

正则表达式和部分命令
通配符和正则表达式
通:匹配文件名
正:主要用来匹配字符串(命令结果,文本内容)(配合相关的工具使用)
grep sed awk 基本、扩展都支持
man 7 regex 进行帮助
元字符
记得要加双引号,规范
· 单个字符
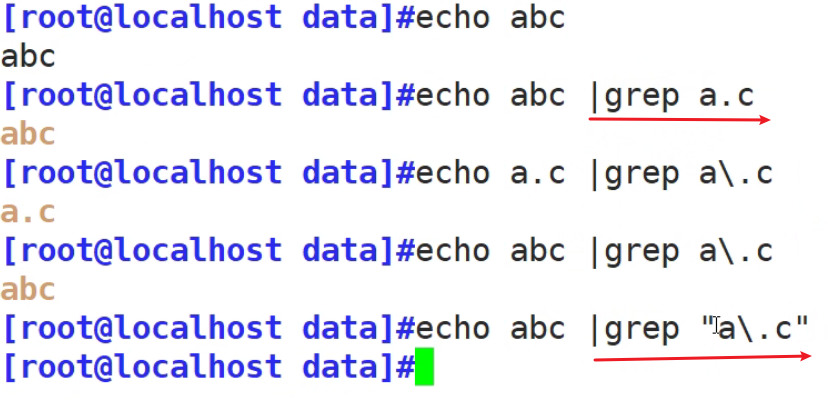
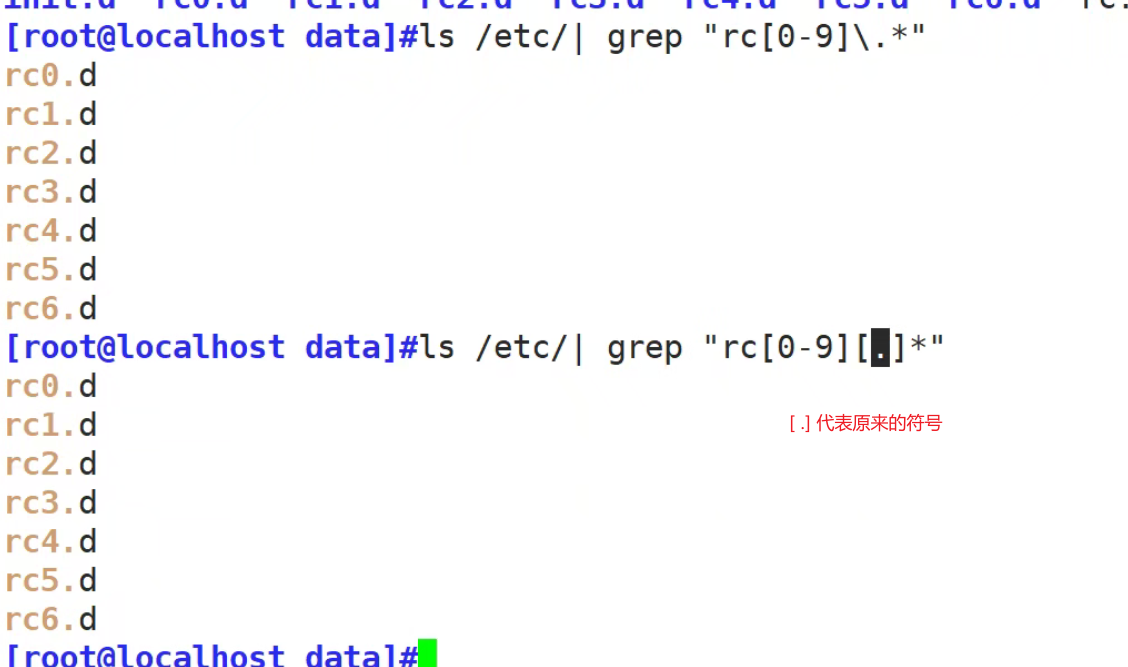
[ ] 匹配指定范围内的任意单个字符,示例:[zhou] [0-9] [] [a-zA-Z]
[^] 匹配指定范围外的任意单个字符,示例:[^zhou] [^a.z] a.z
[.] 仅仅代表 .这个符号本身
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围 广
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
\w #匹配单词构成部分,等价于[_[:alnum:]]
\W #匹配非单词构成部分,等价于[^_[:alnum:]]
\S #匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意
Unicode 正则表达式会匹配全角空格符
匹配次数:
* 匹配任意次数(包括0)
.* 任意长度的任意字符(不包括0)
\? 匹配0次或者1次
\+ 匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次,<=n
\{n,\} 匹配前面的字符至少n次
# 代表任意数字
\{#\} 匹配任意字符#次
\{#,\} 匹配前面的字符至少#次
\{,#\} 匹配前面的字符至多#次
\{n,m\} 匹配前面的字符最少n次,最多m次

匹配ip


位置锚定
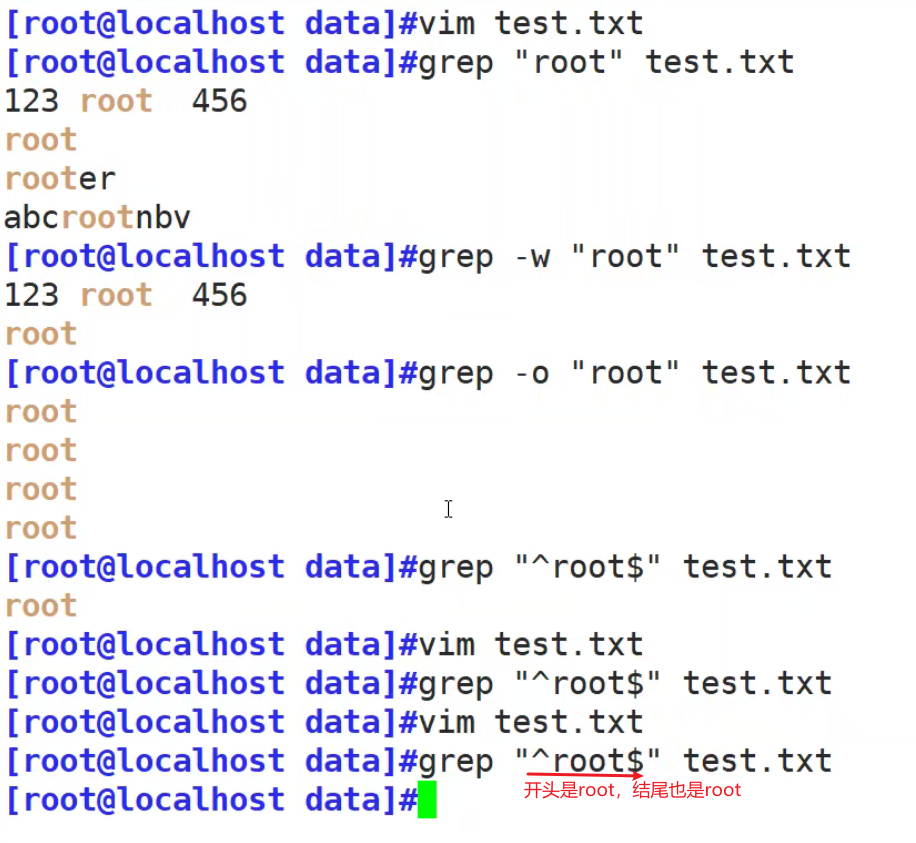
^ 代表开头 行首锚定, 用于模式的最左侧
$ 代表结尾 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行 (单独一行 只有root) pattern
^$ 空行
^[[:space:]]*$ 有空格和空行的都匹配出来
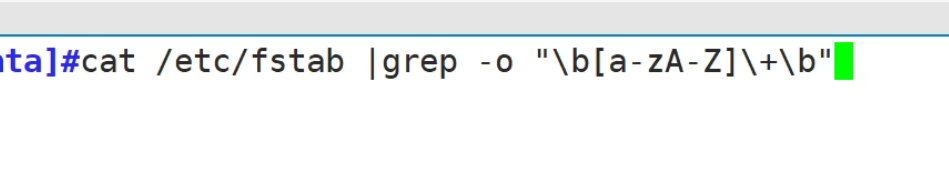
\< 或 \b 以什么什么开头 词首锚定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部)
\> 或 \b 以什么什么结尾 词尾锚定,用于单词模式的右侧
\<pattern\> 匹配整个单词
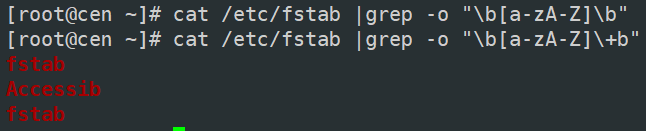
思考过滤出不是已#号开头的非空行
[root@localhost ~]#grep "^[^#]" /etc/fstab
[root@localhost ~]#grep "^[[:space:]]*$" /etc/fstab
[root@localhost ~]#echo hello-123 |grep "\<123"
hello-123
[root@localhost ~]#echo hello 123 |grep "\<123"
hello 123
匹配号码
邮箱

分组
() 括号内的算一个整体
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名
方式为: \1, \2, \3, ...
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
或者
或者
或者:\|
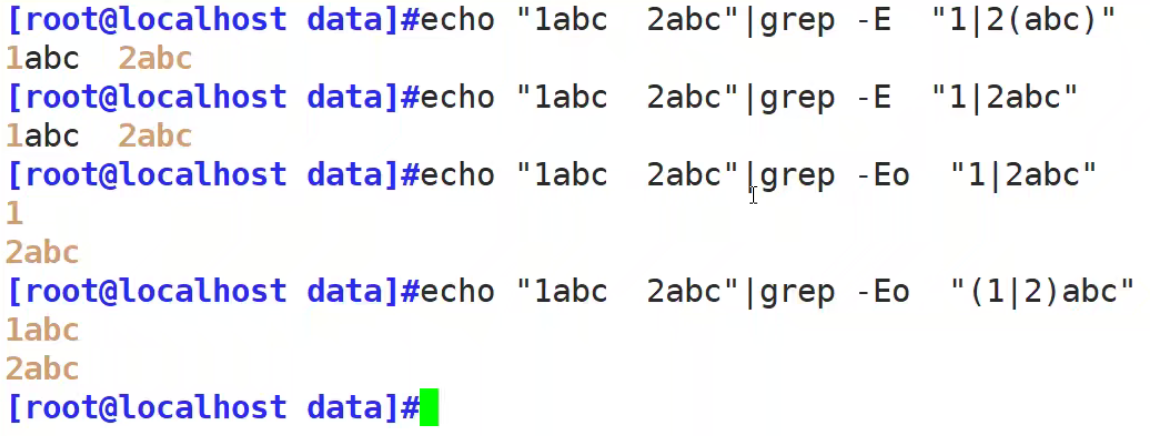
扩展正则表达式(表示字符相差不大)
egrep
或者grep -E
表示次数
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
{,n} 匹配前面的字符至多n次,<=n,n可以为0
{n,} 匹配前面的字符至少n次,<=n,n可以为0
表示分组
() 分组
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:(root)+
后向引用:\1, \2, ...
| 或者
a|b #a或b
C|cat #C或cat
(C|c)at #Cat或cat
sed
行编辑器
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。如果使用vi命令打开几十M上百M的文件,明显会出现有卡顿的现象,这是因为vi命令打开文件是一次性将文件加载到内存,然后再打开。Sed就避免了这种情况,一行一行的处理,打开速度非常快,执行速度也很快
用法:
sed [option]... 'script;script;...' [input file...]
选项 自身脚本语法 支持标准输入管道
常用选项:
-n 不输出模式空间内容到屏幕,即不自动打印
-e 多点编辑
-f FILE 从指定文件中读取编辑脚本
-r, -E 使用扩展正则表达式
-i.bak 备份文件并原处编辑
-s 将多个文件视为独立文件,而不是单个连续的长文件流
脚本格式:
'地址+命令'组成
- 不给地址:对全文进行处理(比如行号)
- 单地址:
#:指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行
3. 地址范围:
#,# #从#行到第#行,3,6 从第3行到第6行
#,+# #从#行到+#行,3,+4 表示从3行到第7行
/pat1/,/pat2/ 第一个正则表达式和第二个正则表达式之间的行
#,/pat/ 从#号行为开始找到 pat为止
/pat/,# 找到#号个pat为止
4. 步进:~
1~2 奇数行
2~2 偶数行
命令
p 打印当前模式空间内容,追加到默认输出之后
Ip 忽略大小写输出
d 删除模式空间匹配的行,并立即启用下一轮循环
a []text 在指定行后面追加文本,支持使用\n实现多行追加
i []text 在行前面插入文本
c []text 替换行为单行或多行文本
w file 保存模式匹配的行至指定文件
r file 读取指定文件的文本至模式空间中匹配到的行后
= 为模式空间中的行打印行号
! 模式空间中匹配行取反处理
q 结束或退出sed
[root@localhost ~]#seq 10 | sed 'p'
#带有自动打印功能,p又再打印一遍
搜索替代
s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
替换修饰符:
g 行内全局替换
p 显示替换成功的行
w /PATH/FILE 将替换成功的行保存至文件中
I,i 忽略大小写
面试题:提取版本号
[root@localhost /]#cat 1.txt | grep -e "[0-9]+."
ant-1.9.7.jar
ant-launcher-1.9.7.jar
antlr-2.7.7.jar
antlr-runtime-3.4.jar
aopalliance-1.0.jar
archaius-core-0.7.6.jar
asm-5.0.4.jar
aspectjweaver-1.9.5.jar
bcpkix-jdk15on-1.64.jar
bcprov-jdk15-1.46.jar
bcprov-jdk15on-1.64.jar
checker-compat-qual-2.5.5.jar
[root@localhost /]#cat 1.txt |sed -r 's/.-(.).jar/\1/'
1.9.7
1.9.7
2.7.7
3.4
1.0
0.7.6
5.0.4
1.9.5
1.64
1.46
1.64
2.5.5
AWK
awk 是一个功能强大的编辑工具,逐行读取输入文本,默认以空格或tab键作为分隔符作为分隔,并按模式或者条件执行编辑命令
awk 比较倾向于将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。
格式:
awk [选项] ‘模式条件{操作}’ 文件1 文件2....
awk -f|-v 脚本文件 文件1 文件2.....
-F指定分隔符 不写默认空格
OFS 指定输出分隔符
OFS="@@" 指定输出分隔符为@@
ifconfig ens33 |grep netmask |awk '{print $2}'|awk -F. 'OFS="."{print $1,$2,$3}'
指定间隔符为. (下面的列子也有其他的指定间隔符方法)
cat /etc/passwd|awk -F: '{print $1":"$3}'
/1/2/代表正则表达式
[root@localhost ky15]#df|awk '{print $5}'
#分区利用率
已用%
8%
0%
0%
1%
0%
4%
0%
1%
[root@localhost ky15]#cat /etc/passwd|awk -F: '{print $1,$3}'
#指定冒号作为分隔符,打印第一列和第三列
[root@localhost ky15]#cat /etc/passwd|awk -F: '{print $1":"$3}'
#用冒号分隔开 (原本是第一和第三列无间隔显示,现在有间隔了)
df|awk -F"( +|%)" '{print $5}'
[root@localhost ky15]#df |awk -F"[[:space:]]+|%" '{print $5}'
[root@localhost ky15]#df |awk -F"[ %]+" '{print $5}'
[root@localhost ~]#awk -F: '{print $0}' /etc/passwd
#$0代表全部元素
[root@localhost ~]#awk -F: '{print $1}' /etc/passwd
#代表第一列
[root@localhost ~]#awk -F: '{print $1,$3}' /etc/passwd
#代表第一第三列
[root@localhost ky15]#awk '/^root/{print}' passwd
#已root为开头的行
[root@localhost ky15]#grep -c "/bin/bash$" passwd
#统计当前已/bin/bash结尾的行
BEGIN{}模式表示,在处理指定的文本前,需要先执行BEGIN模式中的指定动作; awk再处理指定的文本,之后再执行END模式中的指定动作,END{}语句中,一般会放入打印结果等语句。
[root@localhost ky15]#awk 'BEGIN {x=0};//bin/bash$/;{x++};END{print x}' passwd
先定义变量
[root@localhost ky15]#awk 'BEGIN {x=0};//bin/bash$/ {x++;print x,$0};END{print x}' passwd
tr
基本功能转换
格式
tr [选项]... SET1 [SET2]
SET 是一组字符串,一般都可按照字面含义理解
-d 删除
-s 压缩
-c 反向取值 用字符串1中字符集的补集替换此字符集,要求字符集为ASCII。
[root@localhost ~]#tr 123 abc
#只要出现123 就转换成abc
1g2j3k
agbjck
[root@localhost ~]#tr 12345678 abc
#最后一个一直用
123456789
abcccc[root@localhost ~]#tr -d abc
删除
2a34bc
234
[root@localhost ~]#tr -s " "
1 2 3 4
1 2 3 4
[root@localhost ~]#tr -s "a"
aaaa
a
#管道符号的好处
#求和
[root@localhost opt]#seq -s+ 100
#中间加上加号
1+2+3+4+5+6+7+8+9+10+11+12+13+14+15+16+17+18+19+20+21+22+23+24+25+26+27+28+29+30+31+32+33+34+35+36+37+38+39+40+41+42+43+44+45+46+47+48+49+50+51+52+53+54+55+56+57+58+59+60+61+62+63+64+65+66+67+68+69+70+71+72+73+74+75+76+77+78+79+80+81+82+83+84+85+86+87+88+89+90+91+92+93+94+95+96+97+98+99+100
[root@localhost ~]#seq -s+ 100 >log.txt
[root@localhost ~]#bc < log.txt
#将log.txt中的信息交给bc 计算
#bc就是计算命令
5050
[root@localhost ~]#seq -s+ 100|bc
5050
#写脚本
#面试题生成随机密码
[root@localhost ~]cat /dev/urandom |tr -dc '[:alnum:]' |head -c12
[root@localhost ~]#cat 1.txt
aaaaa 11111
bbbbb 22222
[root@localhost ~]#cat 1.txt |tr -c "[a-z]" " "
#用 空格替换除了小写字母之外的所有字符
aaaaa bbbbb
[root@localhost ~]#cat 1.txt |tr -sc "[a-z]" " "
#加s压缩
aaaaa bbbbbcc9
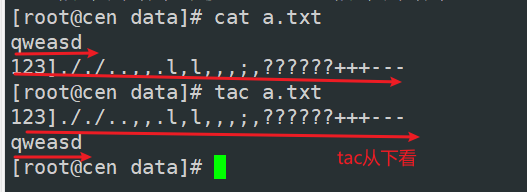
tac
tac和cat差不多,但是倒叙
rev

cut
cut 命令可以提取文本文件数据的指定列
格式
cut [选项]... [文件]...
常用选项
-d DELIMITER: 指明分隔符,默认tab
-f 想要获取的字段
#: #: 第#个字段,例如 3
#,#[,#]:离散的多个字段,例如 1,3,6
#-#:连续的多个字段, 例如 1-6
混合使用:1-3,7
-c 取字符
[root@localhost ~]#cut -d: -f1,3 /etc/passwd
##已冒号作为分隔的条件,取文件的第一列和第三列
root:0
bin:1
daemon:2
adm:3
lp:4
sync:5
shutdown:6
halt:7
mail:8
operator:11
[root@localhost ~]#df |tail -n +2|tr -s " " |cut -d " " -f5|tr -d %
# df |tail -n +2 不显示第一行字段
# tr -s " " 将多个空格压缩成一个
# cut -d " " -f5 已空格为分隔符,取第五列
# tr -d % 删除百分号
[root@localhost ~]#df|tail -n +2 |tr -s " " % |cut -d % -f5
# df |tail -n +2 不显示第一行字段
# tr -s " " 将多个空格压缩成一个后 将空格替换成%
# cut -d % -f5 已%为分隔符 取第5列
[root@localhost ~]#df |tail -n +2 |cut -c54
#使用字符取字段,-c 取当前字符的字段
#在xshell的左下角,复制会有字符个数
sort
排序
sort [options] file(s)
把整理过的文本显示在屏幕上,不改变原始文件
选项:
-r 执行反方向(由上至下)整理
-R 随机排序
-n 执行按数字大小整理
-h 人类可读排序,如: 2K 1G
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique),合并重复项,即去重
-t 指定分隔符
-k 指定列
[root@localhost ~]#sort /etc/passwd
abrt:x:173:173::/etc/abrt:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
avahi:x:70:70:Avahi mDNS/DNS-SD Stack:/var/run/avahi-daemon:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
[root@localhost ~]#sort -t: -k3 /etc/passwd
#已冒号为分隔符,只排序第三列,不是已数字是已字符比较
[root@localhost ~]#sort -t: -k3 -n /etc/passwd
#正序
[root@localhost ~]#sort -t: -k3 -nr /etc/passwd
#到序
[root@localhost ~]#df |tail -n +2 |tr -s " " % |cut -d % -f5|sort -nr |head -1
8
unqi 去重
uniq [OPTION]... [FILE]...
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
uniq常和sort 命令一起配合使用
[root@localhost ~]#uniq f3.txt
#只会将连续的行去重
1
2
3
4
5
6
3
6
[root@localhost ~]#uniq -c f3.txt
#显示出现次数
1 1
1 2
2 3
1 4
1 5
2 6
1 3
1 6
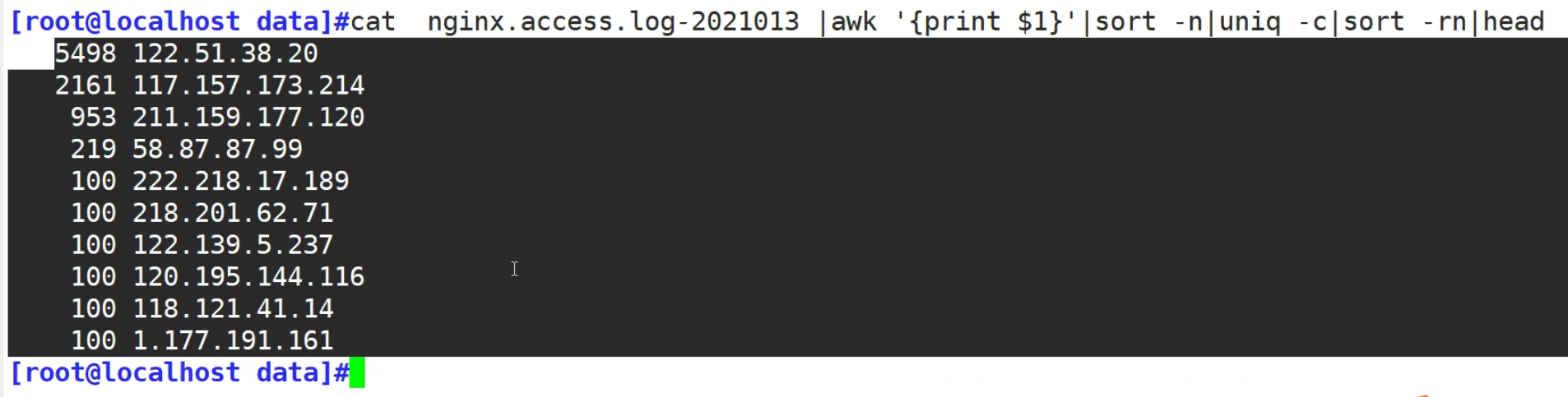
###面试题,查看访问日志,找出访问前10名的用户,
[root@localhost ~]#cat log|cut -d" " -f1
#先取地址
[root@localhost ~]#cat log|cut -d" " -f1|sort
#再排序一样的ip地址在一起
[root@localhost ~]#cat log|cut -d" " -f1|sort|uniq -c
#去重
[root@localhost ~]# cat log|cut -d" " -f1|sort|uniq -c|sort -nr |head
#再数字排序,取前10 行
5498 122.51.38.20
2161 117.157.173.214
953 211.159.177.120
219 58.87.87.99
100 222.218.17.189
100 218.201.62.71
100 122.139.5.237
100 120.195.144.116
100 118.121.41.14
100 1.177.191.161
awk sed
#面试题 取两个文件一样或不一样的字段
[root@localhost ~]#cat f1.txt f2.txt
a
b
c
1
a
2
b
3
c
[root@localhost ~]#cat f1.txt f2.txt |uniq -d
#直接使用 看不出来
[root@localhost ~]#cat f1.txt f2.txt |sort |uniq -u
#一样的
1
2
3
[root@localhost ~]#cat f1.txt f2.txt |sort |uniq -d
#不一样的
a
b
c
参数替换xargs
由于很多命令不支持管道|来传递参数,xargs用于产生某个命令的参数,xargs 可以读入 stdin 的数
据,并且以空格符或回车符将 stdin 的数据分隔成为参数
另外,许多命令不能接受过多参数,命令执行可能会失败,xargs 可以解决
单独使用 xargs 是将键盘上的输入输出在屏幕上
heiwu传给|。|在通过xargs给useradd
echo "a b"|xargs -n1 useradd n1表示1次行传1个未知数
#创建10个用户
[root@localhost opt]# echo user{1..10}| xargs -n1 useradd
[root@localhost opt]#for i in {1..10};do useradd ky$i; done
#删除
[root@localhost opt]# echo ky{1..10}| xargs -n1 userdel -r
[root@localhost opt]#for i in {1..10};do userdel -r ky$i; done


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)