centos6.6安装hadoop-2.5.0(二、伪分布式部署)
操作系统:centos6.6(一台服务器)
环境:selinux disabled;iptables off;java 1.8.0_131
安装包:hadoop-2.5.0.tar.gz
伪分布式环境(适用于学习环境)
安装步骤:
1、解压安装包
# tar zxvf hadoop-2.5.0.tar.gz -C /data/hadoop/hadoopfake/
2、配置hadoop参数
1)设置环境变量 #vim /etc/profile
![]()
追加下面两行:
export HADOOP_HOME=/data/hadoop/hadoopfake/hadoop-2.5.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#source /etc/profile 使环境变量生效
#echo $HADOOP_HOME 验证hadoop参数
![]()
2)设置JAVA_HOME参数
分别修改/data/hadoop/hadoopfake/hadoop-2.5.0/etc/hadoop/下的hadoop-env.sh、mapred-env.sh、yarn-env.sh文件的JAVA_HOME参数
(如果JAVA_HOME在/etc/expofile或者~/.bashrc设置了环境变量export JAVA_HOME,那以上文件不用修改JAVA_HOME的参数)
3)配置core-site.xml文件
#vim /data/hadoop/hadoopfake/hadoop-2.5.0/etc/hadoop/core-site.xml
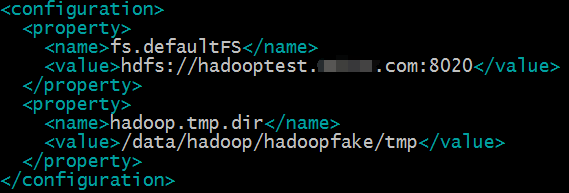
fs.defaultFS参数设置的是hdfs的地址;
hadoop.tmp.dir设置的是hadoop的临时目录,例如namenode的数据都会默认存放在这个目录;如果不配置这个参数,namenode数据会默认放在/tmp/hadoop*目录下,操作系统重启这个目录的所有数据都会清空,namenode的元数据会丢失,所以最好新建目录存放namenode的元数据。
4)配置hdfs-site.xml文件
#vim /data/hadoop/hadoopfake/hadoop-2.5.0/etc/hadoop/hdfs-site.xml

dfs.replication配置的是HDFS存储时的备份数量,伪分布式环境只有一个节点,所以设置为1就可以。
3、格式化、启动HDFS
#/data/hadoop/hadoopfake/hadoop-2.5.0/bin/hdfs namenode -format 格式化hdfs
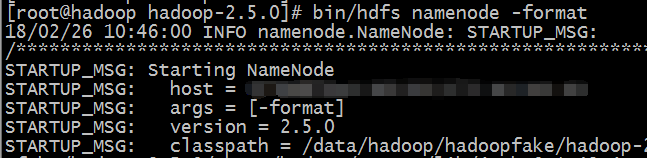
#ll /data/hadoop/hadoopfake/tmp/dfs/name/current 查看格式化后的目录

格式化是对分布式文件系统HDFS中的datanode进行分块,统计所有分块后的初始元数据存储在namenode中
格式化后hadoop.tmp.dir下面有dfs目录则格式化成功
fsimage是namenode元数据在内存满了后,持久化保存到文件
fsimage*md5是校验文件,用于校验fsimage的完整性
seen_txid是hadoop的版本
VERSION:namespaceID是namenode的唯一ID
clusterID是集群的ID,namenode和datanode集群ID一致时表明是一个集群
4、启动namenode
#/data/hadoop/hadoopfake/hadoop-2.5.0/sbin/hadoop-daemon.sh start namenode
![]()
5、启动datanode
#/data/hadoop/hadoopfake/hadoop-2.5.0/sbin/hadoop-daemon.sh start datanode
![]()
6、启动secondarynamenode
#/data/hadoop/hadoopfake/hadoop-2.5.0/sbin/hadoop-daemon.sh start secondarynamenode
![]()
7、使用jps命令查看node是否启动
#jps
![]()
8、测试创建目录,上传文件
#hadoop fs -mkdir /demo1

#hadoop fs -put /etc/passwd /demo1
#hadoop fs -cat /demo1/passwd 读取文件内容
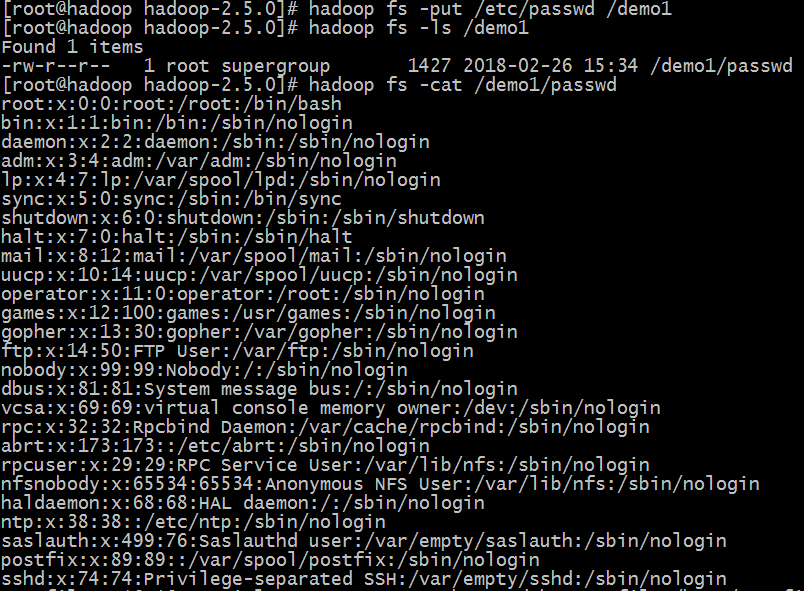
#hadoop fs -get /demo1/passwd

9、配置启动YARN
1)配置mapred-site.xml
#cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
#vim etc/hadoop/mapred-site.xml
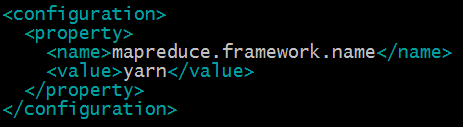
指定mapreduce运行在yarn框架上
2)配置yarn-site.xml
#vim etc/hadoop/yarn-site.xml
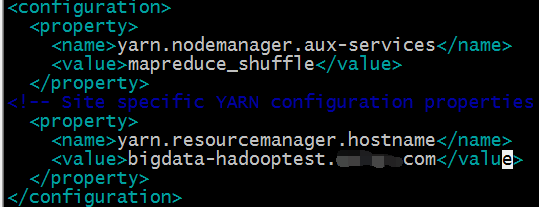
yarn.nodemanager.aux-services配置了yarn的默认混洗方式,选择为mapreduce的默认混洗算法
yarn.resourcemanager.hostname指定了Resourcemanager运行在哪个节点上
3)启动Resourcemanager
#vim /etc/hosts
![]()
#/sbin/yarn-daemon.sh start resourcemanager
![]()
#jps

4)启动nodemanager
#/sbin/yarn-daemon.sh start nodemanager
![]()
#jps
5)web界面
10、运行mapreduce job
1)创建输入目录
#hadoop fs -mkdir -p /wordcountdemo/input

2)创建文件并上传到/wordcountdemo/input目录中
#cat wc.input
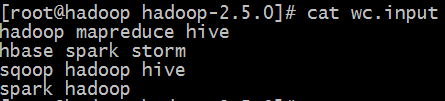
#hadoop fs -put wc.input /wordcountdemo/input/

3)运行wordcount mapreduce job
#bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-example-2.5.0.jar wordcount /wordcountdemo/input /wordcountdemo/output
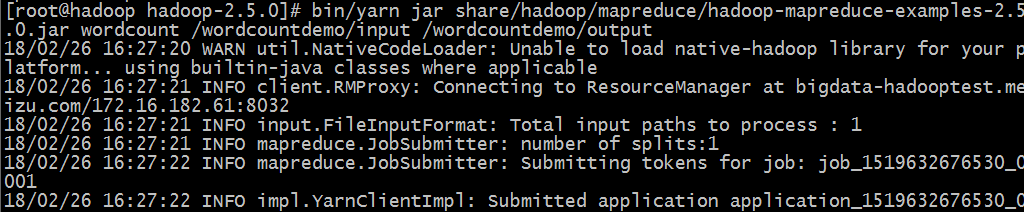
#hadoop fs -ls /wordcountdemo/output 查看输出结果
![]()
_SUCCESS文件是个空文件,只是来说明job执行成功
part-r-00000是结果文件,-r-说明这个文件是reduce阶段产生的结果,如没有reduce则应该是-m-
#hadoop fs -cat /wordcountdemo/output/part-r-00000 查看输出文件内容

11、停止hadoop
#sbin/hadoop-daemon.sh stop namenode
#sbin/hadoop-daemon.sh stop datanode
#sbin/hadoop-daemon.sh stop secondarynode
#sbin/yarn-daemon.sh stop resourcemanager
#sbin/yarn-daemon.sh stop nodemanager
12、开启历史服务
开启历史服务可在web界面上查看yarn上执行的job情况等信息
#sbin/mr-jobhistory-daemon.sh start historyserver
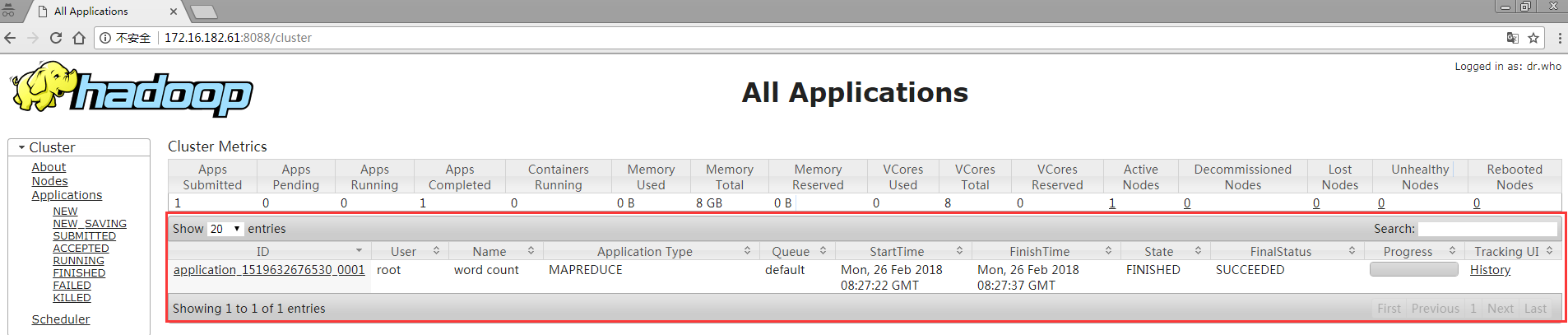
正在执行中的任务



 浙公网安备 33010602011771号
浙公网安备 33010602011771号