深度解密Go语言之 pprof
相信很多人都听过“雷神 3”关于性能优化的故事。在一个 3D 游戏引擎的源码里,John Carmack 将 1/sqrt(x) 这个函数的执行效率优化到了极致。
一般我们使用二分法,或者牛顿迭代法计算一个浮点数的平方根。但在这个函数里,作者使用了一个“魔数”,根本没有迭代,两步就直接算出了平方根。令人叹为观止!
因为它是最底层的函数,而游戏里涉及到大量的这种运算,使得在运算资源极其紧张的 DOS 时代,游戏也可以流畅地运行。这就是性能优化的魅力!
工作中,当业务量比较小的时候,用的机器也少,体会不到性能优化带来的收益。而当一个业务使用了几千台机器的时候,性能优化 20%,那就能省下几百台机器,一年能省几百万。省下来的这些钱,给员工发年终奖,那得多 Happy!
一般而言,性能分析可以从三个层次来考虑:应用层、系统层、代码层。
应用层主要是梳理业务方的使用方式,让他们更合理地使用,在满足使用方需求的前提下,减少无意义的调用;系统层关注服务的架构,例如增加一层缓存;代码层则关心函数的执行效率,例如使用效率更高的开方算法等。
做任何事,都要讲究方法。在很多情况下,迅速把事情最关键的部分完成,就能拿到绝大部分的收益了。其他的一些边边角角,可以慢慢地缝合。一上来就想完成 100%,往往会陷入付出了巨大的努力,却收获寥寥的境地。
性能优化这件事也一样,识别出性能瓶颈,会让我们付出最小的努力,而得到最大的回报。
Go 语言里,pprof 就是这样一个工具,帮助我们快速找到性能瓶颈,进而进行有针对性地优化。
什么是 pprof
代码上线前,我们通过压测可以获知系统的性能,例如每秒能处理的请求数,平均响应时间,错误率等指标。这样,我们对自己服务的性能算是有个底。
但是压测是线下的模拟流量,如果到了线上呢?会遇到高并发、大流量,不靠谱的上下游,突发的尖峰流量等等场景,这些都是不可预知的。
线上突然大量报警,接口超时,错误数增加,除了看日志、监控,就是用性能分析工具分析程序的性能,找到瓶颈。当然,一般这种情形不会让你有机会去分析,降级、限流、回滚才是首先要做的,要先止损嘛。回归正常之后,通过线上流量回放,或者压测等手段,制造性能问题,再通过工具来分析系统的瓶颈。
一般而言,性能分析主要关注 CPU、内存、磁盘 IO、网络这些指标。
Profiling 是指在程序执行过程中,收集能够反映程序执行状态的数据。在软件工程中,性能分析(performance analysis,也称为 profiling),是以收集程序运行时信息为手段研究程序行为的分析方法,是一种动态程序分析的方法。
Go 语言自带的 pprof 库就可以分析程序的运行情况,并且提供可视化的功能。它包含两个相关的库:
-
runtime/pprof
对于只跑一次的程序,例如每天只跑一次的离线预处理程序,调用 pprof 包提供的函数,手动开启性能数据采集。 -
net/http/pprof
对于在线服务,对于一个 HTTP Server,访问 pprof 提供的 HTTP 接口,获得性能数据。当然,实际上这里底层也是调用的 runtime/pprof 提供的函数,封装成接口对外提供网络访问。
pprof 的作用
pprof 是 Go 语言中分析程序运行性能的工具,它能提供各种性能数据:

allocs 和 heap 采样的信息一致,不过前者是所有对象的内存分配,而 heap 则是活跃对象的内存分配。
The difference between the two is the way the pprof tool reads there at start time. Allocs profile will start pprof in a mode which displays the total number of bytes allocated since the program began (including garbage-collected bytes).
上图来自参考资料【wolfogre】的一篇 pprof 实战的文章,提供了一个样例程序,通过 pprof 来排查、分析、解决性能问题,非常精彩。
- 当 CPU 性能分析启用后,Go runtime 会每 10ms 就暂停一下,记录当前运行的 goroutine 的调用堆栈及相关数据。当性能分析数据保存到硬盘后,我们就可以分析代码中的热点了。
- 内存性能分析则是在堆(Heap)分配的时候,记录一下调用堆栈。默认情况下,是每 1000 次分配,取样一次,这个数值可以改变。栈(Stack)分配 由于会随时释放,因此不会被内存分析所记录。由于内存分析是取样方式,并且也因为其记录的是分配内存,而不是使用内存。因此使用内存性能分析工具来准确判断程序具体的内存使用是比较困难的。
- 阻塞分析是一个很独特的分析,它有点儿类似于 CPU 性能分析,但是它所记录的是 goroutine 等待资源所花的时间。阻塞分析对分析程序并发瓶颈非常有帮助,阻塞性能分析可以显示出什么时候出现了大批的 goroutine 被阻塞了。阻塞性能分析是特殊的分析工具,在排除 CPU 和内存瓶颈前,不应该用它来分析。
pprof 如何使用
我们可以通过
报告生成、Web 可视化界面、交互式终端三种方式来使用pprof。
—— 煎鱼《Golang 大杀器之性能剖析 PProf》
runtime/pprof
拿 CPU profiling 举例,增加两行代码,调用 pprof.StartCPUProfile 启动 cpu profiling,调用 pprof.StopCPUProfile() 将数据刷到文件里:
import "runtime/pprof"
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file")
func main() {
// …………
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
// …………
}
net/http/pprof
启动一个端口(和正常提供业务服务的端口不同)监听 pprof 请求:
import _ "net/http/pprof"
func initPprofMonitor() error {
pPort := global.Conf.MustInt("http_server", "pprofport", 8080)
var err error
addr := ":" + strconv.Itoa(pPort)
go func() {
err = http.ListenAndServe(addr, nil)
if err != nil {
logger.Error("funcRetErr=http.ListenAndServe||err=%s", err.Error())
}
}()
return err
}
pprof 包会自动注册 handler, 处理相关的请求:
// src/net/http/pprof/pprof.go:71
func init() {
http.Handle("/debug/pprof/", http.HandlerFunc(Index))
http.Handle("/debug/pprof/cmdline", http.HandlerFunc(Cmdline))
http.Handle("/debug/pprof/profile", http.HandlerFunc(Profile))
http.Handle("/debug/pprof/symbol", http.HandlerFunc(Symbol))
http.Handle("/debug/pprof/trace", http.HandlerFunc(Trace))
}
第一个路径 /debug/pprof/ 下面其实还有 5 个子路径:
goroutine
threadcreate
heap
block
mutex
启动服务后,直接在浏览器访问:
就可以得到一个汇总页面:
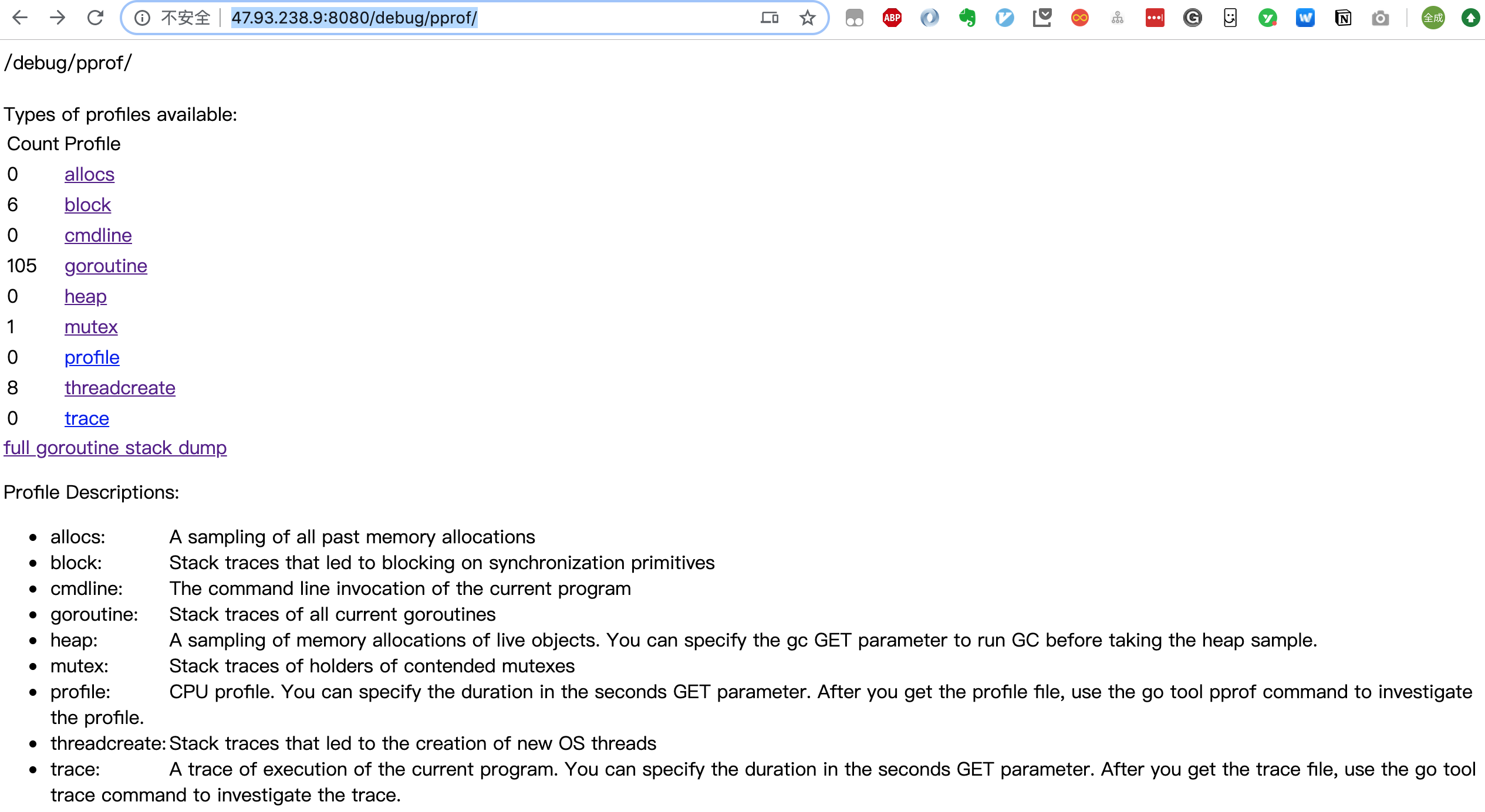
可以直接点击上面的链接,进入子页面,查看相关的汇总信息。
关于 goroutine 的信息有两个链接,goroutine 和 full goroutine stack dump,前者是一个汇总的消息,可以查看 goroutines 的总体情况,后者则可以看到每一个 goroutine 的状态。页面具体内容的解读可以参考【大彬】的文章。
点击 profile 和 trace 则会在后台进行一段时间的数据采样,采样完成后,返回给浏览器一个 profile 文件,之后在本地通过 go tool pprof 工具进行分析。
当我们下载得到了 profile 文件后,执行命令:
go tool pprof ~/Downloads/profile

就可以进入命令行交互式使用模式。执行 go tool pprof -help 可以查看帮助信息。
直接使用如下命令,则不需要通过点击浏览器上的链接就能进入命令行交互模式:
go tool pprof http://47.93.238.9:8080/debug/pprof/profile
当然也是需要先后台采集一段时间的数据,再将数据文件下载到本地,最后进行分析。上述的 Url 后面还可以带上时间参数:?seconds=60,自定义 CPU Profiling 的时长。
类似的命令还有:
# 下载 cpu profile,默认从当前开始收集 30s 的 cpu 使用情况,需要等待 30s
go tool pprof http://47.93.238.9:8080/debug/pprof/profile
# wait 120s
go tool pprof http://47.93.238.9:8080/debug/pprof/profile?seconds=120
# 下载 heap profile
go tool pprof http://47.93.238.9:8080/debug/pprof/heap
# 下载 goroutine profile
go tool pprof http://47.93.238.9:8080/debug/pprof/goroutine
# 下载 block profile
go tool pprof http://47.93.238.9:8080/debug/pprof/block
# 下载 mutex profile
go tool pprof http://47.93.238.9:8080/debug/pprof/mutex
进入交互式模式之后,比较常用的有 top、list、web 等命令。
执行 top:

得到四列数据:
| 列名 | 含义 |
|---|---|
| flat | 本函数的执行耗时 |
| flat% | flat 占 CPU 总时间的比例。程序总耗时 16.22s, Eat 的 16.19s 占了 99.82% |
| sum% | 前面每一行的 flat 占比总和 |
| cum | 累计量。指该函数加上该函数调用的函数总耗时 |
| cum% | cum 占 CPU 总时间的比例 |
其他类型,如 heap 的 flat, sum, cum 的意义和上面的类似,只不过计算的东西不同,一个是 CPU 耗时,一个是内存大小。
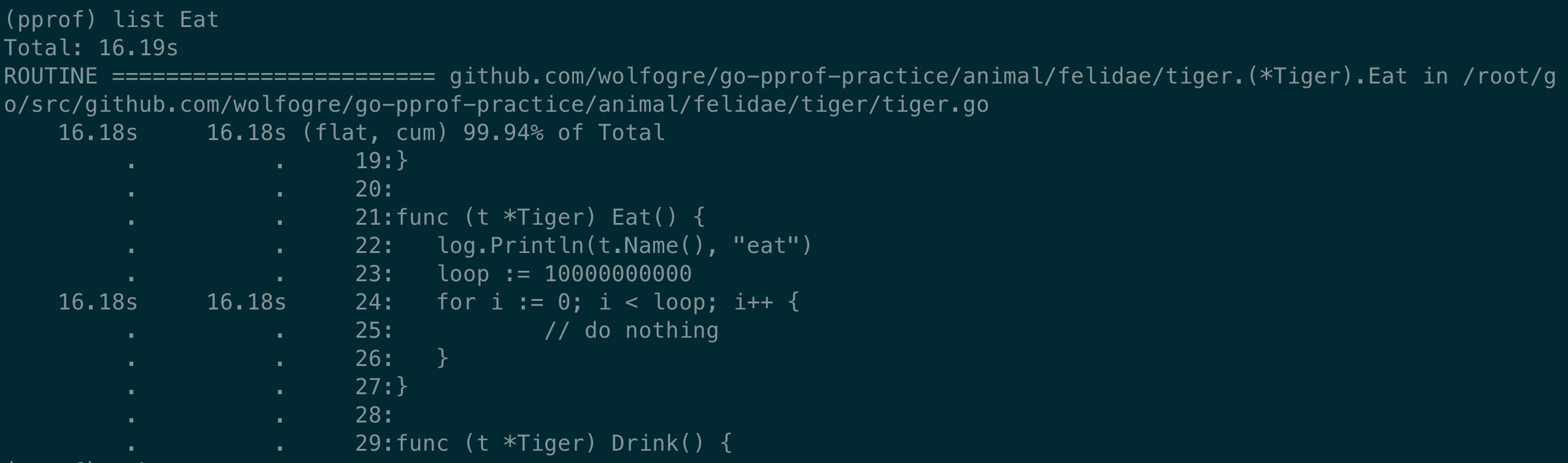
执行 list,使用正则匹配,找到相关的代码:
list Eat
直接定位到了相关长耗时的代码处:
执行 web(需要安装 graphviz,pprof 能够借助 grapgviz 生成程序的调用图),会生成一个 svg 格式的文件,直接在浏览器里打开(可能需要设置一下 .svg 文件格式的默认打开方式):

图中的连线代表对方法的调用,连线上的标签代表指定的方法调用的采样值(例如时间、内存分配大小等),方框的大小与方法运行的采样值的大小有关。
每个方框由两个标签组成:在 cpu profile 中,一个是方法运行的时间占比,一个是它在采样的堆栈中出现的时间占比(前者是 flat 时间,后者则是 cumulate 时间占比);框越大,代表耗时越多或是内存分配越多。
另外,traces 命令还可以列出函数的调用栈:

除了上面讲到的两种方式(报告生成、命令行交互),还可以在浏览器里进行交互。先生成 profile 文件,再执行命令:
go tool pprof --http=:8080 ~/Downloads/profile
进入一个可视化操作界面:
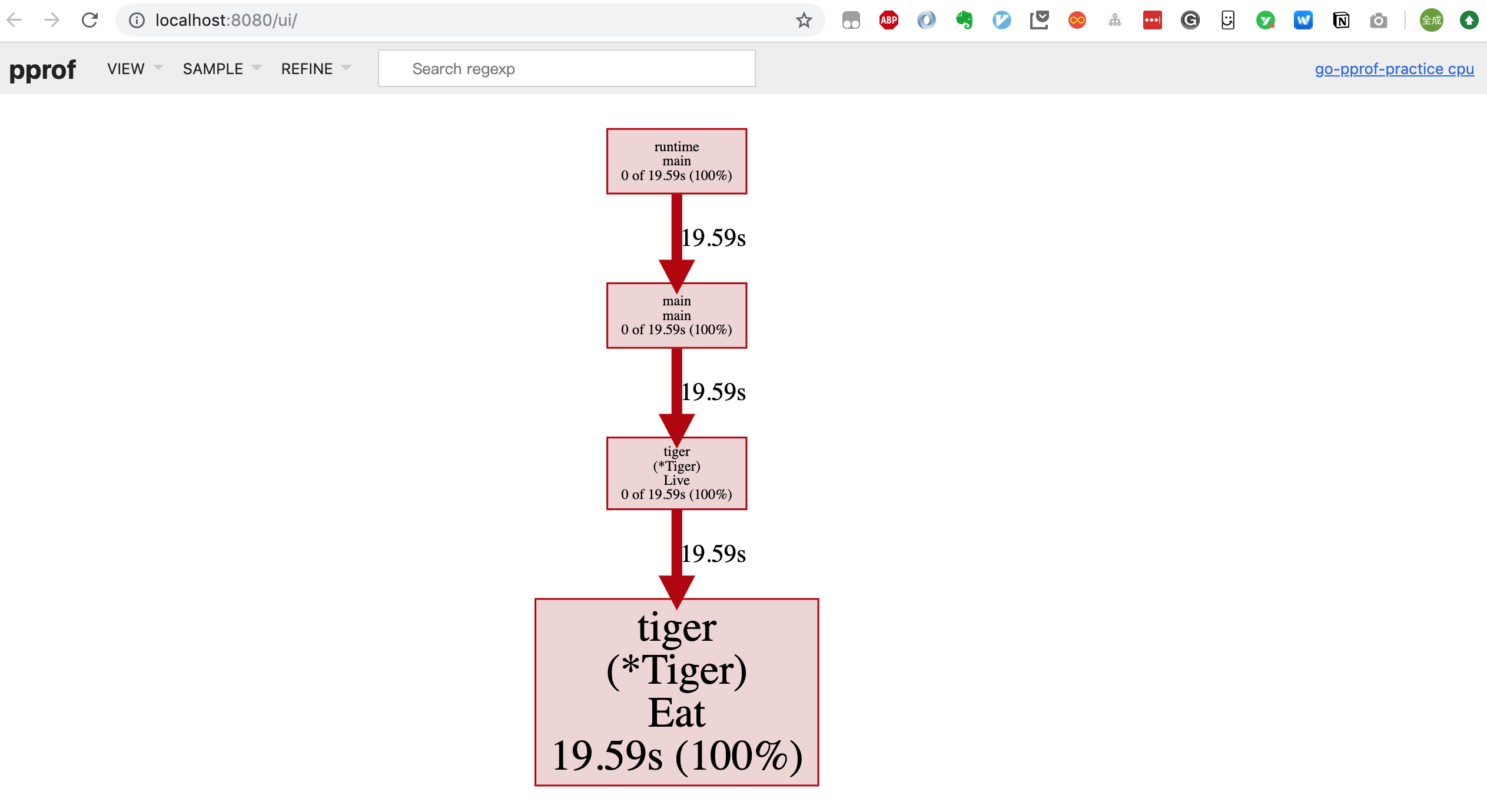
点击菜单栏可以在:Top/Graph/Peek/Source 之间进行切换,甚至可以看到火焰图(Flame Graph):
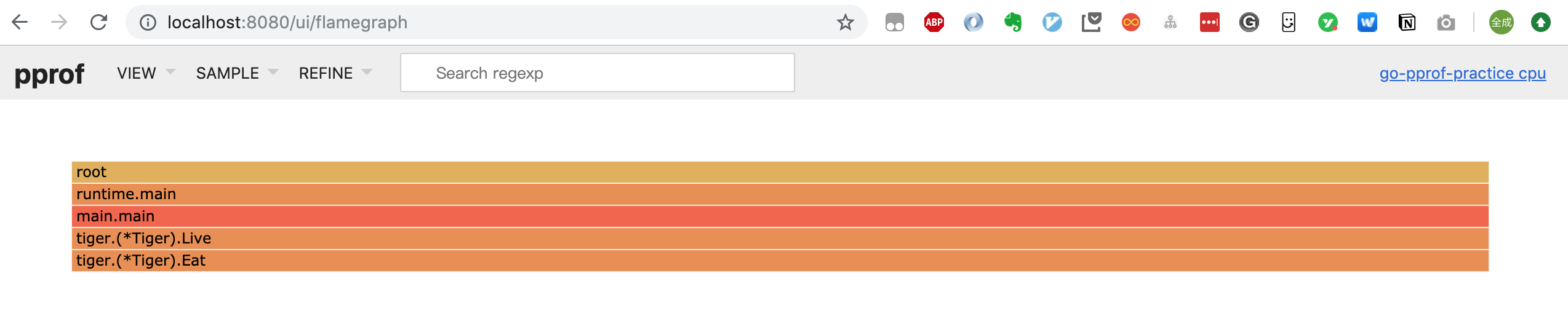
它和一般的火焰图相比刚好倒过来了,调用关系的展现是从上到下。形状越长,表示执行时间越长。注:我这里使用的 go 版本是 1.13,更老一些的版本 pprof 工具不支持 -http 的参数。当然也可以下载其他的库查看火焰图,例如:
go get -u github.com/google/pprof
或者
go get github.com/uber/go-torch
pprof 进阶
我在参考资料部分给出了一些使用 pprof 工具进行性能分析的实战文章,可以跟着动手实践一下,之后再用到自己的平时工作中。
Russ Cox 实战
这部分主要内容来自参考资料【Ross Cox】,学习一下大牛的优化思路。
事情的起因是这样的,有人发表了一篇文章,用各种语言实现了一个算法,结果用 go 写的程序非常慢,而 C++ 则最快。然后 Russ Cox 就鸣不平了,哪受得了这个气?马上启用 pprof 大杀器进行优化。最后,程序不仅更快,而且使用的内存更少了!
首先,增加 cpu profiling 的代码:
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file")
func main() {
flag.Parse()
if *cpuprofile != "" {
f, err := os.Create(*cpuprofile)
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
}
...
}
使用 pprof 观察耗时 top5 的函数,发现一个读 map 的函数耗时最长:mapaccess1_fast64,而它出现在一个递归函数中。

一眼就能看到框最大的 mapacess1_fast64 函数。执行 web mapaccess1 命令,更聚焦一些:

调用 mapaccess1_fast64 函数最多的就是 main.FindLoops 和 main.DFS,是时候定位到具体的代码了,执行命令:list DFS,定位到相关的代码。
优化的方法是将 map 改成 slice,能这样做的原因当然和 key 的类型是 int 而且不是太稀疏有关。
The take away will be that for smaller data sets, you shouldn’t use maps where slices would suffice, as maps have a large overhead.
修改完之后,再次通过 cpu profiling,发现递归函数的耗时已经不在 top5 中了。但是新增了长耗时函数:runtime.mallocgc,占比 54.2%,而这和分存分配以及垃圾回收相关。
下一步,增加采集内存数据的代码:
var memprofile = flag.String("memprofile", "", "write memory profile to this file")
func main() {
// …………
FindHavlakLoops(cfgraph, lsgraph)
if *memprofile != "" {
f, err := os.Create(*memprofile)
if err != nil {
log.Fatal(err)
}
pprof.WriteHeapProfile(f)
f.Close()
return
}
// …………
}
继续通过 top5、list 命令找到内存分配最多的代码位置,发现这回是向 map 里插入元素使用的内存比较多。改进方式同样是用 slice 代替 map,但 map 还有一个特点是可以重复插入元素,因此新写了一个向 slice 插入元素的函数:
func appendUnique(a []int, x int) []int {
for _, y := range a {
if x == y {
return a
}
}
return append(a, x)
}
好了,现在程序比最初的时候快了 2.1 倍。再次查看 cpu profile 数据,发现 runtime.mallocgc 降了一些,但仍然占比 50.9%。
Another way to look at why the system is garbage collecting is to look at the allocations that are causing the collections, the ones that spend most of the time in mallocgc.
因此需要查看垃圾回收到底在回收哪些内容,这些内容就是导致频繁垃圾回收的“罪魁祸首”。
使用 web mallocgc 命令,将和 mallocgc 相关的函数用矢量图的方式展现出来,但是有太多样本量很少的节点影响观察,增加过滤命令:
go tool pprof --nodefraction=0.1 profile

将少于 10% 的采样点过滤掉,新的矢量图可以直观地看出,FindLoops 触发了最多的垃圾回收操作。继续使用命令 list FindLoops 直接找到代码的位置。
原来,每次执行 FindLoops 函数时,都要 make 一些临时变量,这会加重垃圾回收器的负担。改进方式是增加一个全局变量 cache,可以重复利用。坏处是,现在不是线程安全的了。
使用 pprof 工具进行的优化到这就结束了。最后的结果很不错,基本上能达到和 C++ 同等的速度和同等的内存分配大小。
我们能得到的启发就是先使用 cpu profile 找出耗时最多的函数,进行优化。如果发现 gc 执行比较多的时候,找出内存分配最多的代码以及引发内存分配的函数,进行优化。
原文很精彩,虽然写作时间比较久远(最初写于 2011 年)了,但仍然值得一看。另外,参考资料【wolfogre】的实战文章也非常精彩,而且用的招式和这篇文章差不多,但是你可以运行文章提供的样例程序,一步步地解决性能问题,很有意思!
查找内存泄露
内存分配既可以发生在堆上也可以在栈上。堆上分配的内存需要垃圾回收或者手动回收(对于没有垃圾回收的语言,例如 C++),栈上的内存则通常在函数退出后自动释放。
Go 语言通过逃逸分析会将尽可能多的对象分配到栈上,以使程序可以运行地更快。
这里说明一下,有两种内存分析策略:一种是当前的(这一次采集)内存或对象的分配,称为 inuse;另一种是从程序运行到现在所有的内存分配,不管是否已经被 gc 过了,称为 alloc。
As mentioned above, there are two main memory analysis strategies with pprof. One is around looking at the current allocations (bytes or object count), called inuse. The other is looking at all the allocated bytes or object count throughout the run-time of the program, called alloc. This means regardless if it was gc-ed, a summation of everything sampled.
加上 -sample_index 参数后,可以切换内存分析的类型:
go tool pprof -sample_index=alloc_space http://47.93.238.9:8080/debug/pprof/heap
共有 4 种:
| 类型 | 含义 |
|---|---|
| inuse_space | amount of memory allocated and not released yet |
| inuse_objects | amount of objects allocated and not released yet |
| alloc_space | total amount of memory allocated (regardless of released) |
| alloc_objects | total amount of objects allocated (regardless of released) |
参考资料【大彬 实战内存泄露】讲述了如何通过类似于 diff 的方式找到前后两个时刻多出的 goroutine,进而找到 goroutine 泄露的原因,并没有直接使用 heap 或者 goroutine 的 profile 文件。同样推荐阅读!
总结
pprof 是进行 Go 程序性能分析的有力工具,它通过采样、收集运行中的 Go 程序性能相关的数据,生成 profile 文件。之后,提供三种不同的展现形式,让我们能更直观地看到相关的性能数据。
得到性能数据后,可以使用 top、web、list等命令迅速定位到相应的代码处,并进行优化。
“过早的优化是万恶之源”。实际工作中,很少有人会关注性能,但当你写出的程序存在性能瓶颈,qa 压测时,qps 上不去,为了展示一下技术实力,还是要通过 pprof 观察性能瓶颈,进行相应的性能优化。
参考资料
【Russ Cox 优化过程,并附上代码】https://blog.golang.org/profiling-go-programs
【google pprof】https://github.com/google/pprof
【使用 pprof 和火焰图调试 golang 应用】https://cizixs.com/2017/09/11/profiling-golang-program/
【资源合集】https://jvns.ca/blog/2017/09/24/profiling-go-with-pprof/
【Profiling your Golang app in 3 steps】https://coder.today/tech/2018-11-10_profiling-your-golang-app-in-3-steps/
【案例,压测 Golang remote profiling and flamegraphs】https://matoski.com/article/golang-profiling-flamegraphs/
【煎鱼 pprof】https://segmentfault.com/a/1190000016412013
【鸟窝 pprof】https://colobu.com/2017/03/02/a-short-survey-of-golang-pprof/
【关于 Go 的 7 种性能分析方法】https://blog.lab99.org/post/golang-2017-10-20-video-seven-ways-to-profile-go-apps.html
【pprof 比较全】https://juejin.im/entry/5ac9cf3a518825556534c76e
【通过实例来讲解分析、优化过程】https://artem.krylysov.com/blog/2017/03/13/profiling-and-optimizing-go-web-applications/
【Go 作者 Dmitry Vyukov】https://github.com/golang/go/wiki/Performance
【wolfogre 非常精彩的实战文章】https://blog.wolfogre.com/posts/go-ppof-practice/
【dave.cheney】https://dave.cheney.net/high-performance-go-workshop/dotgo-paris.html
【实战案例】https://www.cnblogs.com/sunsky303/p/11058808.html
【大彬 实战内存泄露】https://segmentfault.com/a/1190000019222661
【雷神 3 性能优化】https://diducoder.com/sotry-about-sqrt.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号