轻松入门机器学习之概念总结(二)
欢迎大家前往云加社区,获取更多腾讯海量技术实践干货哦~
作者:许敏
接上篇:机器学习概念总结笔记(一)
8)逻辑回归
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。因此因变量就为是否胃癌,值为“是”或“否”,自变量就可以包括很多了,如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。然后通过logistic回归分析,可以得到自变量的权重,从而可以大致了解到底哪些因素是胃癌的危险因素。同时根据该权值可以根据危险因素预测一个人患癌症的可能性。
考虑具有p个独立变量的向量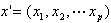 ,设条件概率
,设条件概率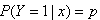 为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为:
为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为: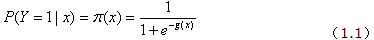
上式右侧形式的函数称为逻辑函数。下图给出其函数图象形式。
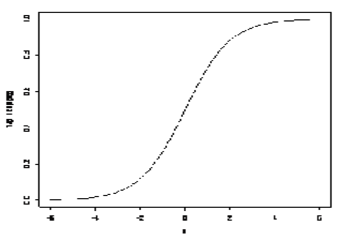
其中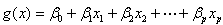 。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有
。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有
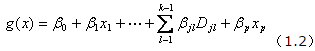
定义不发生事件的条件概率为
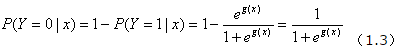
那么,事件发生与事件不发生的概率之比为

这个比值称为事件的发生比(the odds of experiencing an event),简称为odds。因为0<p<1,故odds>0。对odds取对数,即得到线性函数
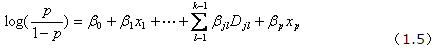
假设有n个观测样本,观测值分别为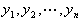 。设
。设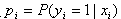 为给定条件下得到yi=1(原文
为给定条件下得到yi=1(原文 )的概率。在同样条件下得到yi=0(
)的概率。在同样条件下得到yi=0(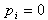 )的条件概率为
)的条件概率为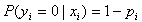 。于是,得到一个观测值的概率为
。于是,得到一个观测值的概率为

因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。
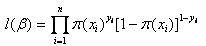
上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估计。于是,最大似然估计的关键就是求出参数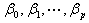 ,使上式取得最大值。对上述函数求对数
,使上式取得最大值。对上述函数求对数
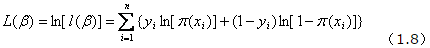
上式称为对数似然函数。为了估计能使取得最大的参数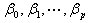 的值。
的值。
对此函数求导,得到p+1个似然方程。
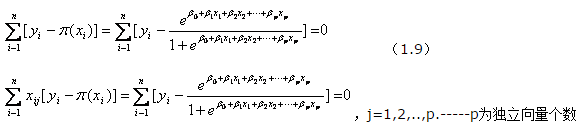
上式称为似然方程。为了解上述非线性方程,应用牛顿-拉斐森(Newton-Raphson)方法进行迭代求解。
9)贝叶斯分类
贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。先验概率(prior probability)是指根据以往经验和分析得到的概率,如全概率公式,它往往作为"由因求果"问题中的"因"出现的概率·。后验概率是指在得到“结果”的信息后重新修正的概率,如贝叶斯公式中的。是“执果寻因”问题中的"果"。先验概率与后验概率有不可分割的联系,后验概率的计算要以先验概率为基础。后验概率实际上就是条件概率。目前研究较多的贝叶斯分类器主要有四种,分别是:NB、TAN、BAN和GBN。
朴素贝叶斯分类器(Naive Bayes Classifier,或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。左图是朴素贝叶斯网络,BCD之间独立,右图表示一般贝叶斯网络,BCD之间存在关联关系。贝叶斯网络不可成环。
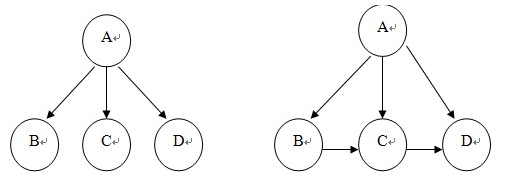
TAN(Tree Augmented Naive Bayes, TAN 增强树贝叶斯分类器),TAN算法通过发现属性对之间的依赖关系来降低NB中任意属性之间独立的假设。它是在NB网络结构的基础上增加属性对之间的关联(边)来实现的。实现方法是:用结点表示属性,用有向边表示属性之间的依赖关系,把类别属性作为根结点,其余所有属性都作为它的子节点。通常,用虚线代表NB所需的边,用实线代表新增的边。属性Ai与Aj之间的边意味着属性Ai对类别变量C的影响还取决于属性Aj的取值。这些增加的边需满足下列条件:类别变量没有双亲结点,每个属性有一个类别变量双亲结点和最多另外一个属性作为其双亲结点。找到这组关联边之后,就可以计算一组随机变量的联合概率分布如下:其中ΠAi代表的是Ai的双亲结点。由于在TAN算法中考虑了n个属性中(n-1)个两两属性之间的关联性,该算法对属性之间独立性的假设有了一定程度的降低,但是属性之间可能存在更多其它的关联性仍没有考虑,因此其适用范围仍然受到限制。
BAN(BN Augmented Naive Bayes, BAN)分类器进一步扩展TAN分类器,允许各特征结点之间的关系构成一个图,而不只是树。
BMN(Bayes Multi-Net分类器)作为分类器对应一组贝叶斯网,类结点的每个可能取值均对应一个贝叶斯网。BMN可看作是BAN的推广,BAN认为对各个不同的类各特征之间的关系是不变的,而BMN则认为对类变量的不同取值,各特征之间的关系可能是不一样的。
GBN(General Bayes Network, 广义贝叶斯网络)是一种无约束的贝叶斯网分类器,和其他贝叶斯网分类器有较大区别的是,在其他分类器中均将类变量作为一特殊的结点,是各特征结点的父结点,而GBN中将特征结点作为一普通结点。GBN假设对整个数据集有一单一联合概率分布,而BMN则认为对不同的分类有不同的联合概率分布。因而对那些数据集有单一内在概率模型的应用使用GBN更合适,而对那些不同类的数据集其特征之间的依赖关系差异较大的应用场合,则使用BMN更合适。
LBR(Lazy learning of Bayesian Rules, LBR懒惰贝叶斯规则分类器)
HNB(Hidden Naive Bayes隐朴素贝叶斯)
DMNB(Discriminative Multinomial Naive Bayes基于多重判别分析的朴素贝叶斯)
10)支持向量分类
支持向量机(Support Vector Machine) 名字听起来很炫,功能也很炫,但公式理解起来常有眩晕感。所以本文尝试不用一个公式来说明SVM的原理,以保证不吓跑一个读者。理解SVM有四个关键名词: 分离超平面、最大边缘超平面、软边缘、核函数 。
分离超平面 ( separating hyperplane ) :处理分类问题的时候需要一个决策边界,好象楚河汉界一样,在界这边我们判别A,在界那边我们判别B。这种决策边界将两类事物相分离,而线性的决策边界就是分离超平面。
最大边缘超平面(Maximal Margin Hyperplane) :分离超平面可以有很多个,怎么找最好的那个呢,SVM的作法是找一个“最中间”的。换句话说,就是这个平面要尽量和两边保持距离,以留足余量,减小泛化误差,保证稳健性。或者用中国人的话讲叫做“执中”。以江河为国界的时候,就是以航道中心线为界,这个就是最大边缘超平面的体现。在数学上找到这个最大边缘超平面的方法是一个二次规划问题。
软边缘(Soft Margin) :但世界上没这么美的事,很多情况下都是“你中有我,我中有你”的混杂状态。不大可能用一个平面完美的分离两个类别。在线性不可分情况下就要考虑软边缘了。软边缘可以破例允许个别样本跑到其它类别的地盘上去。但要使用参数来权衡两端,一个是要保持最大边缘的分离,另一个要使这种破例不能太离谱。这种参数就是对错误分类的惩罚程度C。
核函数(Kernel Function), 为了解决完美分离的问题,SVM还提出一种思路,就是将原始数据映射到高维空间中去,直觉上可以感觉高维空间中的数据变的稀疏,有利于“分清敌我”。那么映射的方法就是使用“核函数”。如果这种“核技术”选择得当,高维空间中的数据就变得容易线性分离了。而且可以证明,总是存在一种核函数能将数据集映射成可分离的高维数据。看到这里各位不要过于兴奋,映射到高维空间中并非是有百利而无一害的。维数过高的害处就是会出现过度拟合。
所以 选择合适的核函数以及软边缘参数C就是训练SVM的重要因素 。一般来讲,核函数越复杂,模型越偏向于拟合过度。在参数C方面,它可以看作是 Lasso算法中的lambda的倒数,C越大模型越偏向于拟合过度,反之则拟合不足。实际问题中怎么选呢?用人类最古老的办法,试错。
常用的核函数有如下4类:1)Linear:使用它的话就成为线性向量机,效果基本等价于Logistic回归。但它可以处理变量极多的情况,例如文本挖掘。2)polynomial:多项式核函数,适用于图像处理问题。3)Radial basis,高斯核函数,最流行易用的选择。参数包括了sigma,其值若设置过小,会有过度拟合出现。4)sigmoid:反曲核函数,多用于神经网络的激活函数。
11)分类决策树ID3
ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
ID3算法最早是由罗斯昆(J. Ross Quinlan)于1975年在悉尼大学提出的一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。
决策树是对数据进行分类,以此达到预测的目的。该决策树方法先根据训练集数据形成决策树,如果该树不能对所有对象给出正确的分类,那么选择一些例外加入到训练集数据中,重复该过程一直到形成正确的决策集。决策树代表着决策集的树形结构。决策树由决策结点、分支和叶子组成。决策树中最上面的结点为根结点,每个分支是一个新的决策结点,或者是树的叶子。每个决策结点代表一个问题或决策,通常对应于待分类对象的属性。每一个叶子结点代表一种可能的分类结果。沿决策树从上到下遍历的过程中,在每个结点都会遇到一个测试,对每个结点上问题的不同的测试输出导致不同的分支,最后会到达一个叶子结点,这个过程就是利用决策树进行分类的过程,利用若干个变量来判断所属的类别。
以下是一些信息论的基本概念:
定义1:若存在n个相同概率的消息,则每个消息的概率p是1/n,一个消息传递的信息量为-Log2(1/n)
定义2:若有n个消息,其给定概率分布为P=(p1,p2…pn),则由该分布传递的信息量称为P的熵,记为。
定义3:若一个记录集合T根据类别属性的值被分成互相独立的类C1C2..Ck,则识别T的一个元素所属哪个类所需要的信息量为Info(T)=I(p),其中P为C1C2…Ck的概率分布,即P=(|C1|/|T|,…..|Ck|/|T|)
定义4:若我们先根据非类别属性X的值将T分成集合T1,T2…Tn,则确定T中一个元素类的信息量可通过确定Ti的加权平均值来得到,即Info(Ti)的加权平均值为:
Info(X, T)=(i=1 to n 求和)((|Ti|/|T|)Info(Ti))
定义5:信息增益度是两个信息量之间的差值,其中一个信息量是需确定T的一个元素的信息量,另一个信息量是在已得到的属性X的值后需确定的T一个元素的信息量,信息增益度公式为:
Gain(X, T)=Info(T)-Info(X, T)
ID3衍生出来了C4.5和CART决策树算法。
信息增益实际上是ID3算法中用来进行属性选择度量的。它选择具有最高信息增益的属性来作为节点N的分裂属性。该属性使结果划分中的元组分类所需信息量最小。对D中的元组分类所需的期望信息为下式:
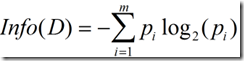
Info(D)又称为熵。
现在假定按照属性A划分D中的元组,且属性A将D划分成v个不同的类。在该划分之后,为了得到准确的分类还需要的信息由下面的式子度量:
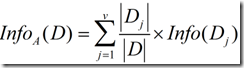
信息增益定义为原来的信息需求(即仅基于类比例)与新需求(即对A划分之后得到的)之间的差,即
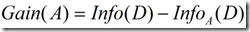
一般说来,对于一个具有多个属性的元组,用一个属性就将它们完全分开几乎不可能,否则的话,决策树的深度就只能是2了。从这里可以看出,一旦我们选择一个属性A,假设将元组分成了两个部分A1和A2,由于A1和A2还可以用其它属性接着再分,所以又引出一个新的问题:接下来我们要选择哪个属性来分类?对D中元组分类所需的期望信息是Info(D) ,那么同理,当我们通过A将D划分成v个子集Dj(j=1,2,…,v)之后,我们要对Dj的元组进行分类,需要的期望信息就是Info(Dj),而一共有v个类,所以对v个集合再分类,需要的信息就是公式(2)了。由此可知,如果公式(2)越小,是不是意味着我们接下来对A分出来的几个集合再进行分类所需要的信息就越小?而对于给定的训练集,实际上Info(D)已经固定了,所以选择信息增益最大的属性作为分裂点。
但是,使用信息增益的话其实是有一个缺点,那就是它偏向于具有大量值的属性。什么意思呢?就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性。例如一个训练集中有10个元组,对于某一个属相A,它分别取1-10这十个数,如果对A进行分裂将会分成10个类,那么对于每一个类Info(Dj)=0,从而式(2)为0,该属性划分所得到的信息增益(3)最大,但是很显然,这种划分没有意义。
相关推荐
机器学习概念总结笔记(一)
机器学习概念总结笔记(三)
机器学习概念总结笔记(四)
此文已由作者授权腾讯云技术社区发布,转载请注明原文出处

 浙公网安备 33010602011771号
浙公网安备 33010602011771号