


NLP 中 Attention Model 解析
Attention Model,简称AM模型,本文只谈文本领域的AM模型,其实图片领域AM的机制也是相同的。
目前绝大多数文献中出现的AM模型是附着在Encoder-Decoder框架下的,但是其实AM模型可以看作一种通用的思想,本身并不依赖于Encoder-Decoder模型。
Encoder-Decoder框架
文本处理领域里常用的Encoder-Decoder框架,可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。
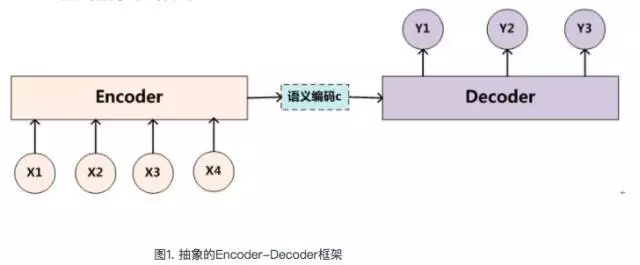
对于句子对<X,Y>:我们的目标是给定输入句子X,期待通过Encoder-Decoder框架来生成目标句子Y。X和Y可以是同一种语言,也可以是两种不同的语言。对于机器翻译来说,<X,Y>就是对应不同语言的句子,比如X是英语句子,Y是对应的中文句子翻译。再比如对于文本摘要来说,X就是一篇文章,Y就是对应的摘要;再比如对于对话机器人来说,X就是某人的一句话,Y就是对话机器人的应答。
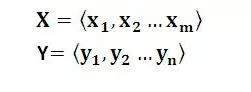
Encoder顾名思义就是对输入句子X进行编码,将输入句子通过非线性变换转化为中间语义表示C:
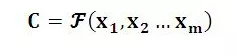
对于解码器Decoder来说:其任务是根据句子X的中间语义表示C和之前已经生成的历史信息y1,y2….yi-1来生成i时刻要生成的单词yi。每个yi都依次这么产生,那么看起来就是整个系统根据输入句子X生成了目标句子Y。
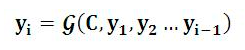
Encoder-Decoder是个非常通用的计算框架,至于Encoder和Decoder具体使用什么模型都是由研究者自己定的,常见的比如CNN/RNN/BiRNN/GRU/LSTM/Deep LSTM等,这里的变化组合非常多,而很可能一种新的组合就能攒篇论文。
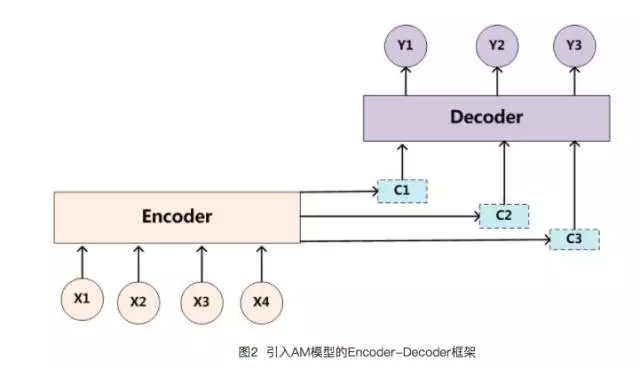
但是,上图的Encoder-Decoder模型是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。
因为在生成目标句子的单词时,不论生成哪个单词,是y1,y2也好,还是y3也好,他们使用的句子X的语义编码C都是一样的,没有任何区别。而语义编码C是由句子X的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实句子X中任意单词对生成某个目标单词yi来说影响力都是相同的,没有任何区别。
比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。在翻译 “杰瑞” 这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,如果引入 AM模型 的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:(Tom,0.3)(Chase,0.2) (Jerry,0.5)。每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。
AM模型
理解AM模型的关键就是由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。
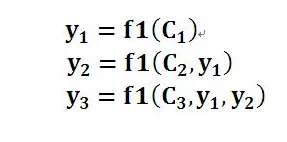
比如对于上面的英汉翻译来说:

f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入xi后隐层节点的状态值;
g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,也就是常常在论文里看到的下列公式:
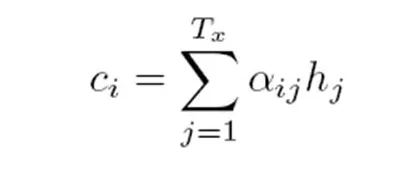
所以目前的关键是如何得到 (Tom, 0.6), (Chase, 0.2), (Jerry, 0.2) 等依据不同输入句子的单词注意力分配概率分布值。
假如:Encoder采用RNN模型,Decoder也采用RNN模型:
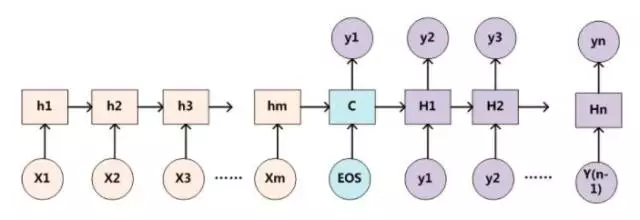
则用下图可以较为便捷地说明注意力分配概率分布值的通用计算过程:
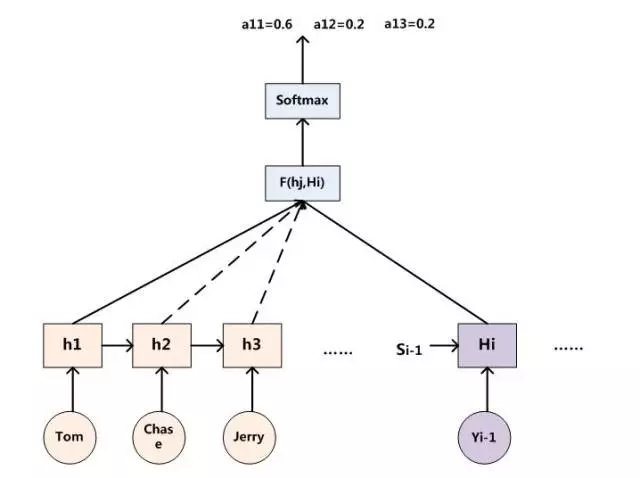
所以可以通过函数F(hj,Hi)来获得目标单词Yi和每个输入单词对应的对齐可能性,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
M模型的物理含义,一般文献里会把AM模型看作是单词对齐模型,目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率。
当然,我觉得从概念上理解的话,把AM模型理解成影响力模型也是合理的,就是说生成目标单词的时候,输入句子每个单词对于生成这个单词有多大的影响程度。这种想法也是比较好理解AM模型物理意义的一种思维方式。

