lecture2 readings
1. Interstellar: using halide’s scheduling language to analyze dnn accelerators (formerly: dnn dataflow choice is overrated.
- 动机
- CNN存在大量的数据reuse,这为局部性优化(loop blocking)提供了空间。而全连接数据复用不多,energy cost主要由于off-chip memory access,因此on-chip dataflow影响不大.
-
energy efficiency is more tightly tied to the design of the hierarchical memory system and how each level in this hierarchy is sized.
-
cost of each RF fetch is proportional to the RF size, it is most efficient to adopt a relatively small RF.
-
This small first-level memory creates the need for a memory hierarchy, since the size ratio between the adjacent memory levels needs to be in a certain range to balance the total energy cost of accessing data at each level in the memory
hierarchy - 工作
-
Introduces a systematic approach to precisely and concisely describe the design space of DNN accelerators as schedules of loop transformations。
-
Shows that both the micro-architectures and dataflow mappings for existing DNN accelerators can be expressed as schedules of a Halide program, and extends the Halide schedule language and the Halide compiler to produce different hardware designs in the space of dense DNN accelerators.
-
Creates a tool to optimize the memory hierarchy, which is more important than the choice of dataflow, achieving a 1.8× to 4.2× energy improvement for CNNs, LSTMs, and MLPs
-
- Design Space
- Dataflow: WS, OS, RS
- Resource Allocation
- the dimensions of the PE array
-
the size of each level in the memory hierarchy
- Loop blocking,loop blocking, reordering
- A Formal Dataflow Taxonomy
- 意思就是卷积的7层循环,任意两层被spatially unrolled in hardware,形成不同的dataflow。For example, if the X and Y loops are unrolled onto the 2D array, then each PE produces a single output pixel
- 对output stationary分析:This output stationary pattern implies that input pixels will be reused across neighbor PEs as they contribute to multiple output pixels in a convolution, and the filter weights shared by all output pixels must be transferred to all PEs
- replication很重要,replication就是把两层或多层循环展开到一个维度。
- 后面就是implementation和实验了,直接补几张图吧
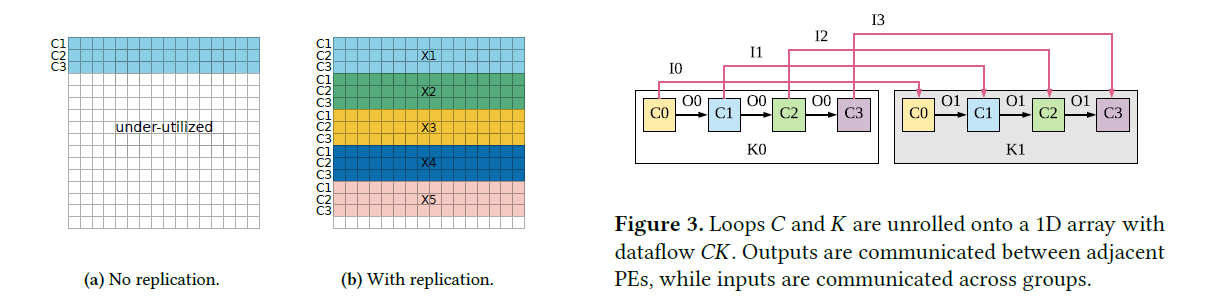
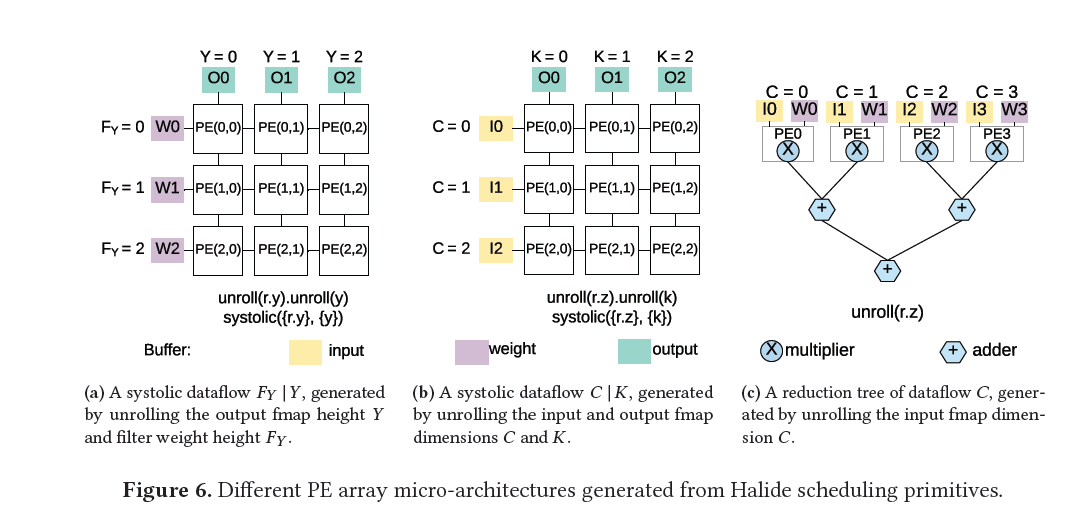
2. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks
- 动机
-
Although highly-parallel compute paradigms, such as SIMD/SIMT, effectively address the computation requirement to achieve high throughput, energy consumption still remains high as data movement can be more expensive than computation.
-
we present a novel dataflow, called row stationary (RS), that minimizes data movement energy consumption on a spatial architecture. This is realized by exploiting local data reuse of filter weights and feature map pixels, i.e., activations, in the high-dimensional convolutions, and minimizing data movement of partial sum accumulations.
-
- 工作
-
A taxonomy(分类) that classifies existing CNN dataflows from previous research
-
A spatial architecture based on a new CNN dataflow, called row stationary, which is optimized for throughput and energy efficiency. It works on both convolutional and fully-connected layers, and optimizes all types of data movement in the storage hierarchy
-
An analysis framework that can quantify the energy efficiency of different CNN dataflows under the same hardware constraints
-
For a variety of CNN dataflows, we present a comparative analysis of the energy costs associated with data movement and the impact of different types of data reuse
-
- SPATIAL ARCHITECTURE(SA)
-
Spatial architectures (SAs) are a class of accelerators that can exploit high compute parallelism using direct communication between an array of relatively simple processing engines (PEs). They can be designed or programmed to support different algorithms, which are mapped onto the PEs using specialized dataflows. Compared with SIMD/SIMT architectures, SAs are particularly suitable for applications whose dataflow exhibits producer-consumer relationships or can leverage efficient data sharing among a region of PEs.
-
coarse-grained SAs that consist of tiled arrays of ALU-style PEs connected together via on-chip networks
- 流行的两个原因
-
the operations in a CNN layer (e.g., convolutional, fully-connected, pooling, etc.) are uniform and exhibit high parallelism, which can be computed quite naturally with parallel ALUstyle PEs.
-
direct inter-PE communication can be used very effectively for (1) passing partial sums to achieve spatially distributed accumulation, or (2) sharing the same input data for parallel computation without incurring higher energy data transfers
-
- 存储架构:DRAM, global buffer, array (inter-PE communication) and RF
![]()
- 存储架构:DRAM, global buffer, array (inter-PE communication) and RF
-
- Challenges in CNN Processing
- Data Handling
- input data(NCHH) reuse
- convolutional reuse: Each filter weight is reused E^2 times in the same ifmap plane(平面), and each ifmap pixel, i.e., activation, is usually reused R^2 times in the same filter plane.
-
filter(MCRR) reuse: Each filter weight is further reused across the batch of N ifmaps in both CONV and FC layers
-
ifmap(NMEE) reuse: Each ifmap pixel is further reused across M filters (to generate the M output channels) in both CONV and FC layers
-
operation scheduling so that the generated psums can be reduced as soon as possible to save both the storage space and memory R/W energy
- input data(NCHH) reuse
- Data Handling
- EXISTING CNN DATAFLOWS
- Weight Stationary (WS) Dataflow
-
Each filter weight remains stationary in the RF to maximize convolutional reuse and filter reuse. Once a weight is fetched from DRAM to the RF of a PE, the PE runs through all NE^2 operations that use the same filter weight.
-
R*R weights from the same filter and channel are laid out to a region of R*R PEs and stay stationary. Each pixel in an ifmap plane from the same channel is broadcastto the same R*R PEs sequentially, and the psums generated
by each PE are further accumulated spatially across these PEs. -
The RF is used to store the stationary filter weights. Due to the operation scheduling that maximally reuses stationary weights, psums are not always immediately reducible, and will be temporarily stored to the global buffer.
If the buffer is not large enough, the number of psums that are generated together has to be limited, and therefore limits the number of filters that can be loaded on-chip at a time.
-
- Output Stationary (OS) Dataflow
-
The accumulation of each ofmap pixel stays stationary in a PE. The psums are stored in the same RF for accumulation to minimize the psum accumulation cost
-
This type of dataflow uses the space of the PE array to process a region of the 4D ofmap at a time. To select a region out of the high-dimensional space, there are two choices to make: (1) multiple ofmap channels (MOC) vs.
single ofmap channels (SOC), and (2) multiple ofmap-plane pixels (MOP) vs. single ofmap-plane pixels (SOP). This creates three practical OS dataflow subcategories: SOC-MOP, MOC-MOP, and MOC-SOP. -
SOC-MOP is used mainly for CONV layers, and focuses on processing a single plane of ofmap at a time. It further maximizes convolutional reuse in addition to psum accumulation.(Interstellar论文也提到该观点)
-
All OS dataflows use the RF for psum storage to achieve stationary accumulation. In addition, SOCMOP and MOC-MOP require additional RF storage for ifmap buffering(是否也要对weight缓存) to exploit convolutional reuse within the PE array.
-
- No Local Reuse (NLR) Dataflow:it does not exploit data reuse at the RF level;it uses inter-PE communication for ifmap reuse and psum accumulation;
- Weight Stationary (WS) Dataflow
- ENERGY-EFFICIENT DATAFLOW: ROW STATIONARY
- 动机:While existing dataflows attempt to maximize certain types of input data reuse or minimize the psum accumulation cost, they fail to take all of them into account at once(OS不是考虑了么,但可能不满足下面一条,适用性). This results in inefficiency when the layer shape or hardware resources vary. Therefore, it would be desirable if the dataflow could adapt to different conditions and optimize for all types of data movement energy costs.
- 1D Convolution Primitives
-
It breaks the high-dimensional convolution down into 1D convolution primitives that can run in parallel; each primitive operates on one row of filter weights and one row of ifmap pixels, and generates one row of psums. Psums from different primitives are further accumulated together to generate the ofmap pixels. The inputs to the 1D convolution come from the storage hierarchy, e.g., the global buffer or DRAM。
-
Each primitive is mapped to one PE for processing; therefore, the computation of each row pair stays stationary in the PE, which creates convolutional reuse of filter weights and ifmap pixels at the RF level.
- 问题:since the entire convolution usually contains hundreds of thousands of primitives, the exact mapping of all primitives to the PE array is non-trivial, and will greatly affect the energy efficiency,于是有了下面
-
- Two-Step Primitive Mapping
-
The logical mapping first deploys the primitives into a logical PE array, which has the same size as the number of 1D convolution primitives and is usually much larger than the physical PE array in hardware. The physical mapping then
folds the logical PE array so it fits into the physical PE array. Folding implies serializing the computation, and is determined by the amount of on-chip storage, including both the global buffer and local RF -
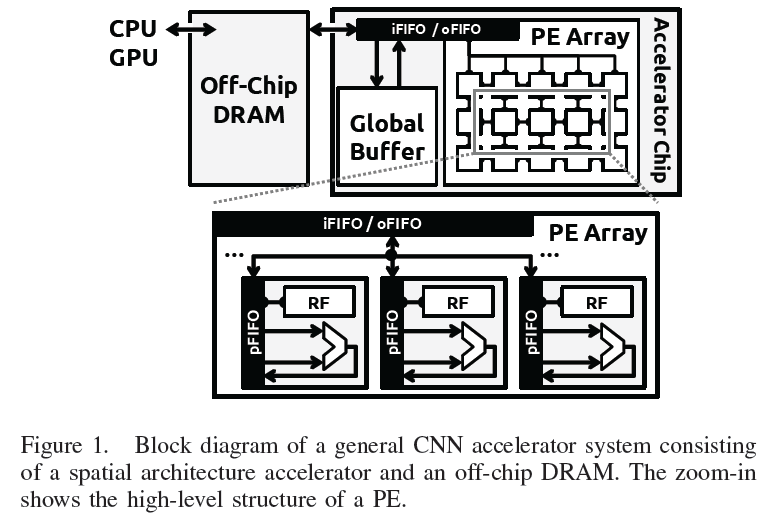
Since there is considerable spatial locality between the PEs that compute a 2D convolution in the logical PE array, we group them together as a logical PE set. Fig. 6 shows a logical PE set, where each filter row and ifmap row are horizontally and diagonally reused, respectively, and each row of psums is vertically accumulated.
![]()
- Energy-Efficient Data Handling
-
PE: Specifically, there are convolutional reuse within the computation of each primitive, filter reuse and ifmap reuse due to input data sharing between folded primitives, and psum accumulation within each primitive and across primitives.
-
Array (inter-PE communication): Convolutional reuseexists within each set and is completely exhausted up to this level. Filter reuse and ifmap reuse can be achieved by having multiple sets mapped spatially across the physical PE
array. Psum accumulation is done within each set as well as across sets that are mapped spatially. -
Global Buffer: Depending on its size, the global buffer is used to exploit the rest of filter reuse, ifmap reuse and psum accumulation that remain from the RF and array levels after the second phase folding.
-
- Framework for Energy Efficiency Analysis
-
the analysis is formulated in two parts: (1) the input data access energy cost, including filters and ifmaps, and (2) the psum accumulation energy cost. The energy costs are quantified through counting the number of accesses to each level of the previously defined hierarchy, and weighting the accesses at each level with a cost from Table IV. The overall data movement energy of a dataflow is obtained through combining the results from the two types of input data and the psums.
- 实验分析
-
In terms of architectural scalability, all dataflows can use the larger hardware area and higher parallelism to reduce DRAM accesses. The benefit is most significant on WS and OSC, which also means that they are more demanding on
hardware resources. -
WS is inefficient at ifmap reuse, and the OS dataflows cannot reuse ifmaps and weights as efficiently as RS since they focus on generating psums that are reducible. NLR does not exploit any type of reuse of weights in the PE
array, and therefore consumes most of its energy for weight accesses. RS is the only dataflow that optimizes energy for all data types simultaneously。
-
-
3. Gemmini: Enabling Systematic Deep-Learning Architecture Evaluation via Full-Stack Integration
- 动机
-
existing DNN generators have little support for a fullstack programming interface which provides both high and low-level control of the accelerator, and little support for full SoC(System-on-Chip) integration, making it challenging to evaluate system-level implications
-
In fact, recent industry evaluations have demonstrated that modern ML workloads could spend as much as 77% of their time running on CPUs, even in the presence of a hardware accelerator, to execute either new operators or to move data between the CPU and accelerators
-
- 工作
-
We build Gemmini, an open-source, full-stack DNN accelerator design infrastructure to enable systematic evaluation of deeplearning architectures. Specifically, Gemmini provides a flexible hardware template, a multi-layered software stack, and an
integrated SoC environment -
We perform rigorous evaluation of Gemmini-generated accelerators using FPGA-based performance measurement and commercial ASIC synthesis flows for performance and efficiency analysis.
-
We demonstrate that the Gemmini infrastructure enables system-accelerator co-design of SoCs running DNN workloads, including the design of efficient virtual-address translation schemes for DNN accelerators and the provisioning of memory
resources in a shared cache hierarchy
-
- DNN Accelerator Generators
-
Gemmini supports 1) both floating and fixed point data types to handle data representations in training and inference, 2) multiple dataflows that can be configured at design time and run time, 3) both vector and systolic spatial array architectures,
enabling quantitative comparison of their efficiency and scalability differences, and 4) direct execution of different DNN operators. - GEMMINI GENERATOR
- Architectural Template
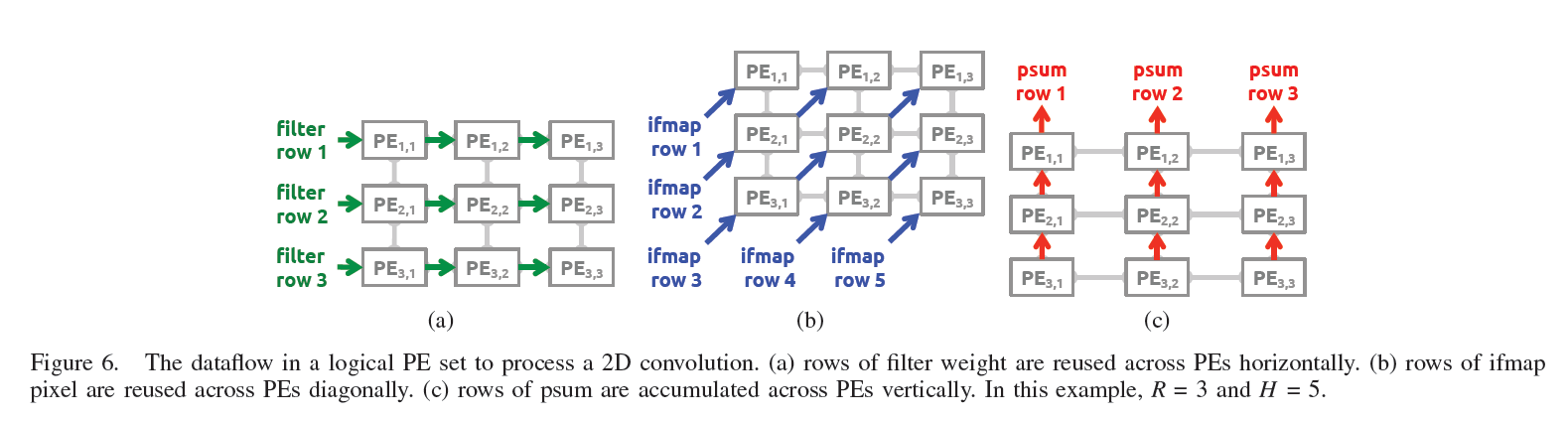
- 两层架构:The spatial array is first composed of tiles, where tiles are connected via explicit pipeline registers. Each of the individual tiles can be further broken down into an array of PEs, where PEs in the same tile are connected combinationally without pipeline registers. Each PE performs a single multiply-accumulate (MAC) operation every cycle, using either the weight- or the outputstationary dataflow. Every PE and every tile shares inputs and outputs only with its adjacent neighbors
![]()
- Programming Support
- Data Staging and Mapping
- Virtual Memory Support
- System Support
- Architectural Template
-
4. MIXED PRECISION TRAINING
- 动机
-
Memory bandwidth pressure is lowered by using fewer bits to to store the same number of values.
-
Arithmetic time can also be lowered on processors that offer higher throughput for reduced precision math. For example, half-precision math throughput in recent GPUs is 2倍 to 8倍 higher than for single-precision.
-
In addition to speed improvements, reduced precision formats also reduce the amount of memory required for training.
-
- 工作:
-
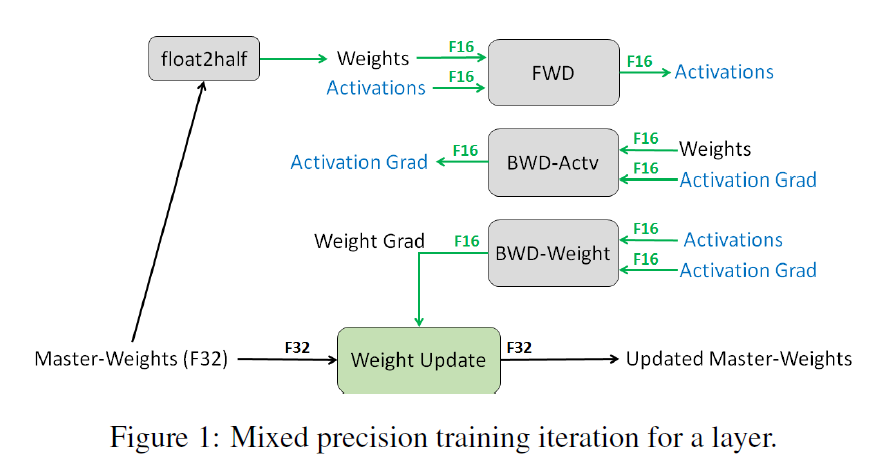
Since this format has a narrower range than single-precision we propose three techniques for preventing the loss of critical information
-
we recommend maintaining a single-precision copy of weights that accumulates the gradients after each optimizer step (this copy is rounded to half-precision for the forward- and back-propagation).
-
we propose loss-scaling to preserve gradient values with small magnitudes
-
we use half-precision arithmetic that accumulates into single-precision outputs, which are converted to halfprecision before storing to memory
-
-
- FP32 MASTER COPY OF WEIGHTS
- 原因
-
One explanation is that updates (weight gradients multiplied by the learning rate) become too small to be represented in FP16 - any value whose magnitude is smaller than 2*-24 becomes zero in FP16. We can see in Figure 2b that approximately 5% of weight gradient values have exponents smaller than -24. These small valued gradients would become zero in the optimizer when multiplied with the learning rate and adversely affect the model accuracy
- Another explanation is that the ratio of the weight value to the weight update is very large. This can happen when the magnitude of a normalized weight value is at least 2048 times larger that of the weight update
-
-
Even though maintaining an additional copy of weights increases the memory requirements for the weights by 50% compared with single precision training, impact on overall memory usage is much smaller.
![]()
- 原因
- LOSS SCALING
- 原因:Note that much of the FP16 representable range was left unused, while many values were below the minimum representable range and became zeros. Scaling up the gradients will shift them to occupy more of the representable range and preserve values that are otherwise lost to zeros。
-
One efficient way to shift the gradient values into FP16-representable range is to scale the loss value computed in the forward pass, prior to starting back-propagation。 It is simplest to perform this unscaling right after the backward pass but before gradient clipping or any other gradient-related computations, ensuring that no hyper-parameters (such as gradient clipping threshold, weight decay, etc.) have to be adjusted.
- ARITHMETIC PRECISION
- DNN中三种基本操作: vector dot-products(fc), reductions(sum), and point-wise operations(relu)
-
To maintain model accuracy, we found that some networks require that FP16 vector dot-product accumulates the partial products into an FP32 value, which is converted to FP16 before writing to memory.
-
Large reductions (sums across elements of a vector) should be carried out in FP32. Such reductions mostly come up in batch-normalization layers

 浙公网安备 33010602011771号
浙公网安备 33010602011771号