
数据库优化
文章来源: https://www.cnblogs.com/easypass/archive/2010/12/08/1900127.html
MySQL/Oracle数据库优化总结(非常全面):https://blog.csdn.net/baidu_37107022/article/details/77460464
以上链接有对于数据库优化的详细内容,个人认为写的相当详细,但是由于本人并不能全都理解,以下是自己看完之后作的总结。
1、 查询时的优化:
在能够保证数据的完整性是尽量减少表之间的关联,去除外键!注意where查询条件后的顺序,先过滤有索引的,能尽量缩小数据范围
2、 合理创建索引,索引优化:
合理分析并设置,调整索引

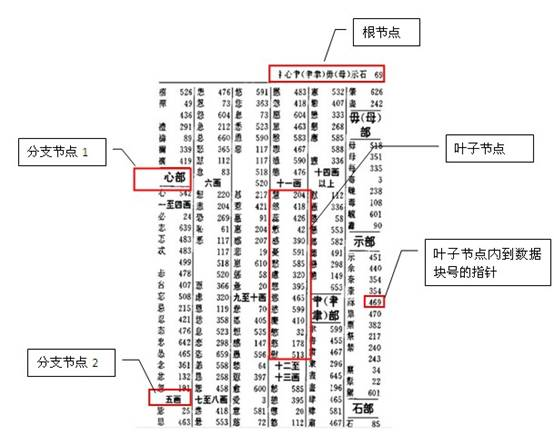
图中是一个字典按部首+笔划数的目录,相当于给字典建了一个按部首+笔划的组合索引。
一个表中可以建多个索引,就如一本字典可以建多个目录一样(按拼音、笔划、部首等等)。
一个索引也可以由多个字段组成,称为组合索引,如上图就是一个按部首+笔划的组合目录。
3、只通过索引访问数据
有些时候,我们只是访问表中的几个字段,并且字段内容较少,我们可以为这几个字段单独建立一个组合索引,这样就可以直接只通过访问索引就能得到数据,一般索引占用的磁盘空间比表小很多,所以这种方式可以大大减少磁盘IO开销。
如:select id,name from company where type='2';
如果这个SQL经常使用,我们可以在type,id,name上创建组合索引
create index my_comb_index on company(type,id,name);
有了这个组合索引后,SQL就可以直接通过my_comb_index索引返回数据,不需要访问company表。
还是拿字典举例:有一个需求,需要查询一本汉语字典中所有汉字的个数,如果我们的字典没有目录索引,那我们只能从字典内容里一个一个字计数,最后返回结果。如果我们有一个拼音目录,那就可以只访问拼音目录的汉字进行计数。如果一本字典有1000页,拼音目录有20页,那我们的数据访问成本相当于全表访问的50分之一。
4、表结构优化:
如果数据量过多的话,可以将表拆分开来,分类进行拆分,比如,男职员一张表,女职员一张表等等;
5、用prepareStatement对sql语句进行预处理防止注入
6、返回更少的数据
(1)数据分页处理。数据库中rownum进行分页;应用服务器分页;
(2)只返回需要的数据,查询语句不要用 * 代替需要的字段
7、减少数据交互
(1)通过jdbc的batch进行提交。批量处理!比如一共提交1000次的数据,可以100条提交一次,这样只需要提交十次即可。减少了与数据库的交互。
(2)当我们采用select从数据库查询数据时,数据默认并不是一条一条返回给客户端的,也不是一次全部返回客户端的,而是根据客户端fetch_size参数处理,每次只返回fetch_size条记录,当客户端游标遍历到尾部时再从服务端取数据,直到最后全部传送完成。所以如果我们要从服务端一次取大量数据时,可以加大fetch_size,这样可以减少结果数据传输的交互次数及服务器数据准备时间,提高性能。
8、减少比较操作,模糊查询
(1)减少比较操作,如>,<,!=等等;
(2)减少模糊查询,如like,%等等;

