
StanfordCoreNLP的简单使用
前提条件:电脑上安装有jdk,最好新一点吧,jdk1.8以上。
1.pip install stanfordcorenlp
2.去官网https://stanfordnlp.github.io/CoreNLP/
下载两个东西,如图:
![]()4F55EUD]XF])T3M_P59FE5.png)
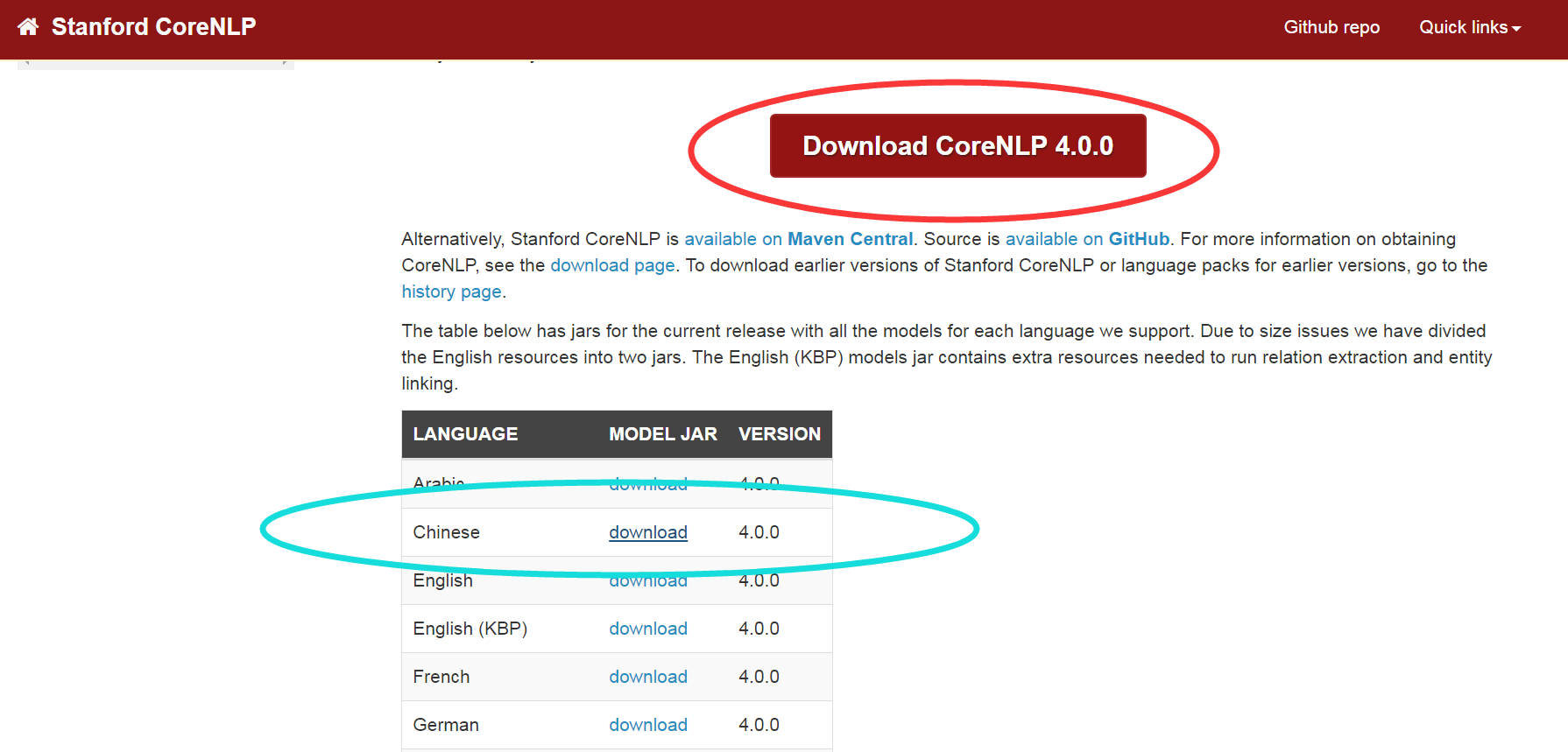
一个是最新版的CoreNLP,一个是中文包。
3.下载后解压前者,把中文包(.jar文件)放在前者解压后的文件夹。
然后注意,一定要把中文包重命名一下。因为整个的工具都是Java写的,只是用了一个Python库stanfordcorenlp来调用它。那么工具包里所有的文件命名都要按照调用的规范来。至于重命名成什么?你只要运行一下等着报错就行了。。。报错信息会提醒你该改的格式。
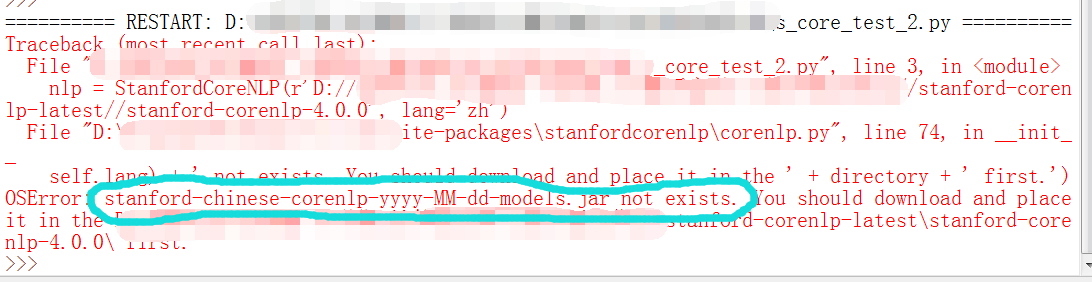
我这里中文包名本来是stanford-corenlp-4.0.0-models-chinese.jar,改成了stanford-chinese-corenlp-2020-01-01-models.jar,日期是随便输的,只要格式对了就行。
4.最后来看应用:
from stanfordcorenlp import StanfordCoreNLP
##指明安装路径和语言类型(中文) nlp = StanfordCoreNLP(r'XXXXXXXXXXXX/stanford-corenlp-latest//stanford-corenlp-4.0.0', lang='zh')
sentence = '2020吉祥文化金银币正式发行。' print(nlp.word_tokenize(sentence)) print(nlp.pos_tag(sentence)) print(nlp.ner(sentence)) print(nlp.parse(sentence)) print(nlp.dependency_parse(sentence)) nlp.close()
运行结果:
['2020', '吉祥', '文化', '金', '银币', '正式', '发行', '。'] [('2020', 'CD'), ('吉祥', 'NN'), ('文化', 'NN'), ('金', 'JJ'), ('银币', 'NN'), ('正式', 'AD'), ('发行', 'VV'), ('。', 'PU')] [('2020', 'NUMBER'), ('吉祥', 'MISC'), ('文化', 'MISC'), ('金', 'MISC'), ('银币', 'MISC'), ('正式', 'O'), ('发行', 'O'), ('。', 'O')] (ROOT (IP (NP (NP (QP (CD 2020)) (NP (NN 吉祥) (NN 文化))) (ADJP (JJ 金)) (NP (NN 银币))) (VP (ADVP (AD 正式)) (VP (VV 发行))) (PU 。))) [('ROOT', 0, 7), ('dep', 3, 1), ('compound:nn', 3, 2), ('compound:nn', 5, 3), ('amod', 5, 4), ('nsubj', 7, 5), ('advmod', 7, 6), ('punct', 7, 8)]
分词、词性标注、句法分析、依存树分析都有了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号