
Sqoop切分数据及自定义boundary-query
1、指定切分的字段
Sqoop通过--split-by指定切分的字段,--m设置mapper的数量。通过这两个参数分解生成m个where子句,进行分段查询。因此sqoop的split可以理解为where子句的切分。
sqoop import \ --connect jdbc:mysql://192.168.1.100:3306/test \ --username root \ --password zxasqw12/* \ --query 'SELECT * FROM directory_excel_md5_mac1 WHERE $CONDITIONS' \ --delete-target-dir \ --target-dir /user/sqoop2/directory_excel_md5_mac1 \ --null-string '\\N' \ --null-non-string '\\N' \ --fields-terminated-by '\t' \ -m 7 \ --split-by 'id'
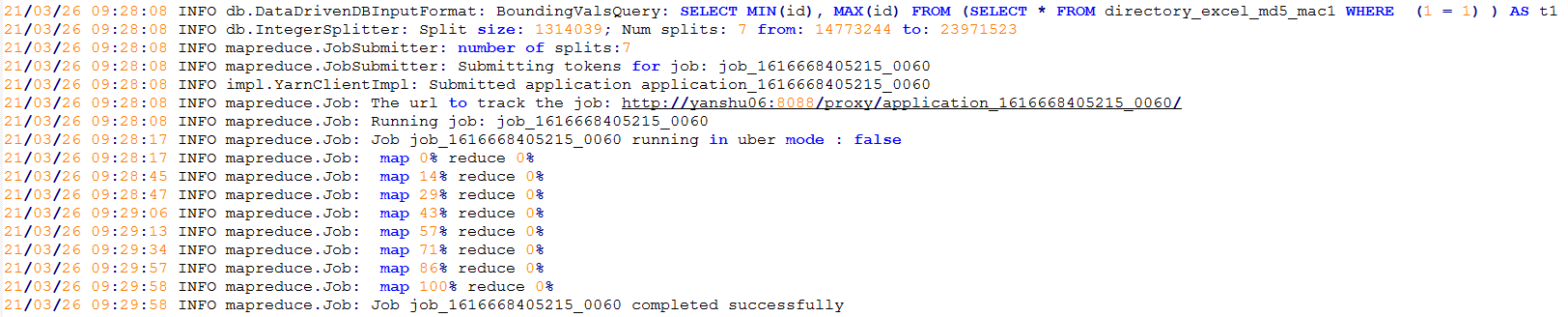
可以看到
sqoop会根据切分字段的MIN()和MAX()来切分
具体如下:
第一步,获取切分字段的MIN()和MAX()
为了根据mapper的个数切分table,sqoop首先会执行一个sql,用于获取table中该字段的最小值和最大值,源码片段为org.apache.sqoop.mapreduce.DataDrivenImportJob 224行,大体为:
private String buildBoundaryQuery(String col, String query) { .... return "SELECT MIN(" + qualifiedName + "), MAX(" + qualifiedName + ") " + "FROM (" + query + ") AS " + alias; }
获取到最大值和最小值,就可以根据不同的字段类型进行切分。
第二步,根据MIN和MAX不同的类型采用不同的切分方式
支持有Date,Text,Float,Integer,Boolean,NText,BigDecimal等等。
数字都是一个套路,就是
步长=(最大值-最小值)/mapper个数
,生成的区间为
[最小值,最小值+步长)
[最小值+2*步长,最小值+3*步长)
...
[最大值-步长,最大值]
可以参考下面的代码片段org.apache.sqoop.mapreduce.db.FloatSplitter 43行:
List<InputSplit> splits = new ArrayList<InputSplit>(); ... int numSplits = ConfigurationHelper.getConfNumMaps(conf); double splitSize = (maxVal - minVal) / (double) numSplits; ... double curLower = minVal; double curUpper = curLower + splitSize; while (curUpper < maxVal) { splits.add(new DataDrivenDBInputFormat.DataDrivenDBInputSplit( lowClausePrefix + Double.toString(curLower), highClausePrefix + Double.toString(curUpper))); curLower = curUpper; curUpper += splitSize; }
这样最后每个mapper会执行自己的sql语句,比如第一个mapper执行:
select * from t where splitcol >= min and splitcol < min+splitsize
第二个mapper又会执行
select * from t where splitcol >= min+splitsize and splitcol < min+2*splitsize
2、自定义切分键和boundary-query
sqoop import \ --username reWork \ --password reWork \ --connect jdbc:oracle:thin:@"(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=192.168.0.67)(PORT=1521))(ADDRESS=(PROTOCOL=TCP)(HOST=192.168.0.68)(PORT=1521))(LOAD_BALANCE = yes)(FAILOVER = on))(CONNECT_DATA=(SERVICE_NAME=FKBIGDAT)(SRVR=DEDICATED)))" \ --query " ...... select GATHER_TIME,ID,PAP_R,PRP_R,PAP_R1,PAP_R2,PAP_R3,PAP_R4,DATA_DATE,METER_ID from reWork.loss_yc_mrcjdldjsj_consgzb partition(P_20160829) union all select GATHER_TIME,ID,PAP_R,PRP_R,PAP_R1,PAP_R2,PAP_R3,PAP_R4,DATA_DATE,METER_ID from reWork.loss_yc_mrcjdldjsj_consgzb partition(P_20160830) where \$CONDITIONS" \ --target-dir /inceptor1/user/hive/warehouse/rework.db/hive/loss_yc_mrcjdldjsj_consgzb_txt3/pdata_date=p_201608 \ --null-string '\\N' \ --null-non-string '\\N' \ --fields-terminated-by "\001" \ --map-column-java GATHER_TIME=java.sql.Timestamp,DATA_DATE=java.sql.Date \ --map-column-hive GATHER_TIME=string,DATA_DATE=string \ --hive-drop-import-delims \ -m 7 \ --split-by "MOD(ORA_HASH(concat(METER_ID, Data_date)),7)" \ --boundary-query "select 0,7 from dual"
oracle中的hash分区就是利用的ora_hash函数
partition by hash(object_id) 等价于 ora_hash(object_id,4294967295)
ora_hash(列,hash桶) hash桶默认是4294967295 可以设置0到4294967295
ora_hash(object_id,4) 会把object_id的值进行hash运算,然后放到 0,1,2,3,4 这些桶里面,也就是说 ora_hash(object_id,4) 只会产生 0 1 2 3 4
By default sqoop will use query select min(<split-by>), max(<split-by>) from <table name> to find out boundaries for creating splits. In some cases this query is not the most optimal so you can specify any arbitrary query returning two numeric columns using --boundary-query argument.
