MapReduce统计每个用户的使用总流量
1、原始数据

2、使用java程序
1)新建项目
2)导包
hadoop-2.7.3\share\hadoop\mapreduce
+hsfs的那些包
+common
3、写项目
1)实体类
注:属性直接定义为String和 Long定义更方便
package com.zy.flow; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; public class Flow implements Writable{//Writable可序列化的(序列化:把对象变成二进制流 反序列化:把二进制流变成对象)
//包含 电话 上行流量 下行流量 总流量 private Text phone; private LongWritable upflow;//上行 private LongWritable downflow;//下行 private LongWritable sumflow;//总流量 //这个对象以后要在集群中传输,所以要可序列化 //序列化反序列化顺序要一致 @Override//反序列化时会调用该方法 public void readFields(DataInput in) throws IOException { phone=new Text(in.readUTF()); upflow=new LongWritable(in.readLong()); downflow=new LongWritable(in.readLong()); sumflow=new LongWritable(in.readLong()); } @Override//序列化时会调用该方法 public void write(DataOutput out) throws IOException { out.writeUTF(phone.toString()); out.writeLong(upflow.get()); out.writeLong(downflow.get()); out.writeLong(sumflow.get()); } public Text getPhone() { return phone; } public void setPhone(Text phone) { this.phone = phone; } public LongWritable getUpflow() { return upflow; } public void setUpflow(LongWritable upflow) { this.upflow = upflow; } public LongWritable getDownflow() { return downflow; } public void setDownflow(LongWritable downflow) { this.downflow = downflow; } public LongWritable getSumflow() { return sumflow; } public void setSumflow(LongWritable sumflow) { this.sumflow = sumflow; } public Flow() { } public Flow(Text phone, LongWritable upflow, LongWritable downflow, LongWritable sumflow) { super(); this.phone = phone; this.upflow = upflow; this.downflow = downflow; this.sumflow = sumflow; } public Flow(LongWritable upflow, LongWritable downflow, LongWritable sumflow) { super(); this.upflow = upflow; this.downflow = downflow; this.sumflow = sumflow; } @Override//toString最后就是reduce中输出值的样式 public String toString() {
//输出样式 return upflow+"\t"+downflow+"\t"+sumflow; } }
2)FlowMap类
package com.zy.flow; import java.io.IOException; import javax.security.auth.callback.LanguageCallback; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class FlowMap extends Mapper<LongWritable, Text, Text, Flow>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Flow>.Context context) throws IOException, InterruptedException { //输入的值 value //切分value 寻找有价值的列 String[] split = value.toString().split("\t"); int length=split.length; //取哪几列split[1] split[length-3] split[length-2] String phone=split[1]; Long upflow=Long.parseLong(split[length-3]); Long downflow=Long.parseLong(split[length-2]); Long sumflow=upflow+downflow; //输出 context.write(new Text(phone), new Flow(new Text(phone), new LongWritable(upflow), new LongWritable(downflow),new LongWritable(sumflow))); //对象里虽然用不到phone但是要给它赋值,不然序列化时会报空指针异常 } }
3)Part(分区)类
package com.zy.flow; import java.util.HashMap; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner;
// map的输出是suffer的输入 public class Part extends Partitioner<Text, Flow> {//分区 //逻辑自己写 HashMap<String,Integer> map = new HashMap(); public void setMap(){ map.put("135",0); map.put("136", 1); map.put("137",2); map.put("138", 3); map.put("139",4); }
// 生成的文件 part-00000 part的编号的结尾就是这个int类型的返回值; @Override public int getPartition(Text key, Flow value, int arg2) { setMap(); //从输入的数据中获得电话的前三位跟map对比。决定分到哪个区中 String substring = key.toString().substring(0, 3);//例如截取135 return map.get(substring)==null?5:map.get(substring);//根据键取值 键135 取出0 //其他号码分到(编号为5)第6个区中 } //在这个逻辑下partition分了6个区,所以以后要指定6个reducetask }
4)FlowReduce类
package com.zy.flow; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FlowReduce extends Reducer<Text, Flow, Text, Flow>{ @Override protected void reduce(Text key, Iterable<Flow> value, Reducer<Text, Flow, Text, Flow>.Context context) throws IOException, InterruptedException { //累加 long allup=0; long alldown=0; for (Flow flow : value) { allup+=Long.parseLong(flow.getUpflow().toString());//同一个电话的上行流量累加 alldown+=Long.parseLong(flow.getDownflow().toString());//同一个电话的下行流量累加 } long allsum=allup+alldown; context.write(key, new Flow(new Text(key), new LongWritable(allup), new LongWritable(alldown), new LongWritable(allsum))); } }
5)FlowApp类
package com.zy.flow; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowApp { public static void main(String[] args) throws Exception { //创建配置对象 Configuration configuration = new Configuration(); //得到job实例 Job job = Job.getInstance(configuration); //指定job运行类 job.setJarByClass(FlowApp.class); //指定job中的mapper job.setMapperClass(FlowMap.class); //指定mapper中的输出键和值类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Flow.class); //指定job中的reducer job.setReducerClass(FlowReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Flow.class); //----- //指定Partitioner使用的类 job.setPartitionerClass(Part.class); //指定ReduceTask数量 job.setNumReduceTasks(6); //----- //指定输入文件 FileInputFormat.setInputPaths(job, new Path(args[0]));//运行时填入参数 //指定输出文件 FileOutputFormat.setOutputPath(job, new Path(args[1])); //提交作业 job.waitForCompletion(true); } }
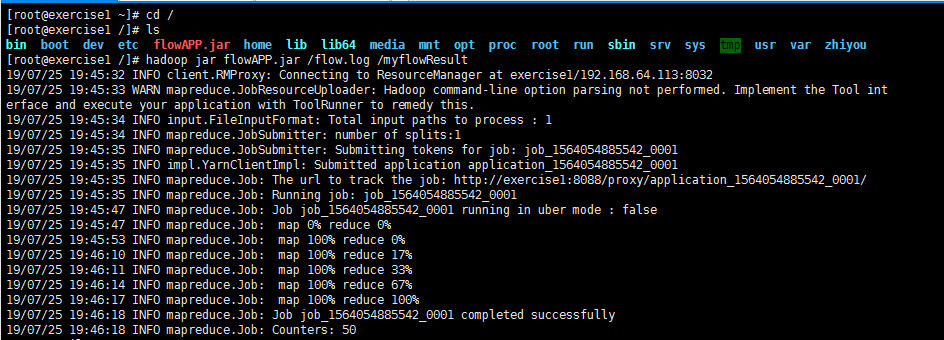
4、运行
1)打包
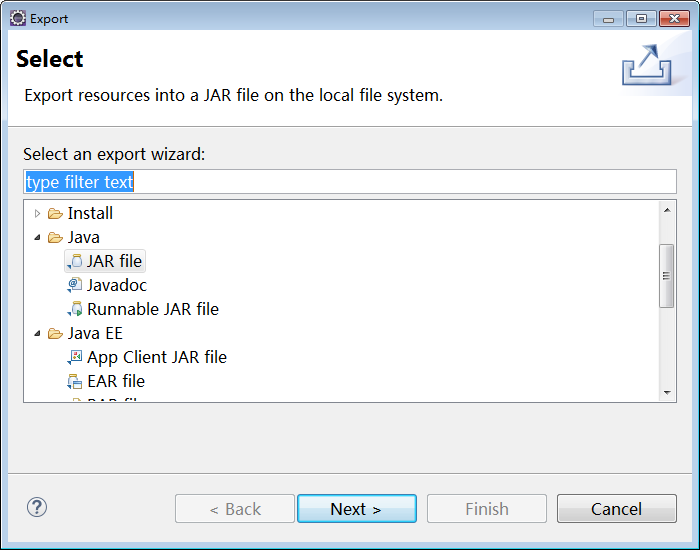
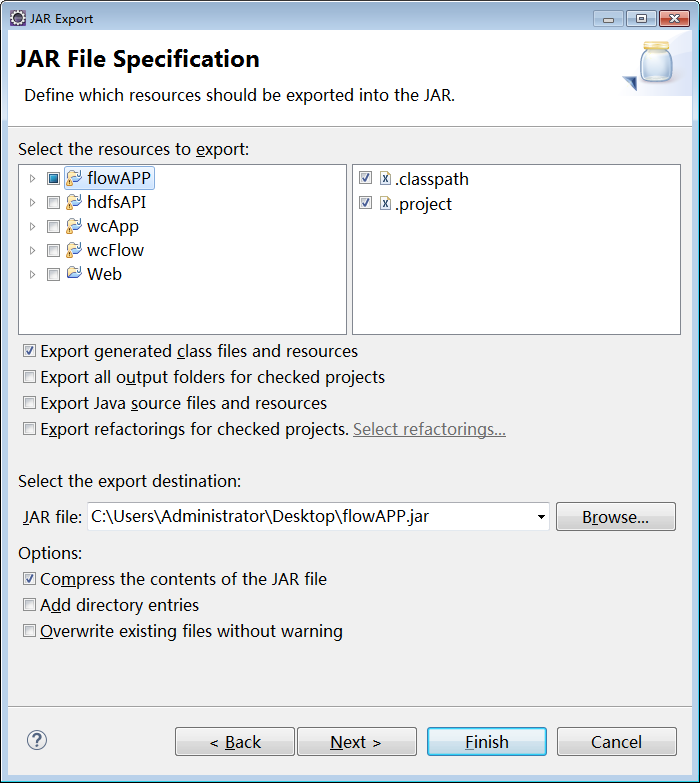
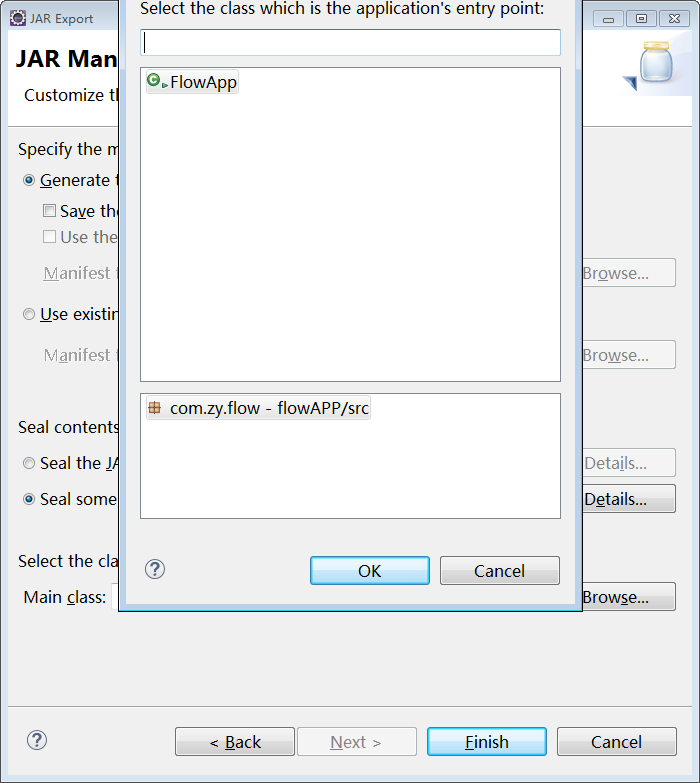
2)上传到linux
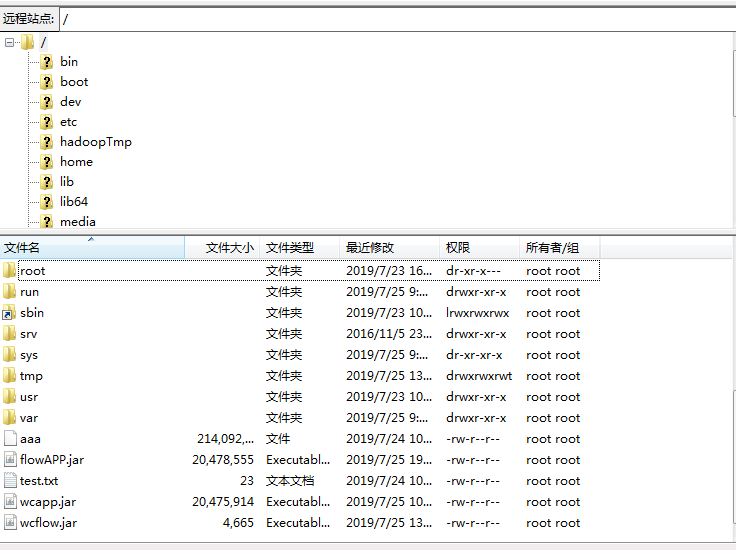
3)运行


 浙公网安备 33010602011771号
浙公网安备 33010602011771号