

TDengine简介
TDengine 是一款开源、高性能、云原生的时序数据库,且针对物联网、车联网、工业互联网、金融、IT 运维等场景进行了优化。您可以像使用关系型数据库 MySQL 一样来使用它.
数据模型和整体架构
在典型的物联网, 运维检测场景中, 往往有多种不同类型的传感器用来采集各种不同类型的数据, 而每种类型的数据又有多个同种类型的设备分布在不同的空间. 最后需要将它们采集到的的数据汇总,
计算和分析, 而同种类型的设备采集到的数据结构又是完全相同的.
需要采集的数据的特点总结就是:
- 数据连续性,时序性
- 数据结构化
- 数据量巨大
因此TDengine的特点就是:
- 因为采集的数据结构固定, 都是结构化数据, 因此可以使用关系型数据库模型来管理数据, 便于根据各种条件进行查询归档
- 每个设备都是单独对一个表进行写入, 每个表数据源唯一,因此TDengine对每个采集器单独建表, 这样就不需要加锁进行隔离
- 对于一个数据采集点而言,其产生的数据是时序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
超级表:同一类型数据采集点的集合
TDengine把每一类不同的采集点都作为一个超级表, 每个超级表下又根据该类设备不同设备编号分为多个子表. 子表用来存储每个采集点采集到的数据, 超级表用于聚合, 计算, 分析.
每个超级表下的子表的表结构都是完全相同的, 只有标签不同, 标签的格式在超级表中定义, 且后期可以修改.
TDengine主节点写入流程: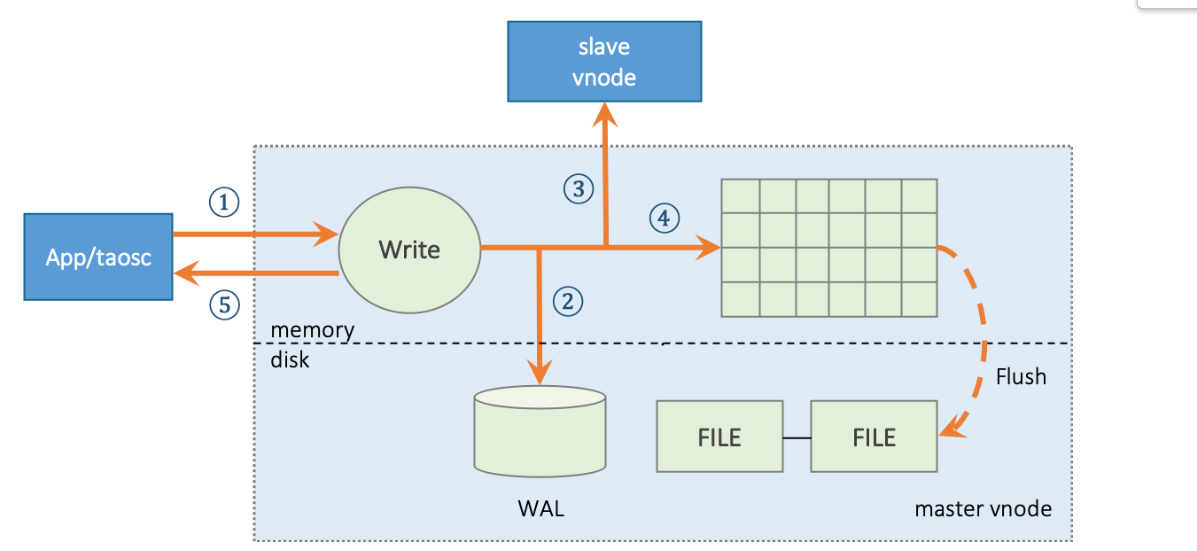
- master vnode主节点收到应用的数据插入请求,验证OK,进入下一步;
- 如果系统配置参数 walLevel 大于 0,vnode 将把该请求的原始数据包写入数据库日志文件 WAL。如果 walLevel 设置为 2,而且 fsync 设置为 0,TDengine 还将 WAL 数据立即落盘,以保证即使宕机,也能从数据库日志文件中恢复数据,避免数据的丢失;
- 如果有多个副本,vnode 将把数据包转发给同一虚拟节点组内的 slave vnodes, 该转发包带有数据的版本号(version);
- 写入内存,并将记录加入到 skip list跳表(缓存);
- master vnode 返回确认信息给应用,表示写入成功。
- 如果第 2、3、4 步中任何一步失败,将直接返回错误给应用。
SQL语法可以参照官方文档:https://www.taosdata.com/docs/cn/v2.0/taos-sql#-7


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?