
HanLP 下载和配置
方式一、Maven
为了方便用户,特提供内置了数据包的Portable版,只需在pom.xml加入:
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.8</version>
</dependency>
零配置,即可使用基本功能(除由字构词、依存句法分析外的全部功能)。如果用户有自定义的需求,可以参考方式二,使用hanlp.properties进行配置(Portable版同样支持hanlp.properties)。

方式二、下载jar、data、hanlp.properties
HanLP将数据与程序分离,给予用户自定义的自由。
1、下载:data.zip
下载后解压到任意目录,接下来通过配置文件告诉HanLP数据包的位置。
HanLP中的数据分为词典和模型,其中词典是词法分析必需的,模型是句法分析必需的。
data
│
├─dictionary
└─model
用户可以自行增删替换,如果不需要句法分析等功能的话,随时可以删除model文件夹。
- 模型跟词典没有绝对的区别,隐马模型被做成人人都可以编辑的词典形式,不代表它不是模型。
- GitHub代码库中已经包含了data.zip中的词典,直接编译运行自动缓存即可;模型则需要额外下载。
2、下载jar和配置文件:hanlp-release.zip
配置文件的作用是告诉HanLP数据包的位置,只需修改第一行
root=D:/JavaProjects/HanLP/
为data的父目录即可,比如data目录是/Users/hankcs/Documents/data,那么root=/Users/hankcs/Documents/ 。
最后将hanlp.properties放入classpath即可,对于多数项目,都可以放到src或resources目录下,编译时IDE会自动将其复制到classpath中。除了配置文件外,还可以使用环境变量HANLP_ROOT来设置root。安卓项目请参考demo。
如果放置不当,HanLP会提示当前环境下的合适路径,并且尝试从项目根目录读取数据集。
附:本地jar包加入maven仓库并添加词库
起因:用maven方式不管配不配置hanlp.properties进行标准切词发现有些词语都切不出来,如“毛呢”会被分开,如下图

因项目使用的是maven方式来统一管理jar包,故采用本地jar包加入maven仓库并添加词库的方式来做。
1、按照方式二下载data以及jar包和配置文件

- hanlp-1.7.8-sources.jar: 这个包可以不要
2、将下载的jar包导入maven仓库
install:install-file -Dfile=<Jar包的地址>
-DgroupId=<Jar包的GroupId>
-DartifactId=<Jar包的引用名称>
-Dversion=<Jar包的版本>
-Dpackaging=<Jar的打包方式>
install:install-file -Dfile=D:\hanlp-1.7.8.jar -DgroupId=com.hankcs -DartifactId=hanlp -Dversion=hanlp-1.7.8 -Dpackaging=jar

成功后会在本地maven仓库看到加入的jar包
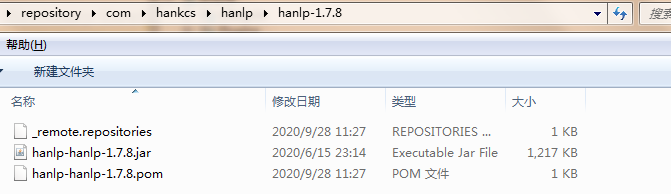
3、pom.xml中添加依赖
<!--自定义本地jar包使用python词典--> <dependency> <groupId>com.hankcs</groupId> <artifactId>hanlp</artifactId> <version>hanlp-1.7.8</version> </dependency>
4、hanlp.properties配置data路径
/home/jar/Dict为linux上的路径,因为jar包是要上传到集群的

5、切词测试
将项目打成jar包,在hive中创建临时函数,测试


