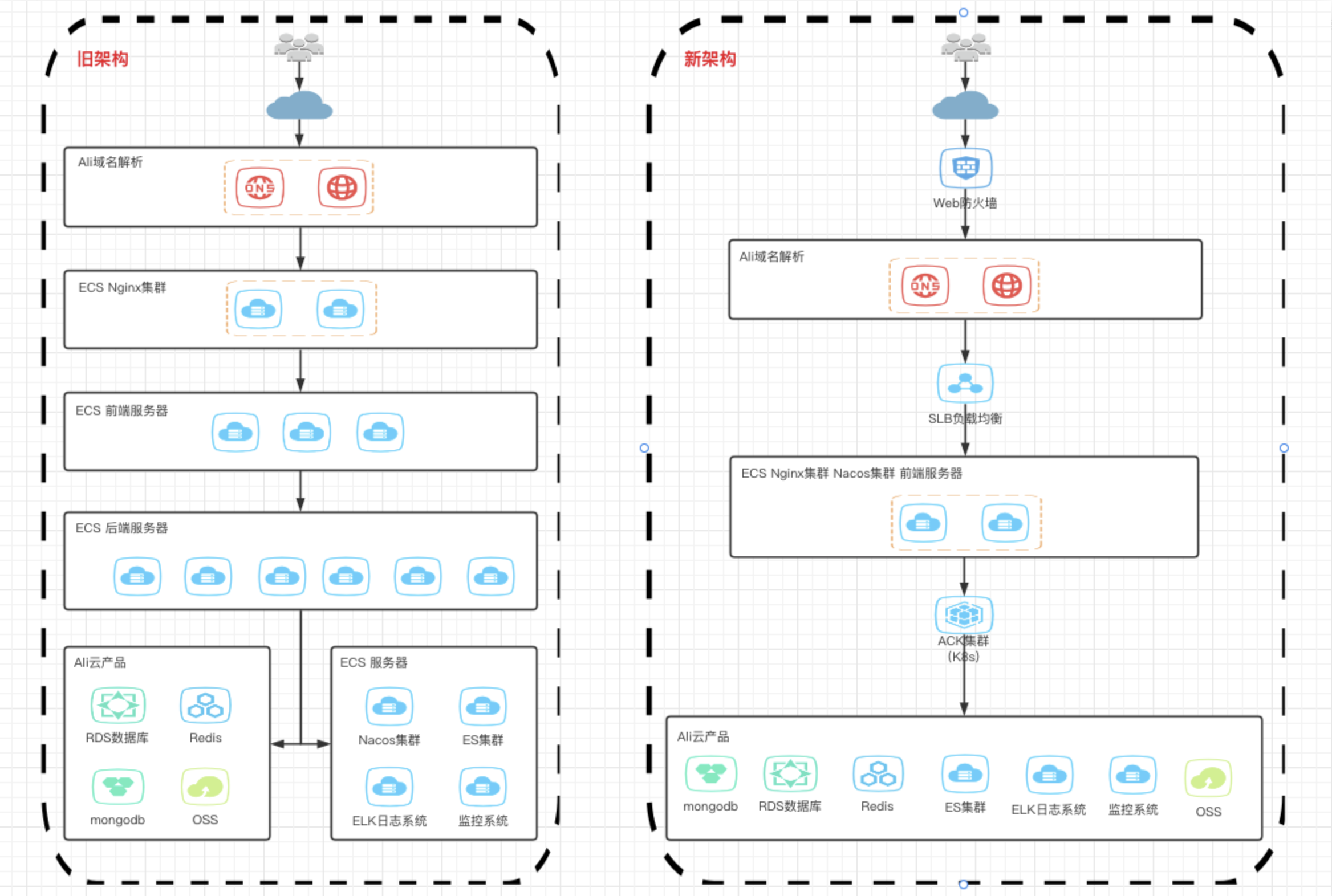
压测环境架构(k8s):
-
4核32G,2台服务器
线上压测环境(K8s):
-
单个node节点为8核32G,大概可以跑32个pod,每个pod为1C,2G
负载机配置:
-
本地机 6核12线程 3.2Ghz 16G 网卡1000Mbps(125M)
网络:
- 同一VPC内网,带宽1000M,传送速率100Mbps(12.5M)
需求分析
双十一业务(10月20日双十一开始预热,11月1日与11.11日为两个关键时间节点):
1,头条推广2周约新增50W用户,预计注册接口达到300的QPS(该场景可以理解为均匀分布,根据经验300QPS完全够用)
2,秒杀活动约10分钟1场,200个库存,预计是618活动10倍的uv,浏览500QPS,下单300QPS(典型场景,该目标为独立服务,根据情况伸缩扩容)
3,盲盒活动,预计浏览500QPS(新业务活动,该目标为独立服务,根据情况伸缩扩容)
4,商城促销预计到达3000W的GMV
5,历史记录当天秒杀UV最高值3,446人,盲盒UV最高值约2,026人
6,11月1日与11月11日凌晨会做活动,盲盒优惠券和商城售卖,预计流量最大
-
整理压测接口,先做P0接口(预计8个)
技术选型
-
Locust
-
Jmeter
由于时间较紧,选定较为熟悉的Jmeter
测试方案
压测模式
RPS模式,定量分析每个服务的性能瓶颈,方便后续容量规划
注:由于环境架构为K8S,可为单个服务分配资源(go服务默认为memory: "512Mi" cpu: "500m",java服务默认为memory: "2G" cpu: "2",超过限制pod会被重启)
整体策略参考(根据实际情况,这里更关注apiserver):
测试kubernetes集群的性能时,重点关注在不同水位、不同并发数下,长时间执行压力测试时,系统的稳定性,包括:集群整体1,系统性能表现,在较长时间范围内的变化趋势2,系统资源使用情况,在较长时间范围内的变化趋势3,各个服务组件的TPS、响应时间、错误率4,内部模块间访问次数、耗时、错误率等内部性能数据5,各个模块资源使用情况6,各个服务端组件长时间运行时,是否出现进程意外退出、重启等情况7,服务端日志是否有未知错误8,系统日志是否报错apiserver1,关注api的响应时间。数据写到etcd即可,然后根据情况关注异步操作是否真正执行完成。2,关注apiserver缓存的存储设备对性能的影响。例如,master端节点的磁盘io。3,流控对系统、系统性能的影响。4,apiserver 日志中的错误响应码。5,apiserver 重启恢复的时间。需要考虑该时间用户是否可接受,重启后请求或者资源使用是否有异常。6,关注apiserver在压力测试情况下,响应时间和资源使用情况。
时间计划:
| 时间 | 工作内容 | 备注 | |
| 2021年10月11日 | 完成P0接口脚本与环境搭建 | ||
| 2021年10月12日 | 完成一轮注册登录性能评估 | ||
| 2021年10月15日 | 完成一轮商城与秒杀的性能评估 | ||
| 2021年10月16日 | 完成第二轮所有业务的性能评估 |
测试设计
业务场景:
1,渠道推广业务
压测下载落地页的H5(优先级低)
基准压测场景一:落地页H5的访问
2,APP登录注册业务
压测APP的验证码登录场景,需要参数化注册手机号
混合压测场景:获取验证码与登录双接口,新老用户可以分两个用例
3,首页及详情浏览业务
压测APP首页、商城、商品详情页场景,需要准备首页动态数据与商品数据,盲盒详情页
基准压测场景一:APP首页,刷新与加载比率,1页80%,3页15%基准压测场景二:商城首页,刷新与加载,流量比2:1基准压测场景三:商品详情页基准压测场景四:盲盒详情页混合压测场景:APP首页,商城首页,商品详情页,流量比1:1:1
4,下单业务
商品下单场景,需要参数化下单用户,去掉商品限购
基准压测场景一:下单接口混合压测场景:商品详情浏览,商品下单,流量比5:1
5,秒杀下单业务(并发验证)
秒杀下单场景,秒杀库存为200,并发测试
并发场景:多用户抢库存
6,盲盒业务
首页:包含3个接口,首页+跑马灯+奖项列表,入参都为PB。购买流程:摇一摇接口+支付信息两个接口
基准压测场景:首页3个接口,购买两个接口混合压测场景一:盲盒首页浏览,流量比1:1:1混合压测场景二:盲盒购买,流量比1:1混合压测场景三:盲盒首页浏览与盲盒购买,流量比5:1
注:上面都是单交易场景,由于微服务架构,多交易混合影响不大,暂时不考虑
脚本设计:
jmeter脚本设计与调试就不说了,混合场景可以使用随机变量+if控制器处理,网上教程很多。
------测试中断
为什么会测试中断,多个原因:
一是没有独立的压测环境,之前的压测环境被做成了线下的k8s集群,虽然可以虚拟化一个压测环境,但配置参数和线上不一致,可信度不高,而且可能会影响功能测试环境。
二是开发和运维全心投入线上架构迁移,遇到很多新问题,每天干到凌晨,没有精力协助我这边的工作。
三是测试资源紧张,盲盒需求功能测试急需人力,而我也只是临时加入稳定性小组,压测活动需要16日结束。
综上所述,多方面考虑与评估,暂时中断了性能测试。
没有性能测试,那怎么容量规划呢?
通过会议讨论,简单粗暴的解决方案如下:
一,宁愿增加预算,运维组负责生产加机器,整体目标QPS500,节点配置N+2原则,核心服务2C+2G,数据库升级。
二,架构组负责限流及降级方案,包括客户端处理(减少接口调用,友好提示)、服务端(限流)。
三,各业务开发负责人,对自己业务模块进行代码优化、数据库慢查询优化,内存监控、本地性能验证、新增缓存。
。。。。
于是,各业务开发负责人,对自己的接口负责,如本地QPS为250的,则线上节点配置为500/2+2,并反馈给运维组。
双十一(10.20—11.11)
从15日到20日凌晨服务迁移总算完成,双十一20日预热平稳度过,盲盒需求是10月23日发布上线的,预留了一周内测活动。
然后10月25日下班前盲盒活动开始,约半分钟后服务宕机,盲盒超过20分钟无法购买,直到库存异常减少为0活动结束,属重大事故,还记得领导黑着脸不说话,大家也不敢吭声,办公室异常安静的情景。
因为大家都没想到盲盒活动因为优惠力度太大,变成了秒杀活动。
最高总QPS达到了约480的样子。。。真的不高,很尴尬。。。
马上加班处理问题,初步原因为:盲盒reward服务高负载宕机,可能代码存在问题,服务重启后也会立马挂掉,还需要进一步排查。
接着就是开发的代码优化。。。
测试执行
于是配合开发进行调优,为了节省时间,从软件配置到代码,边压测边调优。
一,压测数据构造:
新建盲盒压测活动,配置相关商品,并调整库存为1百万。
拉取数据库1万用户数据,并在Jmeter脚本中做好参数化。
期间还发现两个大数据生成超时问题:
1,商品库存新增1百万时,报错,但库存表已经插入2,盲盒新增奖项商品库存为10万时报错,但库存表中已经出库
期间遇到的问题,部分如下:
1,并发数为200的时候,报错transport: Error while dialing dial tcp 172.20.2.66:9375: connect: cannot assign requested address,原因是该节点的端口号耗尽了,需要调整pod的参数。2,服务端通过netstat查看tcp情况,发现连接数过高,修改tcp_fin_timeout参数后,QPS变化不大。3,压测超过3分钟左右,会报连接超时,原因是服务内存泄漏,超过分配内存,导致服务重启。
接着如果接口报错属于正常情况,且运行期间服务稳定,QPS也波动不大,就可以加大并发。
最后QPS不随着并发量的增加而改变(且99%RT较小),基本可以得出当前QPS为最大吞吐量。
测试结果
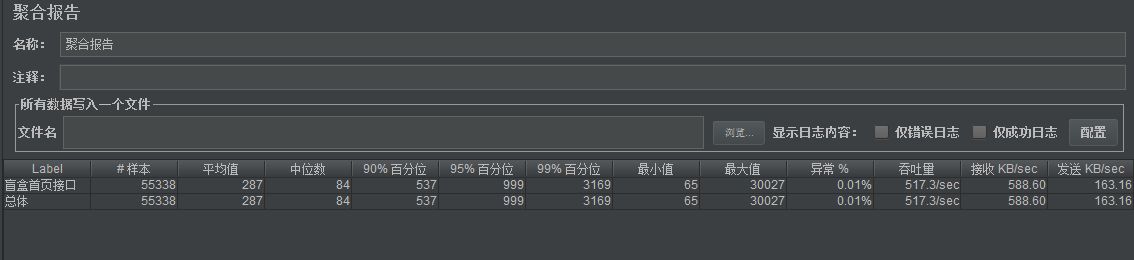
以下是摘要的部分结果:
盲盒首页

优化了远程连接主动关闭,内存由1.3G变成了750M,单节点QPS230左右

发现for循环嵌套的导致数据库的正常1千查询,某1秒超过了1w5,并优化了代码后,单节点515QPS
服务弹性验证
最后做一下服务弹性验证:
用例一,验证单节点下的服务QPS并记录
用例二,验证多节点下的服务QPS并记录
结论:对比两次用例多次运行的结果,基本满足弹性扩容,服务性能通过可以上线,于是本次压测结束

