

机器学习的数学基础
矩阵
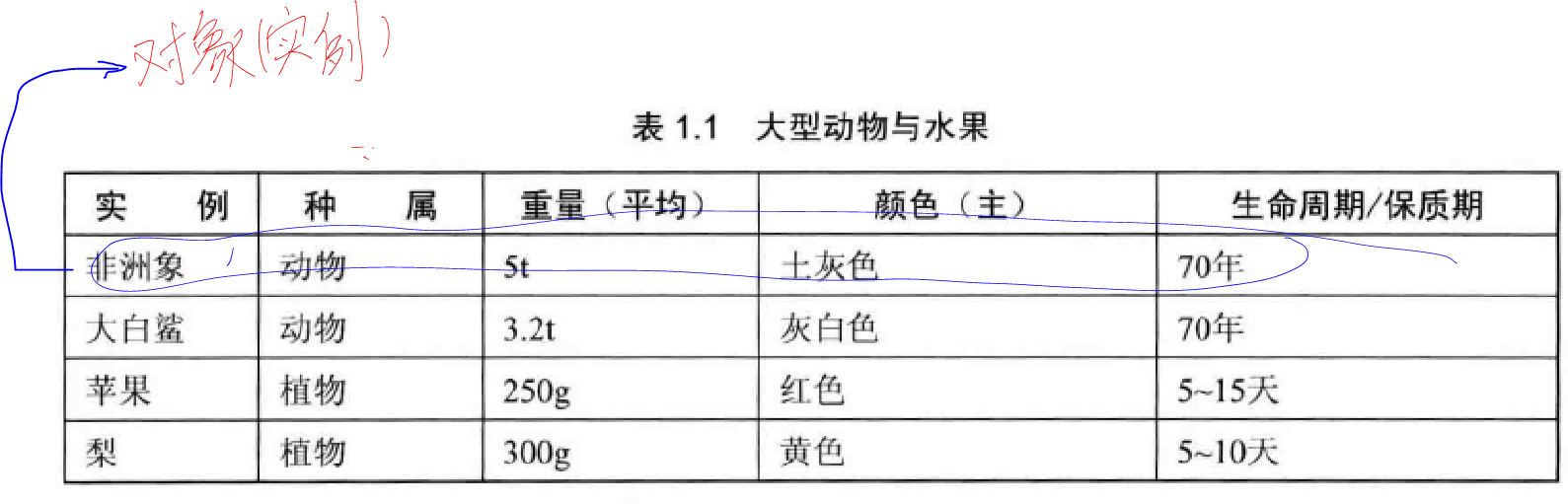
参考: 机器学习基础
一般而言,一个对象应该被视为完整的个体,表现实中有意义的事物,不能轻易拆分。
对象是被特征化的客观事物,而表(或矩阵)是容纳这些对象的容器。换句话说,对象是表中的元素,表是对象的集合(表中的每个对象都有相同的特征和维度,对象对于每个特征都有一定的取值)。
分类或聚类可以看作根据对象特征的相似性与差异性,对矩阵空间的一种划分。
预测或回归可以看作根据对象在某种序列(时间)上的相关性,表现为特征取值变化的一种趋势。
import numpy as np
a = np.arange(9).reshape((3, -1))
a
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
b = a.copy()
id(a) == id(b)
False
repr(a) == repr(b)
True
Linalg
A = np.mat([[1, 2, 4, 5, 7], [9,12 ,11, 8, 2], [6, 4, 3, 2, 1], [9, 1, 3, 4, 5], [0, 2, 3, 4 ,1]])
行列式
np.linalg.det(A)
-812.00000000000068
逆
np.linalg.inv(A)
matrix([[ -7.14285714e-02, -1.23152709e-02, 5.29556650e-02,
9.60591133e-02, -8.62068966e-03],
[ 2.14285714e-01, -3.76847291e-01, 1.22044335e+00,
-4.60591133e-01, 3.36206897e-01],
[ -2.14285714e-01, 8.25123153e-01, -2.04802956e+00,
5.64039409e-01, -9.22413793e-01],
[ 5.11521867e-17, -4.13793103e-01, 8.79310345e-01,
-1.72413793e-01, 8.10344828e-01],
[ 2.14285714e-01, -6.65024631e-02, 1.85960591e-01,
-8.12807882e-02, -1.46551724e-01]])
转置
A.T
matrix([[ 1, 9, 6, 9, 0],
[ 2, 12, 4, 1, 2],
[ 4, 11, 3, 3, 3],
[ 5, 8, 2, 4, 4],
[ 7, 2, 1, 5, 1]])
A * A.T
matrix([[ 95, 131, 43, 78, 43],
[131, 414, 153, 168, 91],
[ 43, 153, 66, 80, 26],
[ 78, 168, 80, 132, 32],
[ 43, 91, 26, 32, 30]])
秩
np.linalg.matrix_rank(A)
5
解方程
b = [1, 0, 1, 0, 1]
S = np.linalg.solve(A, b)
S
array([-0.0270936 , 1.77093596, -3.18472906, 1.68965517, 0.25369458])
现代数学三大基石:
- 概率论说明了事物可能会是什么样;
- 数值分析揭示了它们为什么这样,以及如何变成这样;
- 线性代数告诉我们事物从来不只有一个样子,使我们能够从多个角度来观察事物。
相似性度量
闵可夫斯基 Minkowski() 距离对应于 \(||\cdot||_p\), 即
\begin{aligned}
d = ||x_1-x_2||_p & & x_1, x_2 \in \mathbb{R}^n
\end{aligned}
- 曼哈顿距离 (Manhattan) : \(p=1\), 又称为城市街区距离 (City Block distance)
- 切比雪夫 (Chebyshev) 距离: \(p=∞\), 可用来计算象棋走的步数.
比较常见是范数(如欧式距离(\(L_2\))、曼哈顿距离(\(L_1\))、切比雪夫距离(\(L_{\infty}\)))和夹角余弦。下面我主要说明一下其他的几个比较有意思的度量:
汉明距离(Hamming)
定义:两个等长字符串 s1 与 s2 之间的汉明距离定义为将其中一个变成另外一个所需要的最小替换次数。(对应于 \(||\cdot||_0\))
应用:信息编码(为了增强容错性,应该使得编码间的最小汉明距离尽可能大)。
A = np.mat([[1, 1, 0, 1, 0, 1, 0, 0, 1], [0, 1, 1, 0, 0, 0, 1, 1, 1]])
smstr = np.nonzero(A[0] - A[1])
A[0] - A[1]
matrix([[ 1, 0, -1, 1, 0, 1, -1, -1, 0]])
smstr
(array([0, 0, 0, 0, 0, 0], dtype=int64),
array([0, 2, 3, 5, 6, 7], dtype=int64))
d = smstr[0].shape[0]
d
6
杰卡德相似系数(Jaccard Similarity Coefficient)
相似度:
杰卡德距离(Jaccard Distance)
区分度:
应用:
样本 \(A\) 和样本 \(B\) 所有维度的取值为 \(0\) 或 \(1\),表示包含某个元素与否。
import scipy.spatial.distance as dist
A
matrix([[1, 1, 0, 1, 0, 1, 0, 0, 1],
[0, 1, 1, 0, 0, 0, 1, 1, 1]])
dist.pdist(A, 'jaccard')
array([ 0.75])
蝴蝶效应(洛伦兹动力学方程):确定性与随机性相统一

- 系统未来的所有运动都被限制在一个明确的范围之内——确定性;
- 运动轨迹变化缠绕的规则是随机性的,任何时候你都无法准确判定下一次运动的轨迹将落在「蝴蝶」的哪侧翅膀上的哪个点上——随机性。
总而言之,系统运动大的范围是确定的、可测的,但是运动的细节是随机的、不可测的。
从统计学角度来看,蝴蝶效应说明了:
- 样本总体(特征向量或对象)的取值范围一般是确定的,所有样本对象(包括已经存在的和未出现的)的取值都位于此空间内;
- 无论收集再多的样本对象,也不能使这种随机性降低或消失。
随机性是事物的一种根本的、内在的、无法根除的性质,也是一切事物(概率)的本质属性。
衡量事物运动的随机性,必须从整体而不是局部来认知事物,因为从每个局部,事物可能看起来都是不同的(或相同的)。
概率论便是度量随机性的一个工具。一般地,上述所说的矩阵,被称为设计矩阵,基本概念重写:
- 样本(样本点):原指随机试验的一个结果,可以理解为设计矩阵中的一个对象,如苹果、小猪等。
- 样本空间:原指随机试验所有可能结果的集合,可以理解为矩阵的所有对象,引申为对象特征的取值范围:\(10\) 个苹果,\(2\) 只小猪。
- 随机事件:原指样本空间的一个子集,可以理解为某个分类,它实际指向一种概率分布:苹果为红色,小猪为白色
- 随机变量:可以理解为指向某个事件的一个变量:\(X\{x_i = \text{黄色}\}\)
- 随机变量的概率分布:给定随机变量的取值范围,导致某种随机事件出现的可能性。可以理解为符合随机变量取值范围的某个对象属于某个类别或服从某种趋势的可能性。
空间变换
由特征列的取值所构成的矩阵空间应具有完整性,即能够反映事物的空间形式或变换规律。
向量:具有大小和方向。
向量与矩阵的乘积就是一个向量从一个线性空间(坐标系),通过线性变换,选取一个新的基底,变换到这个新的基底所构成的另一个线性空间的过程。
矩阵与矩阵的乘法 \(C = A \cdot B\):
- \(A\):向量组
- \(B\):线性变换下的矩阵
假设我们考察一组对象 \(\scr{A} = \{\alpha_1, \cdots, \alpha_m\}\),它们在两个不同维度的空间 \(V^n\) 和 \(V^p\) 的基底分别是 \(\{\vec{e_1}, \cdots, \vec{e_n}\}\) 和 \(\{\vec{d_1}, \cdots, \vec{d_p}\}\),\(T\) 即为 \(V^n\) 到 \(V^p\) 的线性变换,且有(\(k = \{1, \cdots, m\}\)):
令
则记:
由式(1)可知:
因而 \(X\) 与 \(Y\) 表示一组对象在不同的线性空间的坐标表示。\(A\) 表示线性变换在某个基偶(如,\((\{\vec{e_1}, \cdots, \vec{e_n}\}, \{\vec{d_1}, \cdots, \vec{d_p}\})\))下的矩阵表示。
使用 Numpy 求解矩阵的特征值和特征向量
A = [[8, 7, 6], [3, 5, 7], [4, 9, 1]]
evals, evecs = np.linalg.eig(A)
print('特征值:\n%s\n特征向量:\n%s'%(evals, evecs))
特征值:
[ 16.43231925 2.84713925 -5.2794585 ]
特征向量:
[[ 0.73717284 0.86836047 -0.09167612]
[ 0.48286213 -0.4348687 -0.54207062]
[ 0.47267364 -0.23840995 0.83531726]]
有了特征值和特征向量,我们便可以还原矩阵:
sigma = evals * np.eye(3)
sigma
array([[ 16.43231925, 0. , -0. ],
[ 0. , 2.84713925, -0. ],
[ 0. , 0. , -5.2794585 ]])
或者,利用 np.diag:
np.diag(evals)
array([[ 16.43231925, 0. , 0. ],
[ 0. , 2.84713925, 0. ],
[ 0. , 0. , -5.2794585 ]])
np.dot(np.dot(evecs, sigma), np.linalg.inv(evecs))
array([[ 8., 7., 6.],
[ 3., 5., 7.],
[ 4., 9., 1.]])
我的学习笔记:ML 基础
我的Github:https://github.com/q735613050/AI/tree/master/ML
关于矩阵的一个不成熟的解释: 机器学习中的矩阵

 浙公网安备 33010602011771号
浙公网安备 33010602011771号