
B+树索引
B+树索引文件
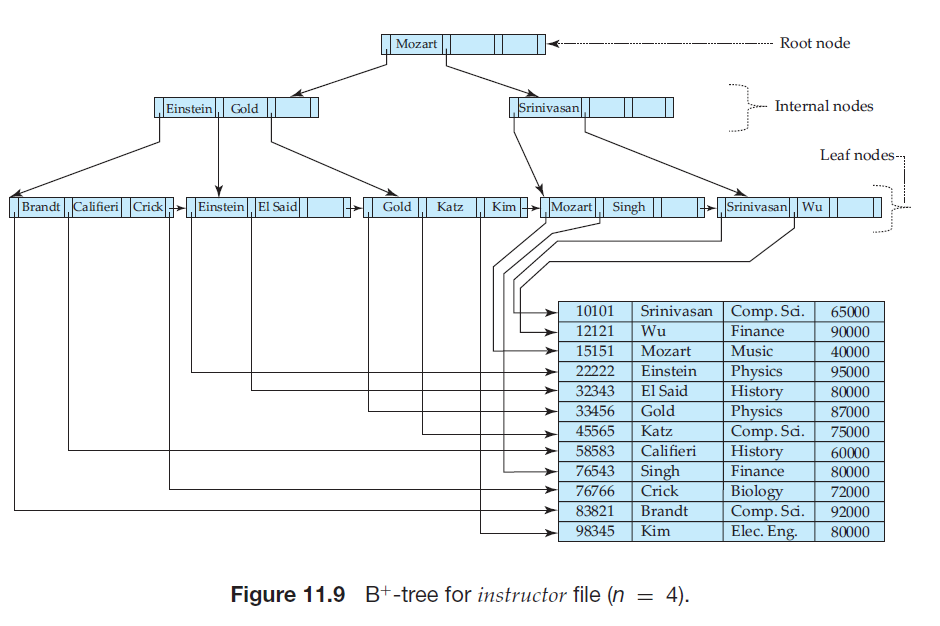
B+s树采用平衡树的结构,根到叶的每条路径长度相同,每个非叶结点有
\(\left \lceil n/2 \right \rceil\) ~ \(n\)个指针

如图,对于一个包含m个指针的结点(\(m \leq n\))有\(K_{i-1} \leq val(P_i) < K_i\) ( i = 2,3,...,m-1), \(P_1\)指向小于\(K_1\)的部分, \(P_m\)指向大于等于\(K_{m-1}\)的部分,通常将一个结点的指针数称为扇出(fanout)
B+树查询


如果没有重复的搜索码,我们找到最小的i使得\(K_i\)大于等于V,如果\(K_i == V\),则将当前结点设置为\(P_{i+1}\), 如果\(K_i > V\),则将当前结点设置为\(P_i\),如果叶结点中没有等于V的搜索码值,则find返回空值表示失败。
如果有重复的搜索码,则\(i < j\), \(K _i < K_j\)不一定成立,但一定有\(K _i \leq K_j\),也就是相同搜索码可能在一些连续的结点中,于是我们修改Find方法,即使\(V == K_i\),也将其置为\(P_i\),在到达叶结点的时候,找到第一个符合条件的值,这样我们将find方法修改为findFirst,然后在叶结点遍历,范围查询(range query)也是如此,查找(L, U)是先findFirst(L),只是结束条件变成了\(K_i\)> U而不是V
如果文件有N个搜索码值,那么这条路径的长度不会超过\(\left \lceil log_{\left \lceil n/2 \right \rceil} (N))\right \rceil\),结点大小一般等于磁盘大小4KB,如果搜索码大小为12字节,磁盘指针大小为8字节,那么n大约为200,更保守估计,搜索码大小达到32字节,n也大约为100。n=100,文件中搜索码值有100万时,一次查找也只需要访问\(\left \lceil log_{\left \lceil 50 \right \rceil} (1 000 000))\right \rceil\) = 4个结点,通常根结点访问频繁,很可能在缓冲区中,因此一般只需要从磁盘读三个或更少的磁盘块
B+树与内存中的二叉树的区别
B+树与二叉树的一个重大区别在于结点的大小和树的高度,B+树一般矮而胖,二叉树一般瘦而高
B+树的更新
插入
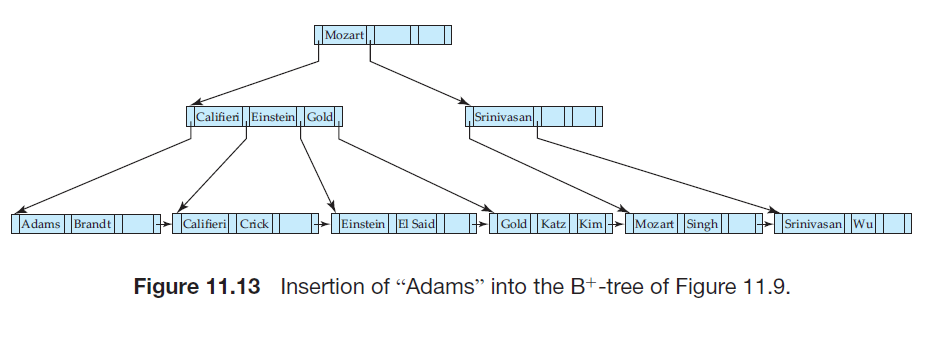
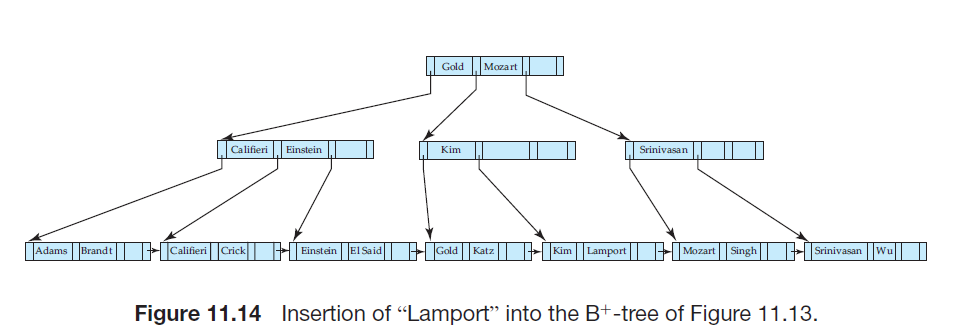
若叶结点未满,则直接插入
当叶结点过满,则需要分裂叶结点,将新结点的最小搜索码值插入其父结点中,这样也可能会引起父结点过满,则递归向上处理,直到不再产生分裂或生成新的根结点为止

删除
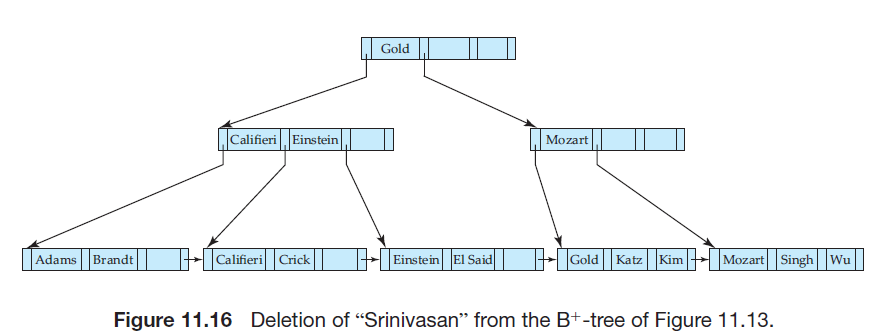
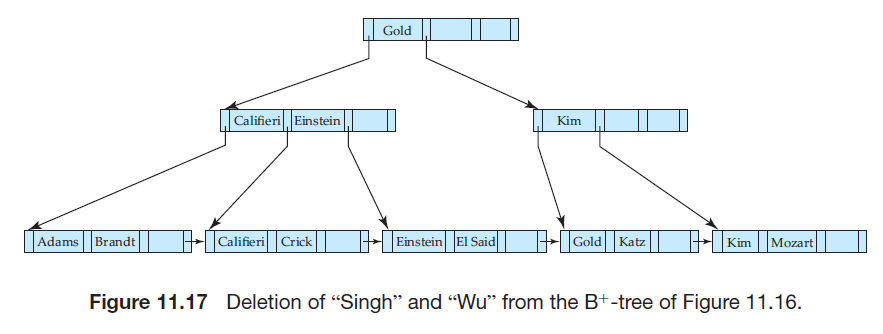
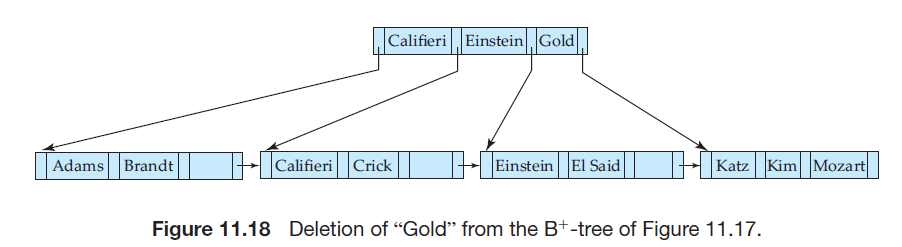
若删除导致结点太空,这种情况下,我们考虑其兄弟结点,如果能合并就合并,如果合并超过了最大数量n,则需要在该结点和其兄弟结点间重新分配指针,以便每个结点至少含\(\left \lceil n/2 \right \rceil\)个指针,如下图,将左边兄弟结点的最右指针移动到太空的右边兄弟

B+树扩展
辅助索引
B+树可能改变记录的位置,但记录本身并没有更新,如结点分裂,这样所有存储了重定位的辅助索引必须更新,其代价可能十分高昂,为解决这个问题,在辅助索引中,不存储指向被索引记录的指针,而是存储主索引搜索码的值,然后通过主索引来找到对应的记录
字符串上的索引
在字符串上创建索引会引来两个问题,
- 字符串是变长的
- 字符串可能会很长,导致结点扇出降低以及增加树的高度
对于变长搜索码,即使结点全满,不同的节点也会有不同的扇出,如果一个结点已满,则它必须分裂,所以结点的分裂取决于结点的空间使用比例,而不是结点的最大可容量项数
使用前缀压缩可以增加结点的扇出,如对于由搜索码“Silberschatz”分开的两个子树中最相近的码值为“Silas”与“Silver”,则非叶结点存储“Slib”就够了而不用存储“Silberschatz”
多码访问
使用多个单码索引
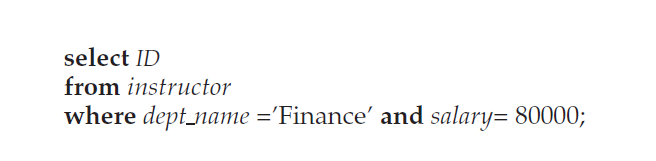
对于上述查询语句,有三种查询策略
- 利用dept_name上的索引,找出所有属于“Finance”的记录,然后逐一检查是否满足salary=80000
- 利用salary上的索引,找出所有salary=80000的记录,然后逐一检查是否满足属于“Finance”
- 利用dept_name上的索引找到满足dept_name=“Finance”的所有指针,利用salary上的索引,找出所有salary=80000的所有指针,取交集
最后一种方案利用了已存在的多个索引的优势,但是如果下列条件都成立,这种策略也可能是种糟糕的选择
- dept_name=“Finance”的记录太多
- salary=80000的记录太多
- dept_name=“Finance”且salary=80000的只有几个
如果上述条件成立,则为了得到一个很小的结果集,我们必须扫描大量指针
多码索引
也可以在复合搜索码(dept_name, salary)上建立和使用索引
可以很简单处理


但对于下列这种范围查询,由于每条记录可能位于不同的磁盘块,将导致大量的IO操作
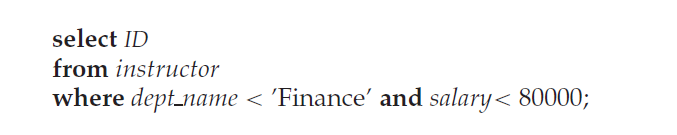
覆盖索引
覆盖索引存储一些其他属性的值和指向记录的指针,假如建立在instructor关系的ID属性上的非聚集索引,如果存储额外的salary属性,则查询salary时,不需要访问及记录,虽然在搜索码(ID,salary)上建立索引能达到同样的效果,但是覆盖索引能够减小搜索码的大小,使得非叶结点有更大的扇出
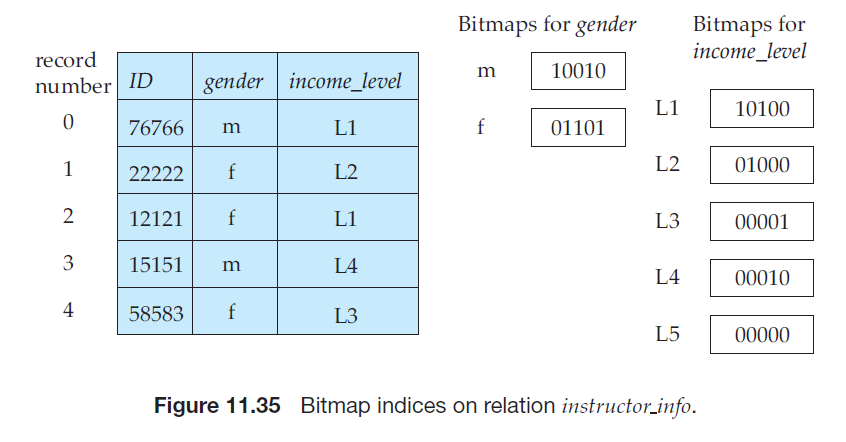
位图索引
位图就是位的简单数组
使用位图索引能够加快“使用多个单码索引”中第三种策略的集合交操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号