
centos6.6安装hadoop-2.5.0(六、各种node功能)
一、hadoop的YARN框架
hadoop的YARN职能就是将资源调度和任务调度分开
ResourceManager全局管理所有应用程序计算资源的分配,每一个job的ApplicationMaster负责相应任务的调度和协调,调度、启动每一个job所属的Application Master另外监控ApplicationMaster的存在情况
NodeManager功能比较专一,根据要求启动和监视集群中机器的计算容器container。负责Container状态的维护,并向RM保持心跳汇报该节点资源使用情况。
ApplicationMaster负责一个job生命周期内的所有工作。注意每一个Job都有一个ApplicationMaster。它和Mapreduce任务一样在容器中运行。AM通过与RN交互获取资源,然后通过与NM交互,启动计算任务
容器是由ResourceManager进行统一管理和分配的。有两类cntainer:一类是AM运行需要的container;另一类是AP为执行任务向RM申请的
二、hadoop的启动
hadoop是由分布式文件系统(HDFS)+编程模型(MapReduce)组成
再启动hadoop服务时,这两部分分别是由不同的脚本控制的,start-dfs.sh和start-yarn.sh
三、hadoop的HA
HDFS的管理是通过NameNode实现,数据存储在DataNode,NameNode一般运行在单个节点服务器上作为主处理器,DataNode一般运行在集群中的所有节点,对整个集群来说单个的NameNode容易出现单点故障,所以需要HA的支撑来保证集群持续可用
hadoop的NameNode和SecondaryNameNode只是阶段性的合并Edits和FsImage,缩短集群的启动时间,NameNode失效的时候,SecndaryName无法立刻提供服务,甚至无法保证数据的完整性,而且如果namenode数据丢失,在上一次合并后的文件系统的改动会丢失
四、HDFS的文件存储原理
例:
1、将一个文件分成三个数据块,写入HDFS系统中

2、这三块首先在namenode中登记元数据,哪个数据在哪台服务器上
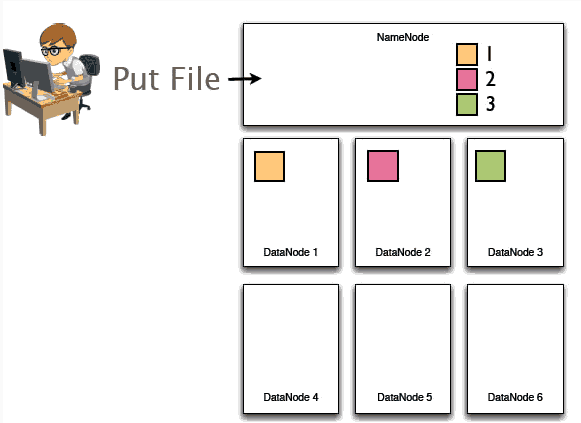
3、然后HDFS在datanode节点之间复制这些数据

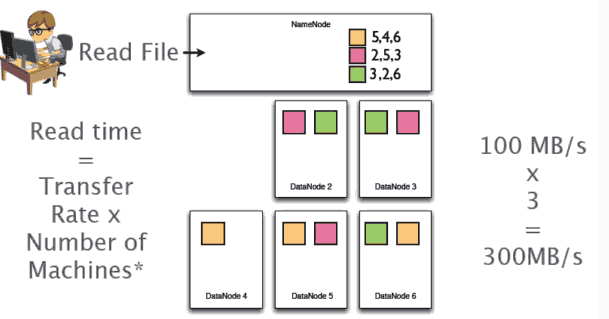
4、写完之后开始读取文件,读文件是并行读取,所有读取时间会比写文件提高三倍

 浙公网安备 33010602011771号
浙公网安备 33010602011771号