语音识别中的CTC算法的基本原理解释
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
本文作者:罗冬日
目前主流的语音识别都大致分为特征提取,声学模型,语音模型几个部分。目前结合神经网络的端到端的声学模型训练方法主要CTC和基于Attention两种。
本文主要介绍CTC算法的基本概念,可能应用的领域,以及在结合神经网络进行CTC算法的计算细节。
CTC算法概念
CTC算法全称叫:Connectionist temporal classification。从字面上理解它是用来解决时序类数据的分类问题。
传统的语音识别的声学模型训练,对于每一帧的数据,需要知道对应的label才能进行有效的训练,在训练数据之前需要做语音对齐的预处理。而语音对齐的过程本身就需要进行反复多次的迭代,来确保对齐更准确,这本身就是一个比较耗时的工作。
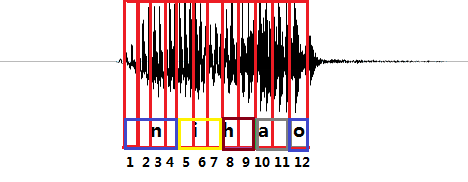
上图是“你好”这句话的声音的波形示意图, 每个红色的框代表一帧数据,传统的方法需要知道每一帧的数据是对应哪个发音音素。比如第1,2,3,4帧对应n的发音,第5,6,7帧对应i的音素,第8,9帧对应h的音素,第10,11帧对应a的音素,第12帧对应o的音素。(这里暂且将每个字母作为一个发音音素)
与传统的声学模型训练相比,采用CTC作为损失函数的声学模型训练,是一种完全端到端的声学模型训练,不需要预先对数据做对齐,只需要一个输入序列和一个输出序列即可以训练。这样就不需要对数据对齐和一一标注,并且CTC直接输出序列预测的概率,不需要外部的后处理。
既然CTC的方法是关心一个输入序列到一个输出序列的结果,那么它只会关心预测输出的序列是否和真实的序列是否接近(相同),而不会关心预测输出序列中每个结果在时间点上是否和输入的序列正好对齐。
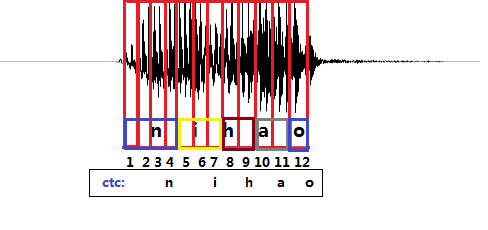
CTC引入了blank(该帧没有预测值),每个预测的分类对应的一整段语音中的一个spike(尖峰),其他不是尖峰的位置认为是blank。对于一段语音,CTC最后的输出是spike(尖峰)的序列,并不关心每一个音素持续了多长时间。
如图2所示,拿前面的nihao的发音为例,进过CTC预测的序列结果在时间上可能会稍微延迟于真实发音对应的时间点,其他时间点都会被标记会blank。
这种神经网络+CTC的结构除了可以应用到语音识别的声学模型训练上以外,也可以用到任何一个输入序列到一个输出序列的训练上(要求:输入序列的长度大于输出序列)。
比如,OCR识别也可以采用RNN+CTC的模型来做,将包含文字的图片每一列的数据作为一个序列输入给RNN+CTC模型,输出是对应的汉字,因为要好多列才组成一个汉字,所以输入的序列的长度远大于输出序列的长度。而且这种实现方式的OCR识别,也不需要事先准确的检测到文字的位置,只要这个序列中包含这些文字就好了。
RNN+CTC模型的训练
下面介绍在语音识别中,RNN+CTC模型的训练详细过程,到底RNN+CTC是如何不用事先对齐数据来训练序列数据的。
首先,CTC是一种损失函数,它用来衡量输入的序列数据经过神经网络之后,和真实的输出相差有多少。
比如输入一个200帧的音频数据,真实的输出是长度为5的结果。 经过神经网络处理之后,出来的还是序列长度是200的数据。比如有两个人都说了一句nihao这句话,他们的真实输出结果都是nihao这5个有序的音素,但是因为每个人的发音特点不一样,比如,有的人说的快有的人说的慢,原始的音频数据在经过神经网络计算之后,第一个人得到的结果可能是:nnnniiiiii...hhhhhaaaaaooo(长度是200),第二个人说的话得到的结果可能是:niiiiii...hhhhhaaaaaooo(长度是200)。这两种结果都是属于正确的计算结果,可以想象,长度为200的数据,最后可以对应上nihao这个发音顺序的结果是非常多的。CTC就是用在这种序列有多种可能性的情况下,计算和最后真实序列值的损失值的方法。
详细描述如下:
训练集合为\(S=\lbrace (x^1,z^1), (x^2, z^2), ...(x^N,z^N) \rbrace\), 表示有\(N\)个训练样本,\(x\)是输入样本,\(z\)是对应的真实输出的label。一个样本的输入是一个序列,输出的label也是一个序列,输入的序列长度大于输出的序列长度。
对于其中一个样本\((x,z)\),\(x=(x_1,x_2,x_3,...,x_T)\)表示一个长度为T帧的数据,每一帧的数据是一个维度为m的向量,即每个\(x_i \in R^m\)。 \(x_i\)可以理解为对于一段语音,每25ms作为一帧,其中第\(i\)帧的数据经过MFCC计算后得到的结果。
\(z=(z_1,z_2, z_3,...z_U)\)表示这段样本语音对应的正确的音素。比如,一段发音“你好”的声音,经过MFCC计算后,得到特征\(x\), 它的文本信息是“你好”,对应的音素信息是\(z=[n,i,h,a,o]\)(这里暂且将每个拼音的字母当做一个音素)。
特征\(x\)在经过RNN的计算之后,在经过一个\(softmax\)层,得到音素的后验概率\(y\)。 \(y^t_k(k=1, 2,3,...n,t=1,2,3,...,T)\)表示在\(t\)时刻,发音为音素\(k\)的概率,其中音素的种类个数一共\(n\)个, \(k\)表示第\(k\)个音素,在一帧的数据上所有的音素概率加起来为1。即:
\(\sum_{t-1}^{T}y^t_k=1, y^t_k\geq0\)
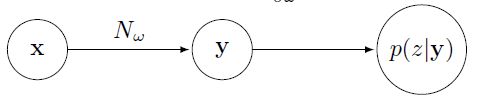
这个过程可以看做是对输入的特征数据\(x\)做了变换\(N_w\):\((R^m)^T \rightarrow (R^n)^T\),其中\(N_w\)表示RNN的变换,\(w\)表示RNN中的参数集合。
过程入下图所示:

以一段“你好”的语音为例,经过MFCC特征提取后产生了30帧,每帧含有12个特征,即\(x \in R^{30\times14}\)(这里以14个音素为例,实际上音素有200个左右),矩阵里的每一列之和为1。后面的基于CTC-loss的训练就是基于后验概率\(y\)计算得到的。
路径π和B变换
在实际训练中并不知道每一帧对应的音素,因此进行训练比较困难。可以先考虑一种简单的情况,已知每一帧的音素的标签\(z\prime\), 即训练样本为\(x\)和\(z\prime\),其中\(z\prime\)不再是简单的\([n,i,h,a,o]\)标签,而是:
\(z\prime = [\underbrace{n,n,n,...,n}_{T_1},\underbrace{i,i,i,...i}_{T_2},\underbrace{h,h,h,...h}_{T_3},\underbrace{a,a,a,...,a}_{T_4},\underbrace{o,o,o,...,o}_{T_5}]\)
$ T_1+T_2+T_3+T_4+T_5 = T $
在我们的例子中, \(z\prime =[n,n,n,n,n,n,n,i,i,i,i,i,i,h,h,h,h,h,h,h,a,a,a,a,a,a,o,o,o,o,o,o,o]\), $z\prime \(包含了每一帧的标签。在这种情况下有:
\)p(z\prime|x) = p(z\prime| y = N_w(x)) = y1_{z\prime_1}y2_{z\prime_2}y3_{z\prime_3}....yT_{z\prime_T}$ \(\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\) (1)
该值即为后验概率图中用黑线圈起来的部分相乘。我们希望相乘的值越大越好,因此,数学规划可以写为:
\(min_w -log(y^1_{z^\prime_1}.y^2_{z^\prime_2}.y^3_{z^\prime_3}...y^T_{z^\prime_T})\) \(\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\) (2)
subject to: $ y = N_w(x) $$\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad$ (3)
目标函数对于后验概率矩阵\(y\)中的每个元素\(y^t_k\)的偏导数为:
$\frac{\partial - log(y1_{z\prime_1}.y2_{z\prime_2}.y3_{z\prime_3}...yT_{z\prime_T})}{\partial y^t_k} = $$\begin{cases} -\frac{y1_{z\prime_1}...y{z\prime{i-1}}.y{i+1}_{z\prime_{i+1}}....yT_{z\prime_T}}{y1_{z\prime_1}.y2_{z\prime_2}.y3_{z\prime_3}...yT_{z\prime_T}} , \qquad if \qquad k = z\prime_i \qquad and \qquad t=i \ 0 \qquad 其他\end{cases}$
也就是说,在每个时刻\(t\)(对应矩阵的一列),目标只与\(y^t_{z\prime_t}\)是相关的,在这个例子中是与被框起来的元素相关。
其中\(N_w\)可以看做是RNN模型,如果训练数据的每一帧都标记了正确的音素,那么训练过程就很简单了,但实际上这样的标记过的数据非常稀少,而没有逐帧标记的数据很多,CTC可以做到用未逐帧标记的数据做训练。
首先定义几个符号:
\(L=\lbrace a, o, e, i, u, \check{u},b,p,m,...\rbrace\)
表示所有音素的集合
\(\pi= (\pi_1, \pi_2, \pi_3, ..., \pi_T), \pi_i \in L\)
表示一条由\(L\)中元素组成的长度为\(T\)的路径,比如\(z\prime\)就是一条路径,以下为几个路径的例子:
\(\pi^1= (j,j,i,n,y,y,e,e,w,w,u,u,u,r,r,e,e,n,n,r,r,u,u,sh,sh,u,u,i,i)\)
\(\pi^2= (n,n,n,n,i,i,i,i,h,h,h,h,a,a,a,a,a,a,a,a,a,o,o,o,o,o,o,o,o,o)\)
\(\pi^3= (h,h,h,h,h,h,a,a,a,a,a,a,a,o,o,o,o,n,n,n,n,n,n,i,i,i,i,i,i,i)\)
\(\pi^4= (n,i,h,a,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o)\)
\(\pi^5= (n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,i,h,a,o)\)
\(\pi^6= (n,n,n,i,i,i,h,h,h,h,h,a,,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o,o)\)
这6条路径中,\(\pi^1\)可以被认为是“今夜无人入睡”, \(\pi^2\)可以被认为是在说“你好”,\(\pi^3\)可以被认为是在说“好你”,\(\pi4,\pi5,\pi6\)都可以认为是在说“你好”。
定义B变换,表示简单的压缩,例如:
\(B(a,a,a,b,b,b,c,c,d) = (a,b,c,d)\)
以上6条路径为例:
\(B(\pi^1) = (j,i,n,y,e,w,u,r,e,n,r,u,s,h,u,i)\)
\(B(\pi^2) = (n,i,h,a,)\)
\(B(\pi^3) = (h,a,o,n,i)\)
\(B(\pi^4) = (n,i,h,a,o)\)
\(B(\pi^5) = (n,i,h,a,o)\)
\(B(\pi^6) = (n,i,h,a,o)\)
因此,如果有一条路径\(\pi\)有\(B(\pi)=(n,i,h,a,o)\),则可以认为\(\pi\)是在说“你好”。即使它是如\(\pi^4\)所示,有很多“o”的音素,而其他音素很少。路径\(\pi = (\pi^1,\pi^2,...,\pi^T)\)的概率为它所经过的矩阵y上的元素相乘:
\(p(\pi|x) = p(\pi| y = N_w(x)) = p(\pi| y)=\prod_{t=1}^{T} y^t_{\pi_t}\)
因此在没有对齐的情况下,目标函数应该为\(\lbrace \pi | B(\pi) = z \rbrace\)中所有元素概率之和。 即:
\(max_w p(z|y=N_w(x)) = p(z|x)= \sum_{B(\pi)=z}p(\pi|x)\) \(\qquad\qquad\qquad\) (4)
在T=30,音素为\([n,i,h,a,o]\)的情况下,共有\(C^5_{29}\approx120000\)条路径可以被压缩为\([n,i,h,a,o]\)。 路径数目的计算公式为\(C^{音素个数}_{T-1}\),量级大约为\((T-1)^{音素个数}\)。一段30秒包含50个汉字的语音,其可能的路径数目可以高达\(10^8\),显然这么大的路径数目是无法直接计算的。因此CTC方法中借用了HMM中的向前向后算法来计算。
训练实施方法
CTC的训练过程是通过$\frac {\partial p(z|x)}{\partial w} $调整w的值使得4中的目标值最大,而计算的过程如下:
因此,只要得到$\frac {\partial p(z|x)}{\partial y^t_k} \(,即可根据反向传播,得到\)\frac {\partial p(z|x)}{\partial w} $。下面以“你好”为例,介绍该值的计算方法。
首先,根据前面的例子,找到所有可能被压缩为\(z=[n,i,h,a,o]\)的路径,记为\(\lbrace \pi|B(\pi) = z \rbrace\)。 可知所有\(\pi\)均有\([n,n,n,....,n,i,.....,i,h,.....h,a,....a,o,...,o]\)的形式,即目标函数只与后验概率矩阵y中表示\(n,i,h,a,o\)的5行相关,因此为了简便,我们将这5行提取出来,如下图所示。
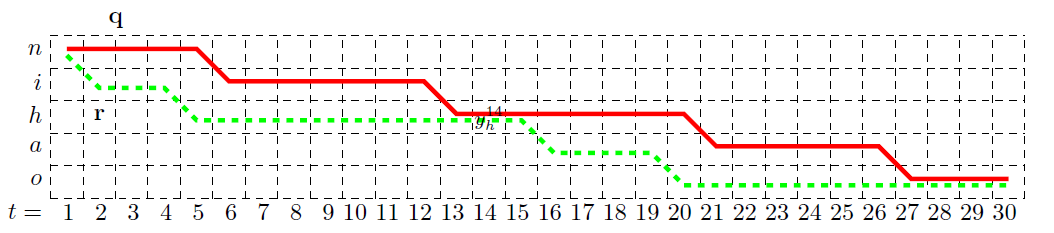
在每一个点上,路径只能向右或者向下转移,画出两条路径,分别用q和r表示,这两条路径都经过\(y^{14}_h\)这点,表示这两点路径均在第14帧的时候在发“h”音。因为在目标函数4的连加项中,有的项与\(y^{14}_h\)无关,因此可以剔除这一部分,只留下与\(y^{14}_h\)有关的部分,记为\(\lbrace \pi|B(\pi) = z, \pi_{14}=h \rbrace\)
$\frac {\partial p(z|y)}{\partial y^{14}_h} $
= $\frac {\partial \sum_{B(\pi)=z}p(\pi|y)}{\partial y^{14}_h} $
= $\frac {\partial \sum_{B(\pi)=z}\prod_{t=1}^T y^t_{\pi_t}}{\partial y^{14}h} \( =\)\frac {\overbrace{\partial \sum=h}\prod_{t=1}^T yt_{\pi_t}}h有关的项} + \overbrace{\partial \sum \neq h}\prod_{t=1}^T yt_{\pi_t}}_h无关的项}}{\partial y^{14}_h}$
=\(\frac {\partial \sum_{B(\pi)=z,\pi_{14}=h}\prod_{t=1}^T y^t_{\pi_t}}{\partial y^{14}_h}\)
这里的q和r就是与\(y^{14}_h\)相关的两条路径。用\(q_{1:13}\)和\(q_{15:30}\)分别表示\(q\)在\(y^{14}_h\)之前和之后的部分,同样的,用\(r_{1:13}\)和\(r_{15:30}\)分别表示\(r\)在\(y^{14}_h\)之前和之后的部分.。可以发现,\(q_{1:13} + h + r_{15:30}\)与\(r_{1:13} + h + q_{15:30}\)同样也是两条可行的路径。\(q_{1:13} + h + r_{15:30}\)、\(r_{1:13} + h + q_{15:30}\)、\(q\) 、\(r\)这四条路径的概率之和为:
\(\underbrace{y^1_{q1}..y^{13}_{q13}.y^{14}_{h}.y^{15}_{q15}....y^{30}_{q30}}_{路径q的概率}\)
+\(\underbrace{y^1_{q1}..y^{13}_{q13}.y^{14}_{h}.y^{15}_{r15}....y^{30}_{r30}}_{路径q_{1:14}+r_{14:30}的概率}\)
+\(\underbrace{y^1_{r1}..y^{13}_{r13}.y^{14}_{h}.y^{15}_{q15}....y^{30}_{q30}}_{路径r_{1:14}+q_{14:30}的概率}\)
+\(\underbrace{y^1_{r1}..y^{13}_{r13}.y^{14}_{h}.y^{15}_{r15}....y^{30}_{r30}}_{路径r的概率}\)
=\((y^1_{q1}....y^{13}_{q13} + y^1_{r1}.....y^{13}_{r13}).y^{14}_h.(y^{15}_{q15}....y^{30}_{q15}+y^{15}_{r15}....y^{30}_{r30})\)
可以发现,该值可以总结为:(前置项)\(.y^{14}_h.\)(后置项)。由此,对于所有的经过\(y^{14}_h\)的路径,有:
\(\sum_{B(\pi)=z,\pi_{14}=h}\prod_{t=1}^T y^t_{\pi_t}= (前置项).y^{14}_h.\)(后置项)$
定义:
$\alpha_(14)(h)=(前置项).y^{14}h = \sum)=[n,i,h] }\prod_{t\prime=1}^t y^{t\prime}{\pi{t\prime}} $
该值可以理解为从初始到\(y^{14}_h\)这一段里,所有正向路径的概率之和。并且发现,\(\alpha_{14}(h)\)可以由\(\alpha_{13}(h)\)和\(\alpha_{13}(i)\)递推得到,即:
\(\alpha_{14}(h) = (\alpha_{13}(h) + \alpha_{13}(i))y^{14}_h\)
该递推公式的含义是,只是在\(t=13\)时发音是“h”或“i”,在\(t=14\)时才有可能发音是“h”。那么在\(t=14\)时刻发音是“h”的所有正向路径概率\(\alpha_{14}(h)\)就等于在\(t=13\)时刻,发音为“h”的正向概率\(\alpha_{13}(h)\)加上发音为“i”的正向概率\(\alpha_{13}(i)\),再乘以当前音素被判断为“h”的概率\(y^{14}_h\)。由此可知,每个\(\alpha_t(s)\)都可以由\(\alpha_{t-1}(s)\)和\(\alpha_{t-1}(s-1)\)两个值得到。\(\alpha\)的递推流程如下图所示:
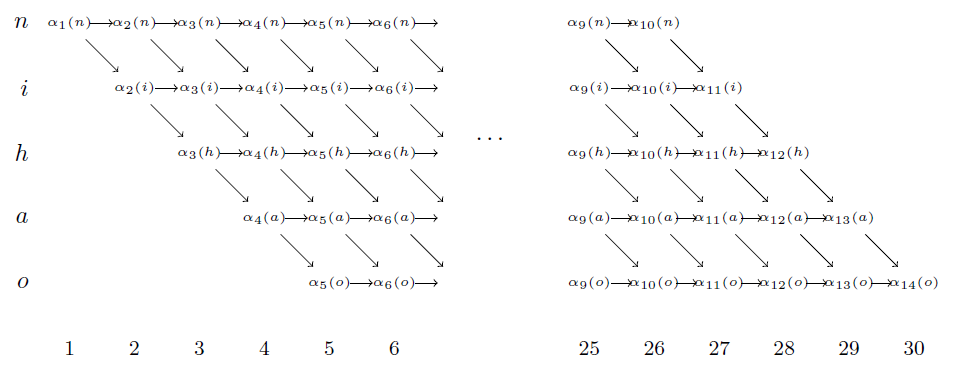
即每个值都由上一个时刻的一个或者两个值得到,总计算量大约为\(2.T.音素个数\)。类似的,定义\(\beta_t(s)\), 递推公式为:
\(\beta_{14}(h)=(\beta_{15}(h) + \beta_{15}(a))y^{14}_h\)
因此有:
\(\sum_{B(\pi)=z,\pi_{14}=h}\prod_{t=1}^T y^t_{\pi_t}= (前置项).y^{14}_h.\)(后置项)$
=\(\frac{\alpha_{14}(h)}{y^{14}_h}. y^{14}_h.\frac{\beta_{14}(h)}{y^{14}_h}\)
=\(\frac{\alpha_{14}(h)\beta_{14}(h)}{y^{14}_h}\)
然后:
$\frac {\partial p(z|y)}{\partial y^{14}_h} $
= \(\frac {\sum_{B(\pi)=z,\pi_{14}=h}\prod_{t=1}^T y^t_{\pi_t}}{\partial y^{14}_h}\)
= \(\frac {\frac{\alpha_{14}(h)}{y^{14}_h}. y^{14}_h.\frac{\beta_{14}(h)}{y^{14}_h}}{\partial y^{14}_h}\)
=\(\frac{\alpha_{14}(h)\beta_{14}(h)}{{(y^{14}_h)}^2}\)
得到此值后,就可以根据反向传播算法进行训练了。
可以看到,这里总的计算量非常小,计算\(\alpha\)和\(\beta\)的计算量均大约为\((2.T.音素个数)\),(加法乘法各一次),得到\(\alpha\)和\(\beta\)之后,在计算对每个\(y^t_k\)的偏导值的计算量为\((3.T.音素个数)\),因此总计算量大约为\((7.T.音素个数)\),这是非常小的,便于计算。
目前,深度学习的算法已经大规模应用于腾讯云的语音识别产品中。腾讯云拥有业内最先进的语音识别技术,基于海量的语音数据,积累了数十万小时的标注语音数据,采用LSTM,CNN,LFMMI,CTC等多种建模技术,结合超大规模语料的语言模型,对标准普通话的识别效果超过了97%的准确率。腾讯云的语音技术,应用涵盖范围广泛,具备出色的语音识别、语音合成、关键词检索、静音检测、语速检测、情绪识别等能力。并且针对游戏,娱乐,政务等几十个垂直做特殊定制的语音识别方案,让语音识别的效果更精准,更高效,全面满足电话客服质检、语音听写、实时语音识别和直播字幕等多种场景的应用。想试用相关产品吗?请猛戳:cloud.tencent.com/product/asr
问答
语音识别API如何调用?
相关阅读
智能机器人语音识别技术
python语音识别终极指南
tensorflow LSTM +CTC实现端到端OCR
此文已由作者授权腾讯云+社区发布,原文链接:https://cloud.tencent.com/developer/article/1122128?fromSource=waitui


 浙公网安备 33010602011771号
浙公网安备 33010602011771号