


数据结构与JAVA(JCF)的结合
1.参考文档:
JCF集合框架概述 : https://www.cnblogs.com/haimishasha/p/10757722.html
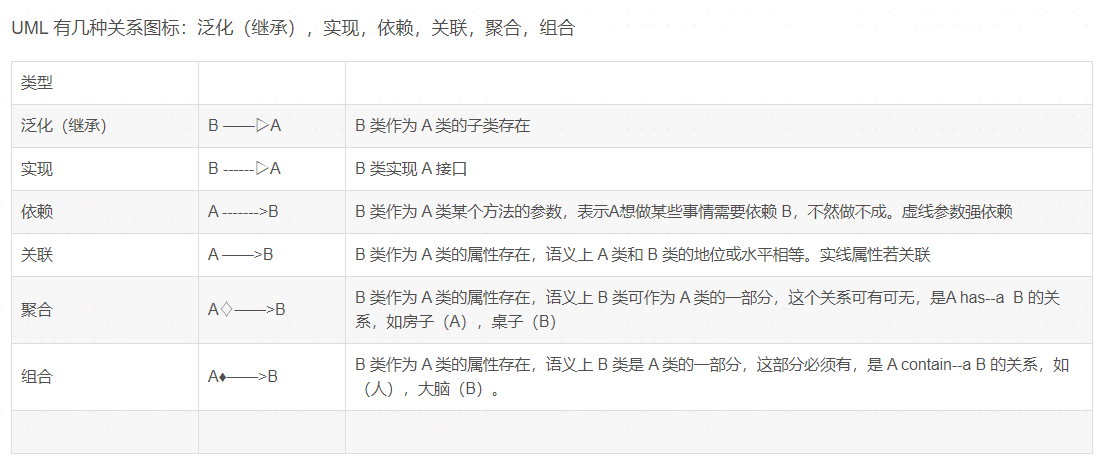
UML图:https://blog.csdn.net/huaishu/article/details/108343852
10种排序算法:https://www.cnblogs.com/onepixel/articles/7674659.html
java8 中文API:https://www.matools.com/api/java8
2.JCF
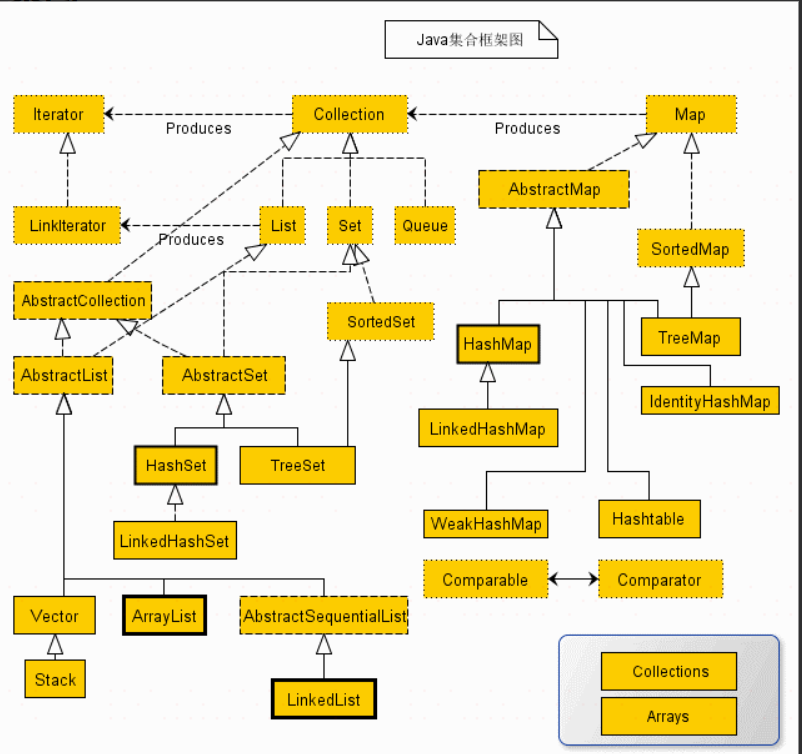
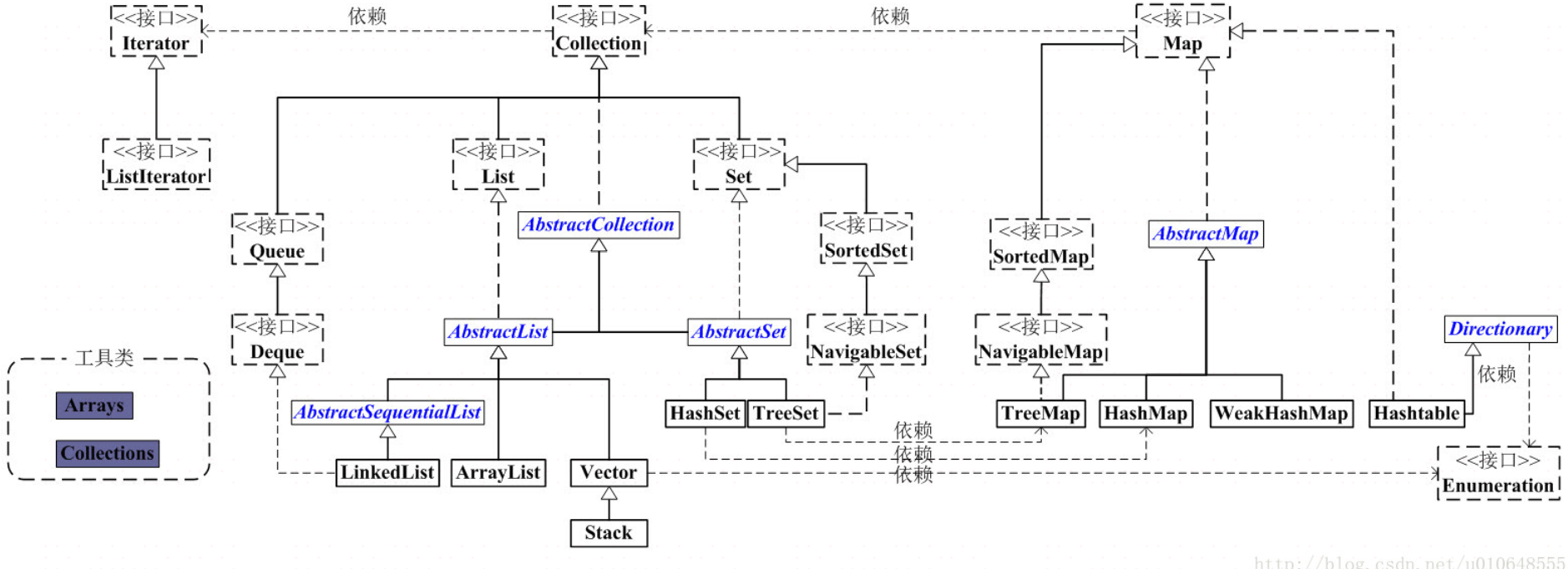
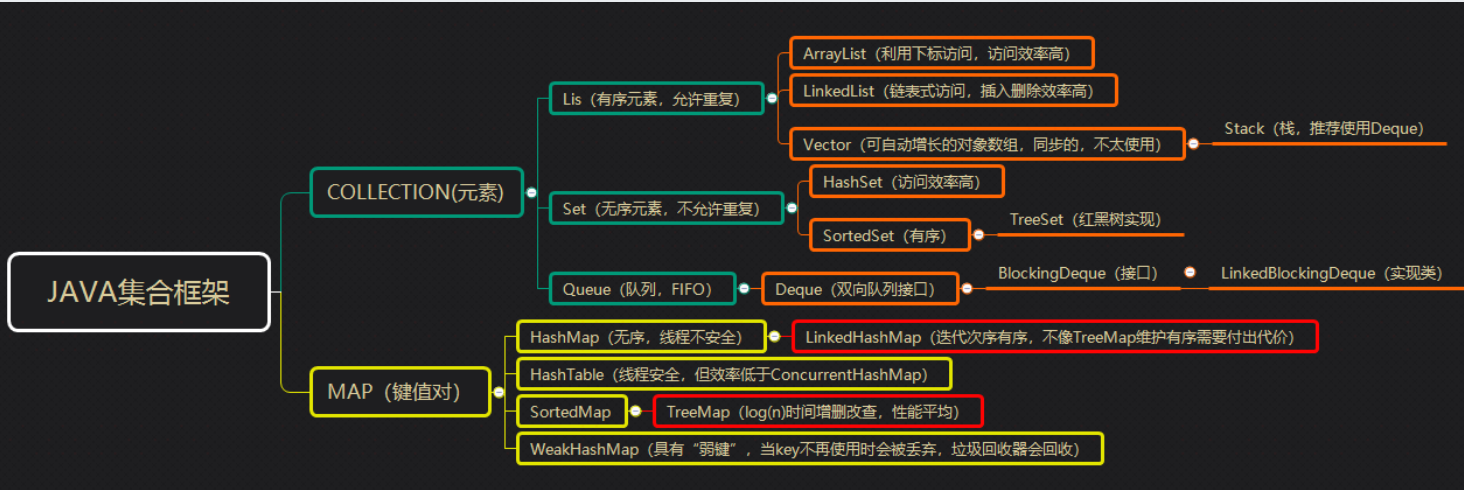
容器,就是可以容纳其他Java对象的对象。Java Collections Framework(JCF)为Java开发者提供了通用的容器
3.数据结构与算法:
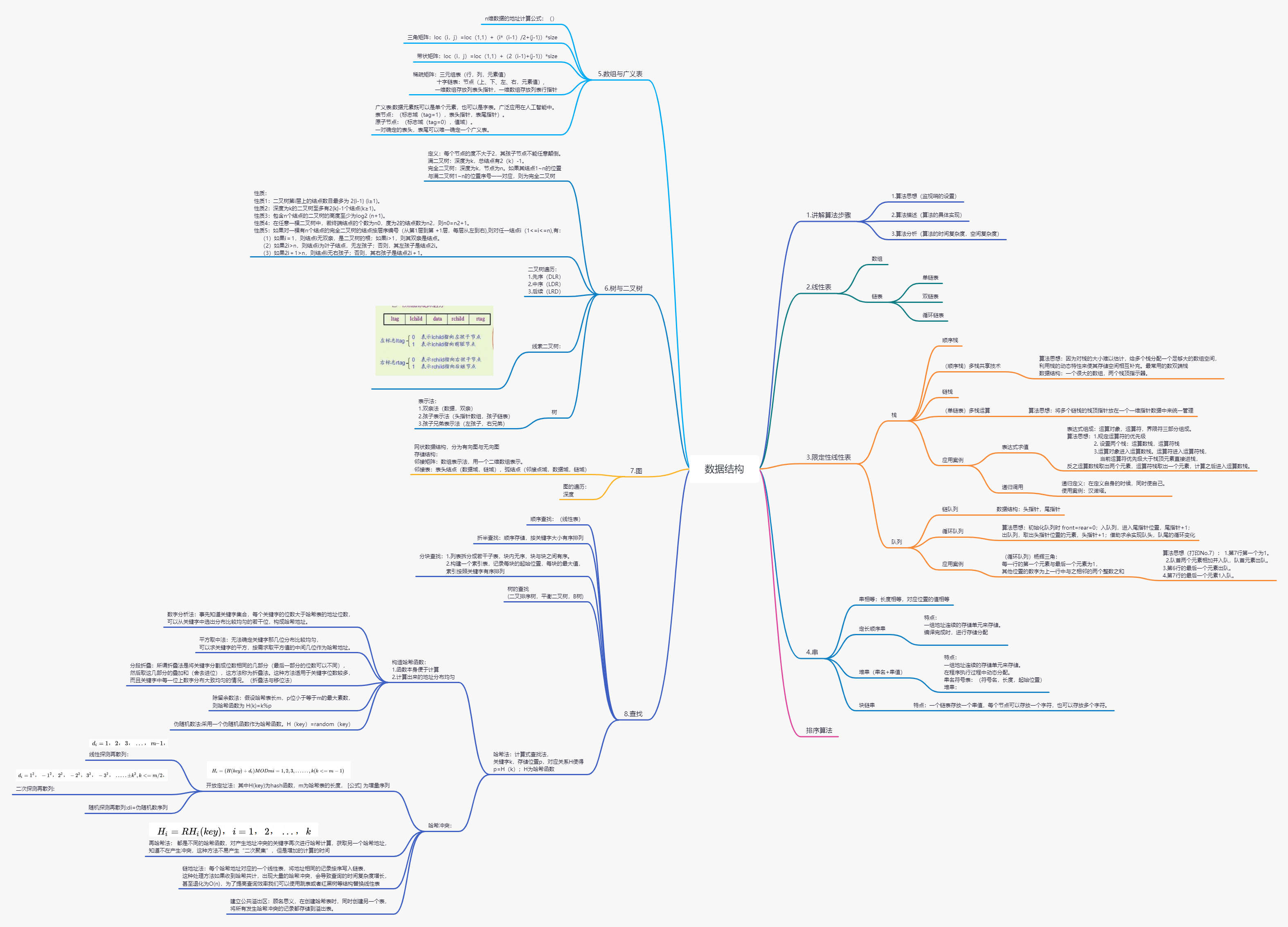
4. 10种常用的排序算法:
十种常见排序算法可以分为两大类:
- 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
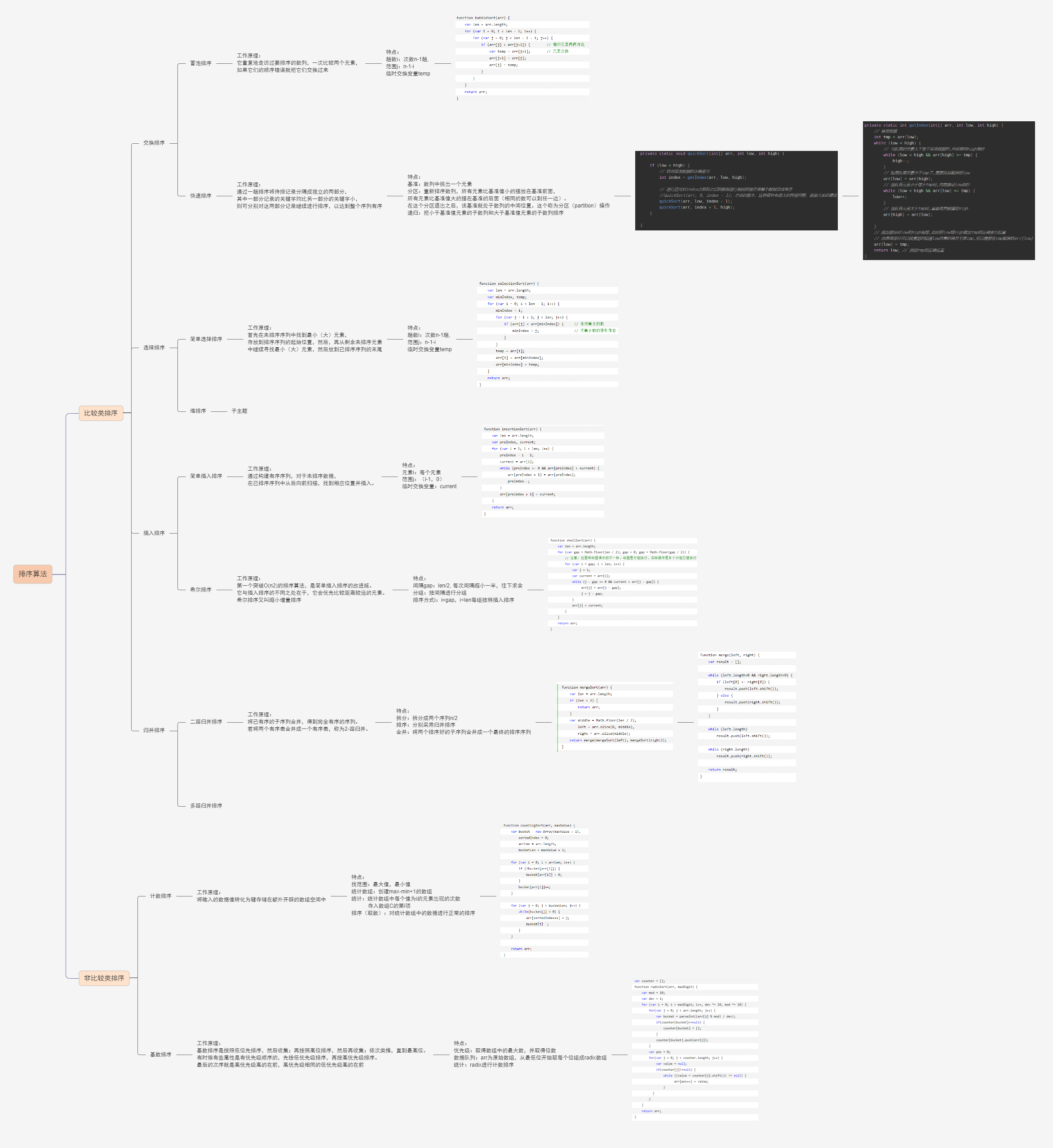
算法分析:复杂度
相关概念
-
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
- 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
- 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
- 空间复杂度:是指算法在计算机
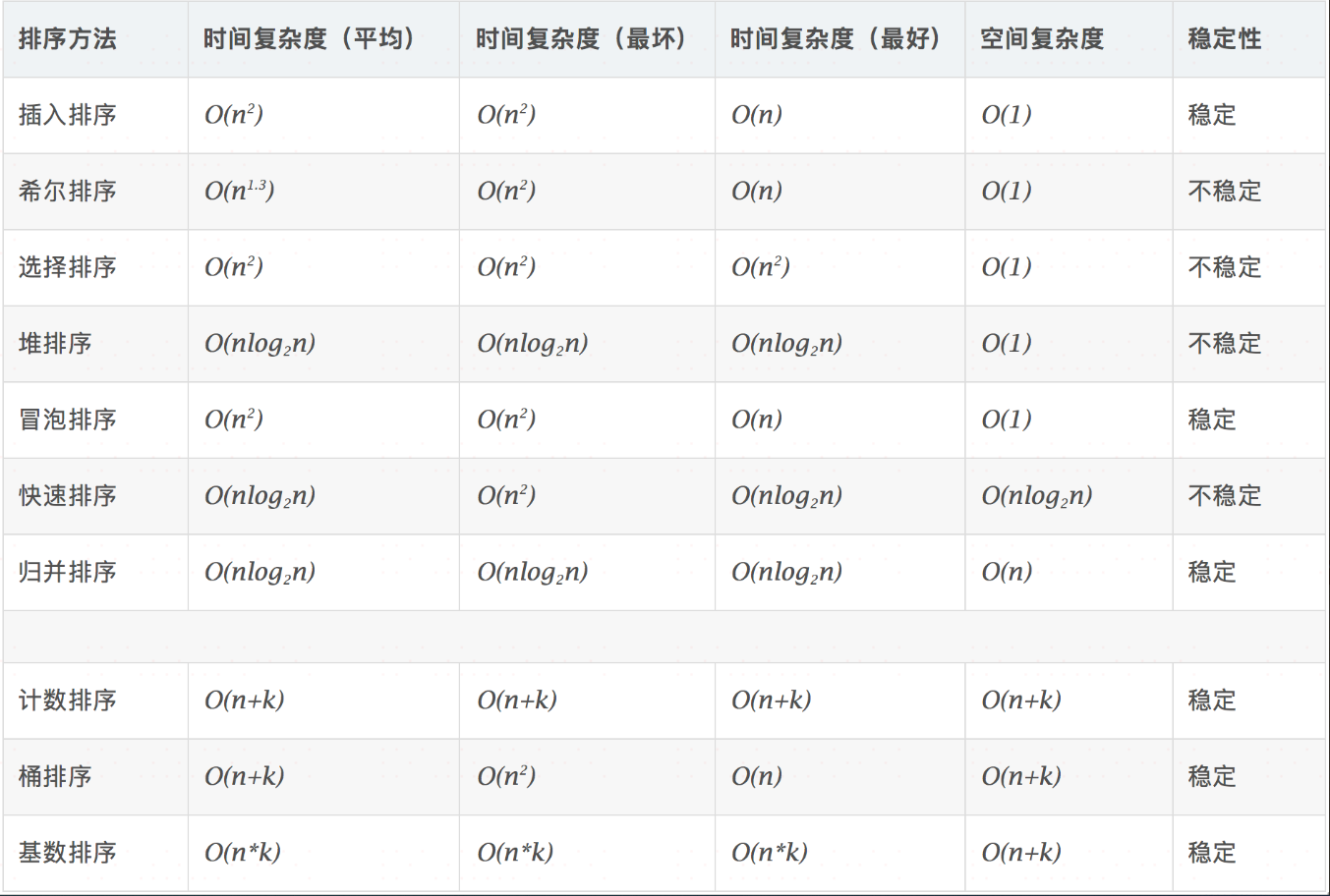
5、java对数据结构的实战
5.1HashMap
- 参考文档:Map 综述(一):彻头彻尾理解 HashMap(https://blog.csdn.net/justloveyou_/article/details/62893086)
- Hash:Hash 就是把任意长度的输入(又叫做预映射, pre-image),通过哈希算法,变换成固定长度的输出(通常是整型),该输出就是哈希值。这种转换是一种 压缩映射 ,也就是说,散列值的空间通常远小于输入的空间。不同的输入可能会散列成相同的输出,从而不可能从散列值来唯一的确定输入值。简单的说,就是一种将任意长度的消息压缩到某一固定长度的息摘要函数。
- Entry<K,V> 条目类型: (key,value,next指针,hash值)
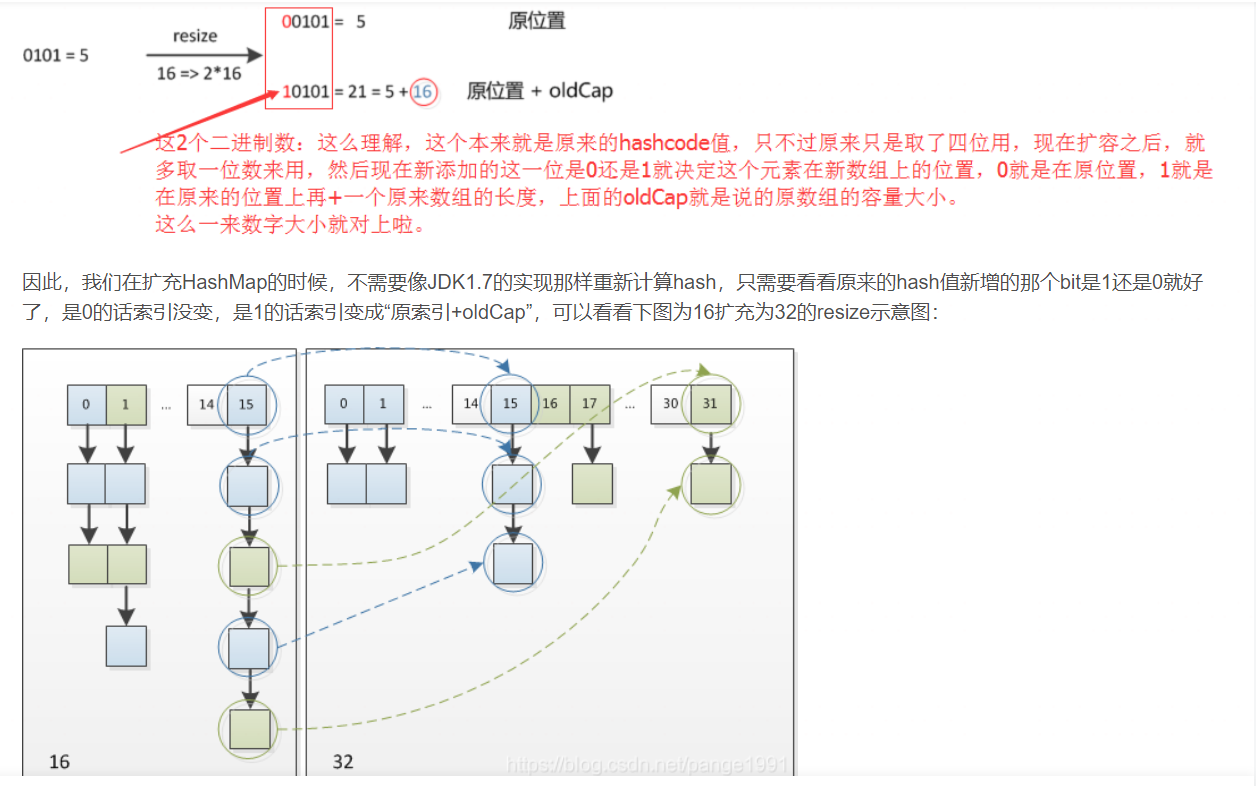
- 哈希策略(算法): 使用hash()方法对一个对象的hashCode进行重新计算是为了防止质量低下的hashCode()函数实现。由于hashMap的支撑数组长度总是 2 的幂次,通过右移 可以使低位的数据尽量的不同,从而使hash值的分布尽量均匀。

- 哈希表的存取操作:在存储的过程中,系统根据key的hash值来定位Entry在table数组中的哪个桶,并且将其放到对应的链表的链头;在取的过程中,同样根据key的hash值来定位Entry在table数组中的哪个桶,然后在该桶中查找并返回。存放过程中,如果已存在,则使用新Value值替换旧Value值,并返回旧Value值;如果不存在,则存放新的键值对<Key, Value>到桶中。因此,在 HashMap中,equals() 方法只有在哈希码碰撞时才会被用到。
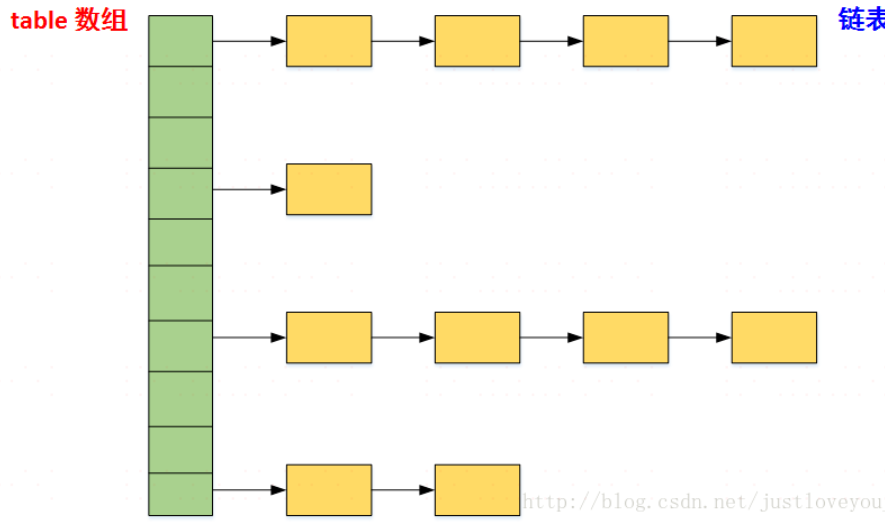
- HashMap的扩容机制---resize():
参考:https://blog.csdn.net/pange1991/article/details/82347284
java 1.8版本之前:
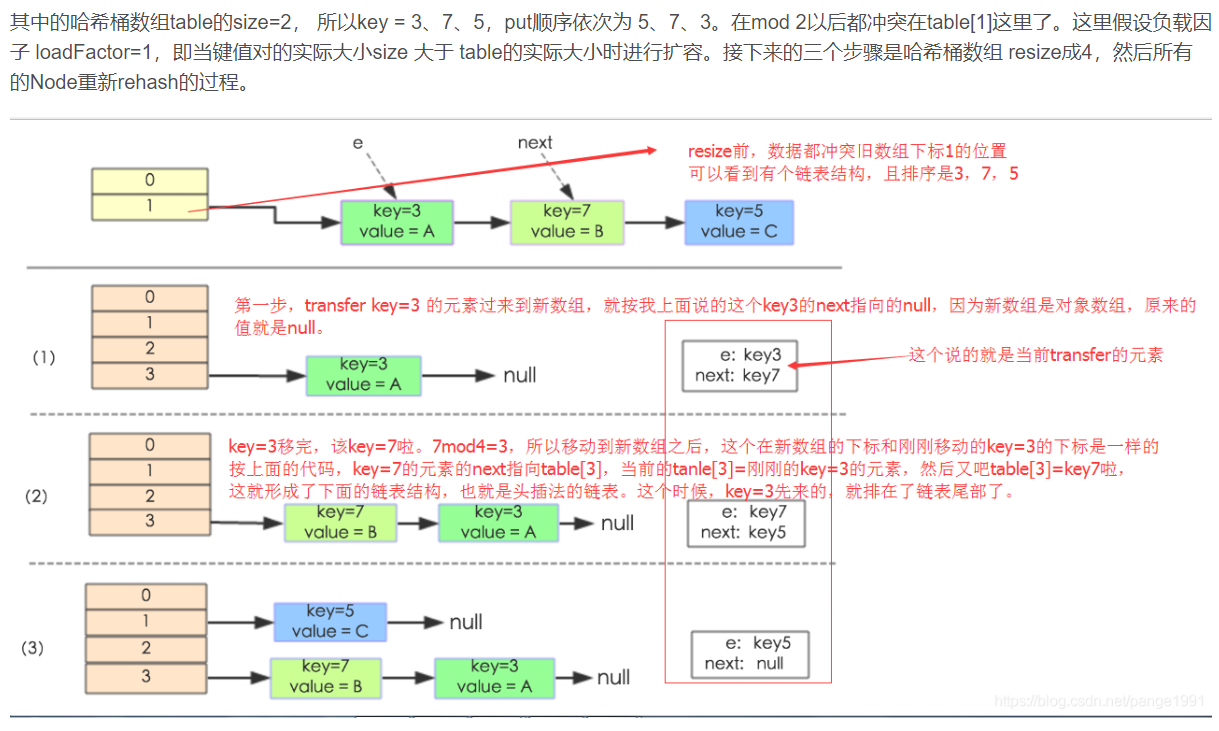
在 Java 1.8中 HashMap 扩容时对红黑树节点的修剪。
- 哈希碰撞:
-
- == : 该操作符生成的是一个boolean结果,它计算的是操作数的值之间的关系
- equals : Object 的 实例方法,比较两个对象的content是否相同
- hashCode : Object 的 native方法 , 获取对象的哈希值,用于确定该对象在哈希表中的索引位置,它实际上是一个int型整数
- 如果两个对象的hashCode不同,那么equals一定为 false;否则,如果其hashCode相同,equals也不一定为 true。所以,理论上,hashCode 可能存在碰撞的情况,当碰撞发生时,这时会取出bucketIndex桶内已存储的元素,并通过hashCode() 和 equals() 来逐个比较以判断Key是否已存在。如果已存在,则使用新Value值替换旧Value值,并返回旧Value值;如果不存在,则存放新的键值对<Key, Value>到桶中。因此,在 HashMap中,equals() 方法只有在哈希码碰撞时才会被用到。
- HashMap 中可以保存键为NULL的键值对,且该键值对是唯一的。若再次向其中添加键为NULL的键值对,将覆盖其原值。此外,如果HashMap中存在键为NULL的键值对,那么一定在第一个桶中。
5.2LinkedHashMap
参考文档:Map 综述(二):彻头彻尾理解 LinkedHashMap(https://blog.csdn.net/justloveyou_/article/details/71713781)
数据结构:HashMap和双向链表
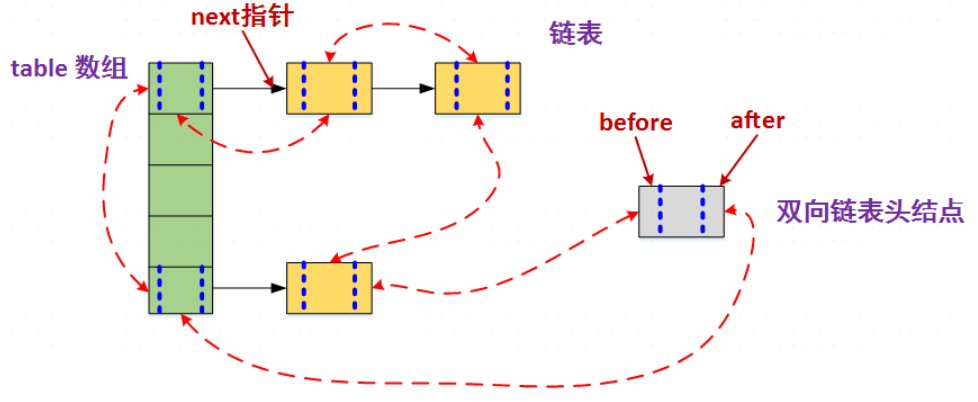
结点结构:
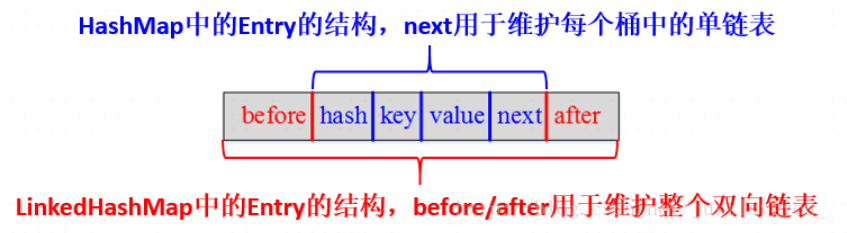
概述:HashMap是无序的。LinkedHashMap 增加了双向链表头结点 header和标志位 accessOrder两个属性,用于保证迭代顺序根据链表中元素的顺序。可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap 和 保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的。插入顺序按照尾插法。
5.3hashset
参考地址:https://www.jianshu.com/p/a5063dd843d5
总结:HashSet由于内部实现是完全基于HashMap的,所以原理较为简单,代码也不多,源码加上注释也就是300多行。
关于hashSet的实现原理,我们需要掌握一下几点
-
-
hashSet内部用HashMap来存储元素
-
HashSet利用本身的值来计算hash值,因为值被当作hashmap的key,而hashmap是利用key来计算hash值的
-
因为hashset将value当作key来存储,所以根据map的key值唯一的原理,我们就可以实现set的无重复元素的功能
-
Set 与Map的区别:
-
- Set 和 Map 主要的应用场景在于 数据重组 和 数据储存。
- Set 是一种叫做集合的数据结构,Map 是一种叫做字典的数据结构。
集合 与 字典 的区别:
-
- 共同点:集合、字典 可以储存不重复的值
- 不同点:集合 是以 [value, value]的形式储存元素,字典 是以 [key, value] 的形式储存


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!