
基于hash算法的三个集合HashTable,HashSet和HashMap详解
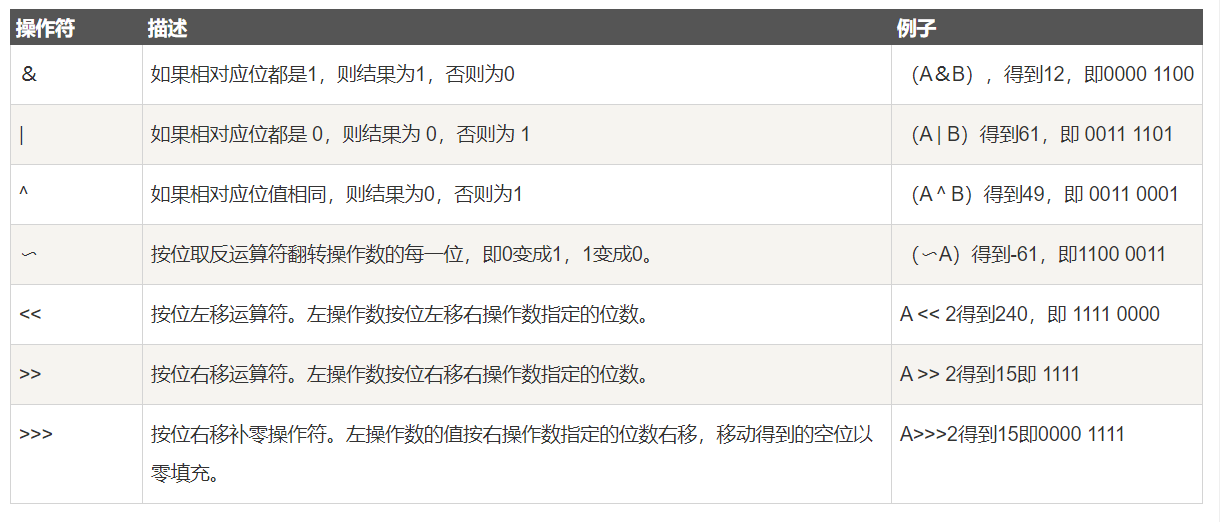
位运算符
下表列出了位运算符的基本运算,假设整数变量 A 的值为 60 和变量 B 的值为 13:
public class Test { public static void main(String[] args) { int a = 60; /* 60 = 0011 1100 */ int b = 13; /* 13 = 0000 1101 */ int c = 0; c = a & b; /* 12 = 0000 1100 */ System.out.println("a & b = " + c ); c = a | b; /* 61 = 0011 1101 */ System.out.println("a | b = " + c ); c = a ^ b; /* 49 = 0011 0001 */ System.out.println("a ^ b = " + c ); c = ~a; /*-61 = 1100 0011 */ System.out.println("~a = " + c ); c = a << 2; /* 240 = 1111 0000 */ System.out.println("a << 2 = " + c ); c = a >> 2; /* 15 = 1111 */ System.out.println("a >> 2 = " + c ); c = a >>> 2; /* 15 = 0000 1111 */ System.out.println("a >>> 2 = " + c ); } }
Hashtable和HashMap
区别一:继承的父类不同
Hashtable 继承自 Dictionary 类,而 HashMap 继承自AbstractMap 类。但二者都实现了 Map 接口。
区别二:线程安全性不同
Hashtable 中的方法是 Synchronize 的,而 HashMap 中的方法在缺省情况下是非 Synchronize 的。
区别三:是否提供 contains 方法
HashMap 把 Hashtable 的 contains 方法去掉了,改成containsValue 和 containsKey,因为 contains 方法容易让人引起误解。
Hashtable 则保留了 contains,containsValue 和 containsKey三个方法,其中 contains 和 containsValue 功能相同。
区别四:**key 和 value 是否允许 null 值 (面试比较喜欢问)
其中 key 和 value 都是对象,并且不能包含重复 key,但可以包含重复的 value。
Hashtable 中,key 和 value 都不允许出现 null 值。
HashMap 中,null 可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为 null。当 get()方法返回 null值时,可能是 HashMap 中没有该键,也可能使该键所对应的值为 null。因此,在 HashMap 中不能由 get()方法来判断 HashMap 中是否存在某个键, 而应该用 containsKey()方法来判断。
区别五:哈希值的计算方法不同
Hashtable 直接使用的是对象的 hashCode,而 HashMap 则是在对象的 hashCode 的基础上还进行了一些变化。
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
区别六:内部实现使用的数组初始化和扩容方式不同
内存初始大小不同,HashTable 初始大小是 11,而 HashMap 初始大小是 16
HashMap和HashSet区别
//HashSet底层用来存储元素的结构,实际上使用HashMap来存储 private transient HashMap<E,Object> map; //HashMap中的value值,HashSet只关注key值,所以所有的value值都为Object对象 private static final Object PRESENT = new Object(); //HashSet的无参构造,直接创建了一个HashMap对象 public HashSet() { map = new HashMap<>(); } //指定初始化容量和负载因子 public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); } //给定初始化容量 public HashSet(int initialCapacity) { map = new HashMap<>(initialCapacity); } public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); }
可以看到 HashSet的构造方法底层都是调用 HashMap的构造方法, 所以HashSet底层实际上是使用 HashMap 来作为存储结构.
当使用无参构造创建 HashSet对象时, 其实调用了 HashMap的无参构造创建了一个 HashMap对象, 所以 HashSet 的初始化容量也为16, 负载因子也为 0.75.
再来看看 HashSet 的 add() 方法的实现:
public boolean add(E e) { return map.put(e, PRESENT)==null; }
可以看到 HashSet 的 add() 方法底层实际也是调用了 HashMap 的 put() 方法, 这里的key为我们传入的将要添加到 set集合中的元素, 而value值则为 PERSENT,其实就是上面分析的 HashSet类中的一个静态字段, 默认为 Object对象.
HashSet并不关注value元素, 只使用 HashMap来存储 key元素, 这就使得 HashSet判断元素相等的条件与 HashMap中 key相等的条件其实是一样的, 两个元素的 hashCode值相同且通过equals()方法比较返回 true.
所以HashSet应该重写 equals()和hashCode()方法, 两个元素的 HashCode相同, 保证通过equals() 方法比较返回 true.
总结一下HashSet和HashMap的区别:
(1)HashSet实现了Set接口, 仅存储对象; HashMap实现了 Map接口, 存储的是键值对.
(2)HashSet底层其实是用HashMap实现存储的, HashSet封装了一系列HashMap的方法. 依靠HashMap来存储元素值,(利用hashMap的key键进行存储), 而value值默认为Object对象. 所以HashSet也不允许出现重复值, 判断标准和HashMap判断标准相同, 两个元素的hashCode相等并且通过equals()方法返回true.
